 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchrodinger Audio-Visual Editor: Object-Level Audiovisual Removal
Dec 14, 2025Joint editing of audio and visual content is crucial for precise and controllable content creation. This new task poses challenges due to the limitations of paired audio-visual data before and after targeted edits, and the heterogeneity across modalities. To address the data and modeling challenges in joint audio-visual editing, we introduce SAVEBench, a paired audiovisual dataset with text and mask conditions to enable object-grounded source-to-target learning. With SAVEBench, we train the Schrodinger Audio-Visual Editor (SAVE), an end-to-end flow-matching model that edits audio and video in parallel while keeping them aligned throughout processing. SAVE incorporates a Schrodinger Bridge that learns a direct transport from source to target audiovisual mixtures. Our evaluation demonstrates that the proposed SAVE model is able to remove the target objects in audio and visual content while preserving the remaining content, with stronger temporal synchronization and audiovisual semantic correspondence compared with pairwise combinations of an audio editor and a video editor.
Video-Guided Text-to-Music Generation Using Public Domain Movie Collections
Jun 14, 2025Despite recent advancements in music generation systems, their application in film production remains limited, as they struggle to capture the nuances of real-world filmmaking, where filmmakers consider multiple factors-such as visual content, dialogue, and emotional tone-when selecting or composing music for a scene. This limitation primarily stems from the absence of comprehensive datasets that integrate these elements. To address this gap, we introduce Open Screen Sound Library (OSSL), a dataset consisting of movie clips from public domain films, totaling approximately 36.5 hours, paired with high-quality soundtracks and human-annotated mood information. To demonstrate the effectiveness of our dataset in improving the performance of pre-trained models on film music generation tasks, we introduce a new video adapter that enhances an autoregressive transformer-based text-to-music model by adding video-based conditioning. Our experimental results demonstrate that our proposed approach effectively enhances MusicGen-Medium in terms of both objective measures of distributional and paired fidelity, and subjective compatibility in mood and genre. The dataset and code are available at https://havenpersona.github.io/ossl-v1.
REGen: Multimodal Retrieval-Embedded Generation for Long-to-Short Video Editing
May 24, 2025Short videos are an effective tool for promoting contents and improving knowledge accessibility. While existing extractive video summarization methods struggle to produce a coherent narrative, existing abstractive methods cannot `quote' from the input videos, i.e., inserting short video clips in their outputs. In this work, we explore novel video editing models for generating shorts that feature a coherent narrative with embedded video insertions extracted from a long input video. We propose a novel retrieval-embedded generation framework that allows a large language model to quote multimodal resources while maintaining a coherent narrative. Our proposed REGen system first generates the output story script with quote placeholders using a finetuned large language model, and then uses a novel retrieval model to replace the quote placeholders by selecting a video clip that best supports the narrative from a pool of candidate quotable video clips. We examine the proposed method on the task of documentary teaser generation, where short interview insertions are commonly used to support the narrative of a documentary. Our objective evaluations show that the proposed method can effectively insert short video clips while maintaining a coherent narrative. In a subjective survey, we show that our proposed method outperforms existing abstractive and extractive approaches in terms of coherence, alignment, and realism in teaser generation.
Recurrent Neural Network on PICTURE Model
Dec 02, 2024Intensive Care Units (ICUs) provide critical care and life support for most severely ill and injured patients in the hospital. With the need for ICUs growing rapidly and unprecedentedly, especially during COVID-19, accurately identifying the most critical patients helps hospitals to allocate resources more efficiently and save more lives. The Predicting Intensive Care Transfers and Other Unforeseen Events (PICTURE) model predicts patient deterioration by separating those at high risk for imminent intensive care unit transfer, respiratory failure, or death from those at lower risk. This study aims to implement a deep learning model to benchmark the performance from the XGBoost model, an existing model which has competitive results on prediction.
TeaserGen: Generating Teasers for Long Documentaries
Oct 08, 2024

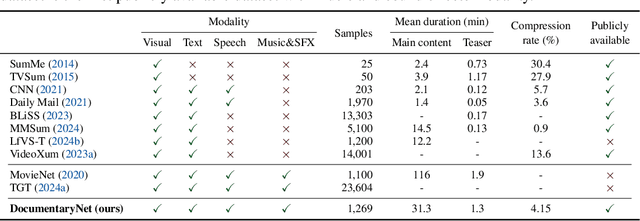
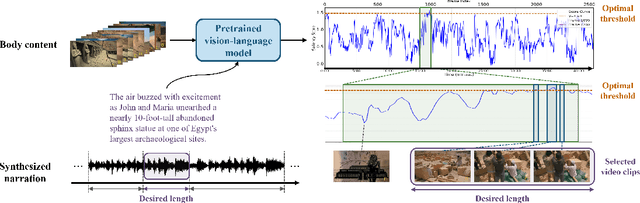
Teasers are an effective tool for promoting content in entertainment, commercial and educational fields. However, creating an effective teaser for long videos is challenging for it requires long-range multimodal modeling on the input videos, while necessitating maintaining audiovisual alignments, managing scene changes and preserving factual accuracy for the output teasers. Due to the lack of a publicly-available dataset, progress along this research direction has been hindered. In this work, we present DocumentaryNet, a collection of 1,269 documentaries paired with their teasers, featuring multimodal data streams of video, speech, music, sound effects and narrations. With DocumentaryNet, we propose a new two-stage system for generating teasers from long documentaries. The proposed TeaserGen system first generates the teaser narration from the transcribed narration of the documentary using a pretrained large language model, and then selects the most relevant visual content to accompany the generated narration through language-vision models. For narration-video matching, we explore two approaches: a pretraining-based model using pretrained contrastive language-vision models and a deep sequential model that learns the mapping between the narrations and visuals. Our experimental results show that the pretraining-based approach is more effective at identifying relevant visual content than directly trained deep autoregressive models.
Generating Symbolic Music from Natural Language Prompts using an LLM-Enhanced Dataset
Oct 02, 2024



Recent years have seen many audio-domain text-to-music generation models that rely on large amounts of text-audio pairs for training. However, symbolic-domain controllable music generation has lagged behind partly due to the lack of a large-scale symbolic music dataset with extensive metadata and captions. In this work, we present MetaScore, a new dataset consisting of 963K musical scores paired with rich metadata, including free-form user-annotated tags, collected from an online music forum. To approach text-to-music generation, we leverage a pretrained large language model (LLM) to generate pseudo natural language captions from the metadata. With the LLM-enhanced MetaScore, we train a text-conditioned music generation model that learns to generate symbolic music from the pseudo captions, allowing control of instruments, genre, composer, complexity and other free-form music descriptors. In addition, we train a tag-conditioned system that supports a predefined set of tags available in MetaScore. Our experimental results show that both the proposed text-to-music and tags-to-music models outperform a baseline text-to-music model in a listening test, while the text-based system offers a more natural interface that allows free-form natural language prompts.
A New Dataset, Notation Software, and Representation for Computational Schenkerian Analysis
Aug 13, 2024Schenkerian Analysis (SchA) is a uniquely expressive method of music analysis, combining elements of melody, harmony, counterpoint, and form to describe the hierarchical structure supporting a work of music. However, despite its powerful analytical utility and potential to improve music understanding and generation, SchA has rarely been utilized by the computer music community. This is in large part due to the paucity of available high-quality data in a computer-readable format. With a larger corpus of Schenkerian data, it may be possible to infuse machine learning models with a deeper understanding of musical structure, thus leading to more "human" results. To encourage further research in Schenkerian analysis and its potential benefits for music informatics and generation, this paper presents three main contributions: 1) a new and growing dataset of SchAs, the largest in human- and computer-readable formats to date (>140 excerpts), 2) a novel software for visualization and collection of SchA data, and 3) a novel, flexible representation of SchA as a heterogeneous-edge graph data structure.
Equipping Pretrained Unconditional Music Transformers with Instrument and Genre Controls
Nov 21, 2023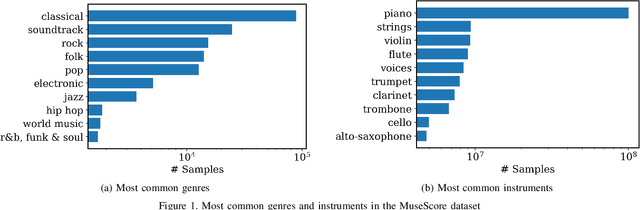
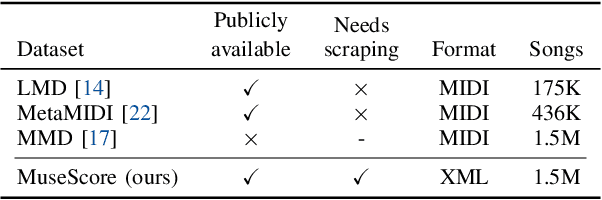

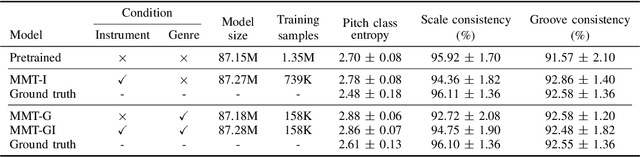
The ''pretraining-and-finetuning'' paradigm has become a norm for training domain-specific models in natural language processing and computer vision. In this work, we aim to examine this paradigm for symbolic music generation through leveraging the largest ever symbolic music dataset sourced from the MuseScore forum. We first pretrain a large unconditional transformer model using 1.5 million songs. We then propose a simple technique to equip this pretrained unconditional music transformer model with instrument and genre controls by finetuning the model with additional control tokens. Our proposed representation offers improved high-level controllability and expressiveness against two existing representations. The experimental results show that the proposed model can successfully generate music with user-specified instruments and genre. In a subjective listening test, the proposed model outperforms the pretrained baseline model in terms of coherence, harmony, arrangement and overall quality.