 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePensieve Grader: An AI-Powered, Ready-to-Use Platform for Effortless Handwritten STEM Grading
Jul 02, 2025Grading handwritten, open-ended responses remains a major bottleneck in large university STEM courses. We introduce Pensieve (https://www.pensieve.co), an AI-assisted grading platform that leverages large language models (LLMs) to transcribe and evaluate student work, providing instructors with rubric-aligned scores, transcriptions, and confidence ratings. Unlike prior tools that focus narrowly on specific tasks like transcription or rubric generation, Pensieve supports the entire grading pipeline-from scanned student submissions to final feedback-within a human-in-the-loop interface. Pensieve has been deployed in real-world courses at over 20 institutions and has graded more than 300,000 student responses. We present system details and empirical results across four core STEM disciplines: Computer Science, Mathematics, Physics, and Chemistry. Our findings show that Pensieve reduces grading time by an average of 65%, while maintaining a 95.4% agreement rate with instructor-assigned grades for high-confidence predictions.
kNN-SVC: Robust Zero-Shot Singing Voice Conversion with Additive Synthesis and Concatenation Smoothness Optimization
Apr 08, 2025



Robustness is critical in zero-shot singing voice conversion (SVC). This paper introduces two novel methods to strengthen the robustness of the kNN-VC framework for SVC. First, kNN-VC's core representation, WavLM, lacks harmonic emphasis, resulting in dull sounds and ringing artifacts. To address this, we leverage the bijection between WavLM, pitch contours, and spectrograms to perform additive synthesis, integrating the resulting waveform into the model to mitigate these issues. Second, kNN-VC overlooks concatenative smoothness, a key perceptual factor in SVC. To enhance smoothness, we propose a new distance metric that filters out unsuitable kNN candidates and optimize the summing weights of the candidates during inference. Although our techniques are built on the kNN-VC framework for implementation convenience, they are broadly applicable to general concatenative neural synthesis models. Experimental results validate the effectiveness of these modifications in achieving robust SVC. Demo: http://knnsvc.com Code: https://github.com/SmoothKen/knn-svc
Interpreting Graphic Notation with MusicLDM: An AI Improvisation of Cornelius Cardew's Treatise
Dec 12, 2024
This work presents a novel method for composing and improvising music inspired by Cornelius Cardew's Treatise, using AI to bridge graphic notation and musical expression. By leveraging OpenAI's ChatGPT to interpret the abstract visual elements of Treatise, we convert these graphical images into descriptive textual prompts. These prompts are then input into MusicLDM, a pre-trained latent diffusion model designed for music generation. We introduce a technique called "outpainting," which overlaps sections of AI-generated music to create a seamless and cohesive composition. We demostrate a new perspective on performing and interpreting graphic scores, showing how AI can transform visual stimuli into sound and expand the creative possibilities in contemporary/experimental music composition. Musical pieces are available at https://bit.ly/TreatiseAI
Music Enhancement with Deep Filters: A Technical Report for The ICASSP 2024 Cadenza Challenge
Apr 17, 2024In this challenge, we disentangle the deep filters from the original DeepfilterNet and incorporate them into our Spec-UNet-based network to further improve a hybrid Demucs (hdemucs) based remixing pipeline. The motivation behind the use of the deep filter component lies at its potential in better handling temporal fine structures. We demonstrate an incremental improvement in both the Signal-to-Distortion Ratio (SDR) and the Hearing Aid Audio Quality Index (HAAQI) metrics when comparing the performance of hdemucs against different versions of our model.
Towards Improving Harmonic Sensitivity and Prediction Stability for Singing Melody Extraction
Aug 04, 2023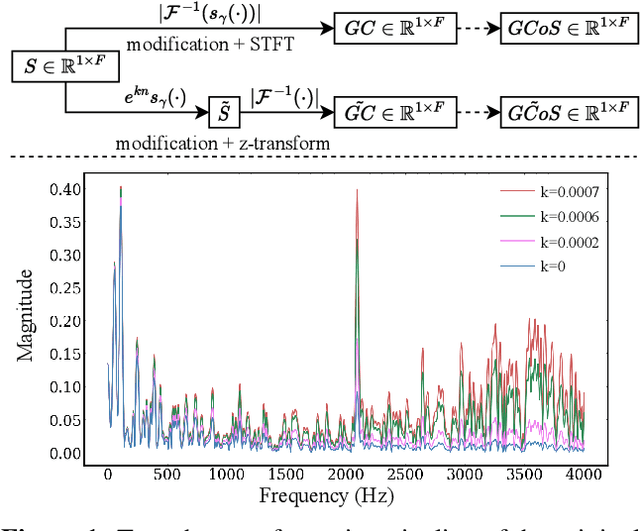
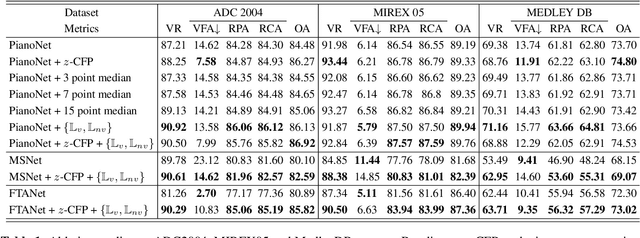
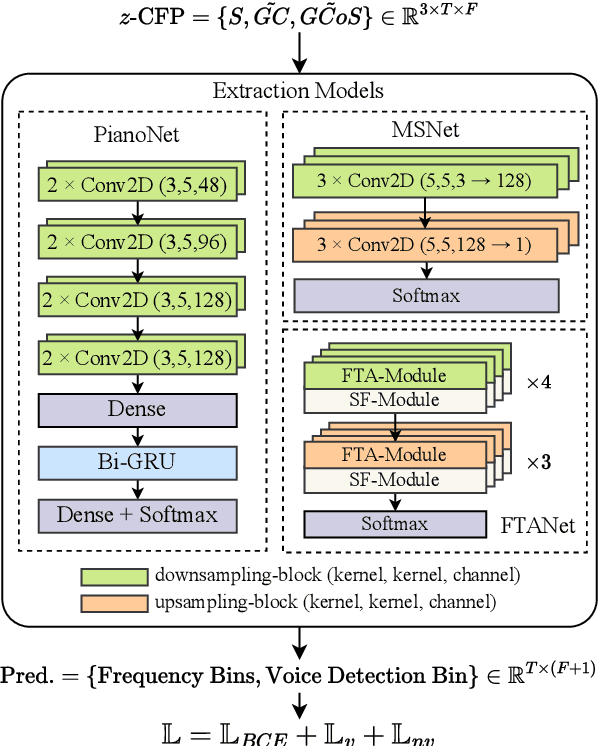
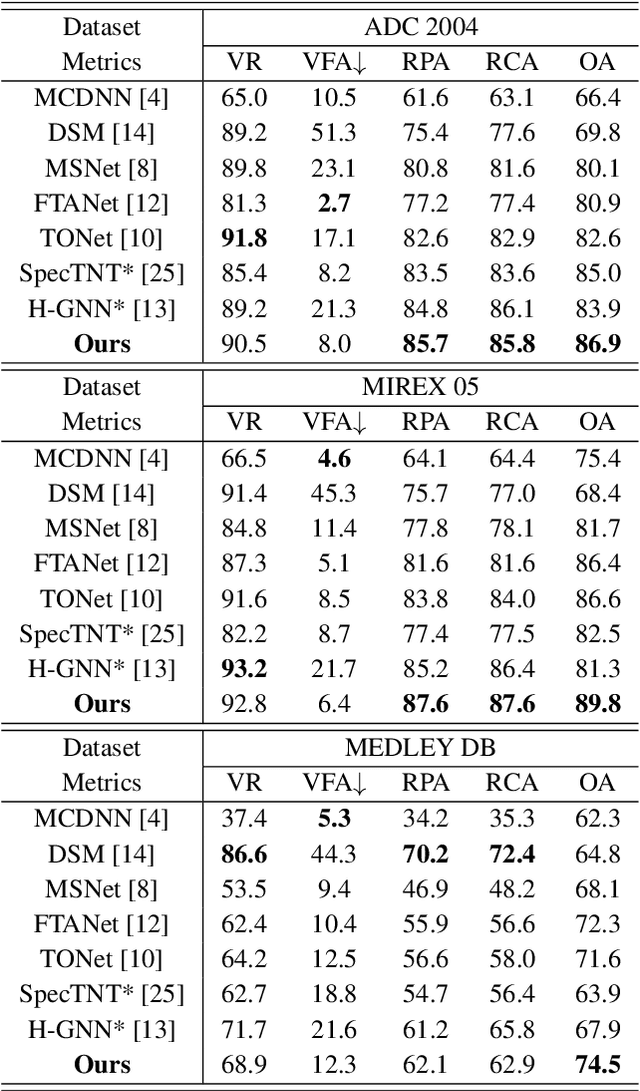
In deep learning research, many melody extraction models rely on redesigning neural network architectures to improve performance. In this paper, we propose an input feature modification and a training objective modification based on two assumptions. First, harmonics in the spectrograms of audio data decay rapidly along the frequency axis. To enhance the model's sensitivity on the trailing harmonics, we modify the Combined Frequency and Periodicity (CFP) representation using discrete z-transform. Second, the vocal and non-vocal segments with extremely short duration are uncommon. To ensure a more stable melody contour, we design a differentiable loss function that prevents the model from predicting such segments. We apply these modifications to several models, including MSNet, FTANet, and a newly introduced model, PianoNet, modified from a piano transcription network. Our experimental results demonstrate that the proposed modifications are empirically effective for singing melody extraction.