 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgekNN-SVC: Robust Zero-Shot Singing Voice Conversion with Additive Synthesis and Concatenation Smoothness Optimization
Apr 08, 2025



Robustness is critical in zero-shot singing voice conversion (SVC). This paper introduces two novel methods to strengthen the robustness of the kNN-VC framework for SVC. First, kNN-VC's core representation, WavLM, lacks harmonic emphasis, resulting in dull sounds and ringing artifacts. To address this, we leverage the bijection between WavLM, pitch contours, and spectrograms to perform additive synthesis, integrating the resulting waveform into the model to mitigate these issues. Second, kNN-VC overlooks concatenative smoothness, a key perceptual factor in SVC. To enhance smoothness, we propose a new distance metric that filters out unsuitable kNN candidates and optimize the summing weights of the candidates during inference. Although our techniques are built on the kNN-VC framework for implementation convenience, they are broadly applicable to general concatenative neural synthesis models. Experimental results validate the effectiveness of these modifications in achieving robust SVC. Demo: http://knnsvc.com Code: https://github.com/SmoothKen/knn-svc
Deriving Representative Structure from Music Corpora
Feb 21, 2025Western music is an innately hierarchical system of interacting levels of structure, from fine-grained melody to high-level form. In order to analyze music compositions holistically and at multiple granularities, we propose a unified, hierarchical meta-representation of musical structure called the structural temporal graph (STG). For a single piece, the STG is a data structure that defines a hierarchy of progressively finer structural musical features and the temporal relationships between them. We use the STG to enable a novel approach for deriving a representative structural summary of a music corpus, which we formalize as a dually NP-hard combinatorial optimization problem extending the Generalized Median Graph problem. Our approach first applies simulated annealing to develop a measure of structural distance between two music pieces rooted in graph isomorphism. Our approach then combines the formal guarantees of SMT solvers with nested simulated annealing over structural distances to produce a structurally sound, representative centroid STG for an entire corpus of STGs from individual pieces. To evaluate our approach, we conduct experiments verifying that structural distance accurately differentiates between music pieces, and that derived centroids accurately structurally characterize their corpora.
Interpreting Graphic Notation with MusicLDM: An AI Improvisation of Cornelius Cardew's Treatise
Dec 12, 2024
This work presents a novel method for composing and improvising music inspired by Cornelius Cardew's Treatise, using AI to bridge graphic notation and musical expression. By leveraging OpenAI's ChatGPT to interpret the abstract visual elements of Treatise, we convert these graphical images into descriptive textual prompts. These prompts are then input into MusicLDM, a pre-trained latent diffusion model designed for music generation. We introduce a technique called "outpainting," which overlaps sections of AI-generated music to create a seamless and cohesive composition. We demostrate a new perspective on performing and interpreting graphic scores, showing how AI can transform visual stimuli into sound and expand the creative possibilities in contemporary/experimental music composition. Musical pieces are available at https://bit.ly/TreatiseAI
Generating Symbolic Music from Natural Language Prompts using an LLM-Enhanced Dataset
Oct 02, 2024



Recent years have seen many audio-domain text-to-music generation models that rely on large amounts of text-audio pairs for training. However, symbolic-domain controllable music generation has lagged behind partly due to the lack of a large-scale symbolic music dataset with extensive metadata and captions. In this work, we present MetaScore, a new dataset consisting of 963K musical scores paired with rich metadata, including free-form user-annotated tags, collected from an online music forum. To approach text-to-music generation, we leverage a pretrained large language model (LLM) to generate pseudo natural language captions from the metadata. With the LLM-enhanced MetaScore, we train a text-conditioned music generation model that learns to generate symbolic music from the pseudo captions, allowing control of instruments, genre, composer, complexity and other free-form music descriptors. In addition, we train a tag-conditioned system that supports a predefined set of tags available in MetaScore. Our experimental results show that both the proposed text-to-music and tags-to-music models outperform a baseline text-to-music model in a listening test, while the text-based system offers a more natural interface that allows free-form natural language prompts.
Creativity and Visual Communication from Machine to Musician: Sharing a Score through a Robotic Camera
Sep 09, 2024



This paper explores the integration of visual communication and musical interaction by implementing a robotic camera within a "Guided Harmony" musical game. We aim to examine co-creative behaviors between human musicians and robotic systems. Our research explores existing methodologies like improvisational game pieces and extends these concepts to include robotic participation using a PTZ camera. The robotic system interprets and responds to nonverbal cues from musicians, creating a collaborative and adaptive musical experience. This initial case study underscores the importance of intuitive visual communication channels. We also propose future research directions, including parameters for refining the visual cue toolkit and data collection methods to understand human-machine co-creativity further. Our findings contribute to the broader understanding of machine intelligence in augmenting human creativity, particularly in musical settings.
Multi-Track MusicLDM: Towards Versatile Music Generation with Latent Diffusion Model
Sep 04, 2024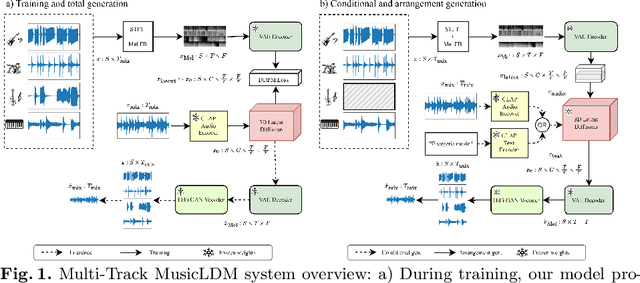


Diffusion models have shown promising results in cross-modal generation tasks involving audio and music, such as text-to-sound and text-to-music generation. These text-controlled music generation models typically focus on generating music by capturing global musical attributes like genre and mood. However, music composition is a complex, multilayered task that often involves musical arrangement as an integral part of the process. This process involves composing each instrument to align with existing ones in terms of beat, dynamics, harmony, and melody, requiring greater precision and control over tracks than text prompts usually provide. In this work, we address these challenges by extending the MusicLDM, a latent diffusion model for music, into a multi-track generative model. By learning the joint probability of tracks sharing a context, our model is capable of generating music across several tracks that correspond well to each other, either conditionally or unconditionally. Additionally, our model is capable of arrangement generation, where the model can generate any subset of tracks given the others (e.g., generating a piano track complementing given bass and drum tracks). We compared our model with an existing multi-track generative model and demonstrated that our model achieves considerable improvements across objective metrics for both total and arrangement generation tasks.
Improving Generalization of Speech Separation in Real-World Scenarios: Strategies in Simulation, Optimization, and Evaluation
Aug 28, 2024



Achieving robust speech separation for overlapping speakers in various acoustic environments with noise and reverberation remains an open challenge. Although existing datasets are available to train separators for specific scenarios, they do not effectively generalize across diverse real-world scenarios. In this paper, we present a novel data simulation pipeline that produces diverse training data from a range of acoustic environments and content, and propose new training paradigms to improve quality of a general speech separation model. Specifically, we first introduce AC-SIM, a data simulation pipeline that incorporates broad variations in both content and acoustics. Then we integrate multiple training objectives into the permutation invariant training (PIT) to enhance separation quality and generalization of the trained model. Finally, we conduct comprehensive objective and human listening experiments across separation architectures and benchmarks to validate our methods, demonstrating substantial improvement of generalization on both non-homologous and real-world test sets.
Music Enhancement with Deep Filters: A Technical Report for The ICASSP 2024 Cadenza Challenge
Apr 17, 2024In this challenge, we disentangle the deep filters from the original DeepfilterNet and incorporate them into our Spec-UNet-based network to further improve a hybrid Demucs (hdemucs) based remixing pipeline. The motivation behind the use of the deep filter component lies at its potential in better handling temporal fine structures. We demonstrate an incremental improvement in both the Signal-to-Distortion Ratio (SDR) and the Hearing Aid Audio Quality Index (HAAQI) metrics when comparing the performance of hdemucs against different versions of our model.
Evaluating Co-Creativity using Total Information Flow
Feb 09, 2024



Co-creativity in music refers to two or more musicians or musical agents interacting with one another by composing or improvising music. However, this is a very subjective process and each musician has their own preference as to which improvisation is better for some context. In this paper, we aim to create a measure based on total information flow to quantitatively evaluate the co-creativity process in music. In other words, our measure is an indication of how "good" a creative musical process is. Our main hypothesis is that a good musical creation would maximize information flow between the participants captured by music voices recorded in separate tracks. We propose a method to compute the information flow using pre-trained generative models as entropy estimators. We demonstrate how our method matches with human perception using a qualitative study.
Binaural sound source localization using a hybrid time and frequency domain model
Feb 06, 2024



This paper introduces a new approach to sound source localization using head-related transfer function (HRTF) characteristics, which enable precise full-sphere localization from raw data. While previous research focused primarily on using extensive microphone arrays in the frontal plane, this arrangement often encountered limitations in accuracy and robustness when dealing with smaller microphone arrays. Our model proposes using both time and frequency domain for sound source localization while utilizing Deep Learning (DL) approach. The performance of our proposed model, surpasses the current state-of-the-art results. Specifically, it boasts an average angular error of $0.24 degrees and an average Euclidean distance of 0.01 meters, while the known state-of-the-art gives average angular error of 19.07 degrees and average Euclidean distance of 1.08 meters. This level of accuracy is of paramount importance for a wide range of applications, including robotics, virtual reality, and aiding individuals with cochlear implants (CI).