 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusID: Modality-Fused Semantic IDs for Generative Music Recommendation
Jan 13, 2026Generative recommendation systems have achieved significant advances by leveraging semantic IDs to represent items. However, existing approaches that tokenize each modality independently face two critical limitations: (1) redundancy across modalities that reduces efficiency, and (2) failure to capture inter-modal interactions that limits item representation. We introduce FusID, a modality-fused semantic ID framework that addresses these limitations through three key components: (i) multimodal fusion that learns unified representations by jointly encoding information across modalities, (ii) representation learning that brings frequently co-occurring item embeddings closer while maintaining distinctiveness and preventing feature redundancy, and (iii) product quantization that converts the fused continuous embeddings into multiple discrete tokens to mitigate ID conflict. Evaluated on a multimodal next-song recommendation (i.e., playlist continuation) benchmark, FusID achieves zero ID conflicts, ensuring that each token sequence maps to exactly one song, mitigates codebook underutilization, and outperforms baselines in terms of MRR and Recall@k (k = 1, 5, 10, 20).
Video-Guided Text-to-Music Generation Using Public Domain Movie Collections
Jun 14, 2025Despite recent advancements in music generation systems, their application in film production remains limited, as they struggle to capture the nuances of real-world filmmaking, where filmmakers consider multiple factors-such as visual content, dialogue, and emotional tone-when selecting or composing music for a scene. This limitation primarily stems from the absence of comprehensive datasets that integrate these elements. To address this gap, we introduce Open Screen Sound Library (OSSL), a dataset consisting of movie clips from public domain films, totaling approximately 36.5 hours, paired with high-quality soundtracks and human-annotated mood information. To demonstrate the effectiveness of our dataset in improving the performance of pre-trained models on film music generation tasks, we introduce a new video adapter that enhances an autoregressive transformer-based text-to-music model by adding video-based conditioning. Our experimental results demonstrate that our proposed approach effectively enhances MusicGen-Medium in terms of both objective measures of distributional and paired fidelity, and subjective compatibility in mood and genre. The dataset and code are available at https://havenpersona.github.io/ossl-v1.
TeaserGen: Generating Teasers for Long Documentaries
Oct 08, 2024

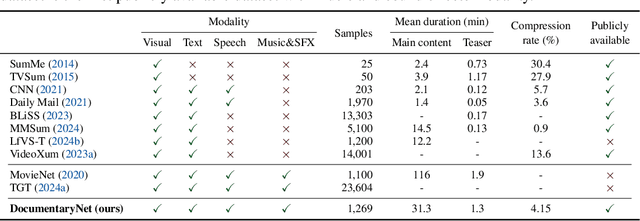
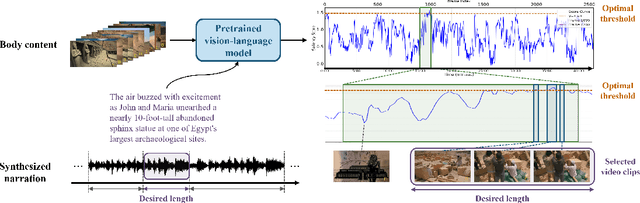
Teasers are an effective tool for promoting content in entertainment, commercial and educational fields. However, creating an effective teaser for long videos is challenging for it requires long-range multimodal modeling on the input videos, while necessitating maintaining audiovisual alignments, managing scene changes and preserving factual accuracy for the output teasers. Due to the lack of a publicly-available dataset, progress along this research direction has been hindered. In this work, we present DocumentaryNet, a collection of 1,269 documentaries paired with their teasers, featuring multimodal data streams of video, speech, music, sound effects and narrations. With DocumentaryNet, we propose a new two-stage system for generating teasers from long documentaries. The proposed TeaserGen system first generates the teaser narration from the transcribed narration of the documentary using a pretrained large language model, and then selects the most relevant visual content to accompany the generated narration through language-vision models. For narration-video matching, we explore two approaches: a pretraining-based model using pretrained contrastive language-vision models and a deep sequential model that learns the mapping between the narrations and visuals. Our experimental results show that the pretraining-based approach is more effective at identifying relevant visual content than directly trained deep autoregressive models.
LyCon: Lyrics Reconstruction from the Bag-of-Words Using Large Language Models
Aug 27, 2024This paper addresses the unique challenge of conducting research in lyric studies, where direct use of lyrics is often restricted due to copyright concerns. Unlike typical data, internet-sourced lyrics are frequently protected under copyright law, necessitating alternative approaches. Our study introduces a novel method for generating copyright-free lyrics from publicly available Bag-of-Words (BoW) datasets, which contain the vocabulary of lyrics but not the lyrics themselves. Utilizing metadata associated with BoW datasets and large language models, we successfully reconstructed lyrics. We have compiled and made available a dataset of reconstructed lyrics, LyCon, aligned with metadata from renowned sources including the Million Song Dataset, Deezer Mood Detection Dataset, and AllMusic Genre Dataset, available for public access. We believe that the integration of metadata such as mood annotations or genres enables a variety of academic experiments on lyrics, such as conditional lyric generation.
Audio Prompt Adapter: Unleashing Music Editing Abilities for Text-to-Music with Lightweight Finetuning
Jul 24, 2024



Text-to-music models allow users to generate nearly realistic musical audio with textual commands. However, editing music audios remains challenging due to the conflicting desiderata of performing fine-grained alterations on the audio while maintaining a simple user interface. To address this challenge, we propose Audio Prompt Adapter (or AP-Adapter), a lightweight addition to pretrained text-to-music models. We utilize AudioMAE to extract features from the input audio, and construct attention-based adapters to feedthese features into the internal layers of AudioLDM2, a diffusion-based text-to-music model. With 22M trainable parameters, AP-Adapter empowers users to harness both global (e.g., genre and timbre) and local (e.g., melody) aspects of music, using the original audio and a short text as inputs. Through objective and subjective studies, we evaluate AP-Adapter on three tasks: timbre transfer, genre transfer, and accompaniment generation. Additionally, we demonstrate its effectiveness on out-of-domain audios containing unseen instruments during training.
A Computational Analysis of Lyric Similarity Perception
Apr 02, 2024In musical compositions that include vocals, lyrics significantly contribute to artistic expression. Consequently, previous studies have introduced the concept of a recommendation system that suggests lyrics similar to a user's favorites or personalized preferences, aiding in the discovery of lyrics among millions of tracks. However, many of these systems do not fully consider human perceptions of lyric similarity, primarily due to limited research in this area. To bridge this gap, we conducted a comparative analysis of computational methods for modeling lyric similarity with human perception. Results indicated that computational models based on similarities between embeddings from pre-trained BERT-based models, the audio from which the lyrics are derived, and phonetic components are indicative of perceptual lyric similarity. This finding underscores the importance of semantic, stylistic, and phonetic similarities in human perception about lyric similarity. We anticipate that our findings will enhance the development of similarity-based lyric recommendation systems by offering pseudo-labels for neural network development and introducing objective evaluation metrics.
K-pop Lyric Translation: Dataset, Analysis, and Neural-Modelling
Sep 20, 2023

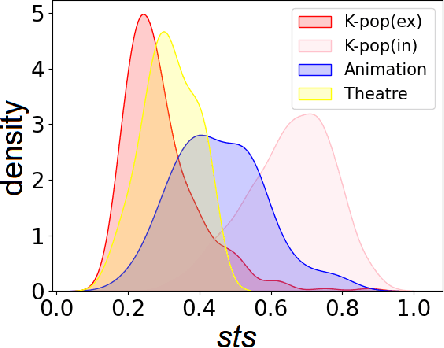
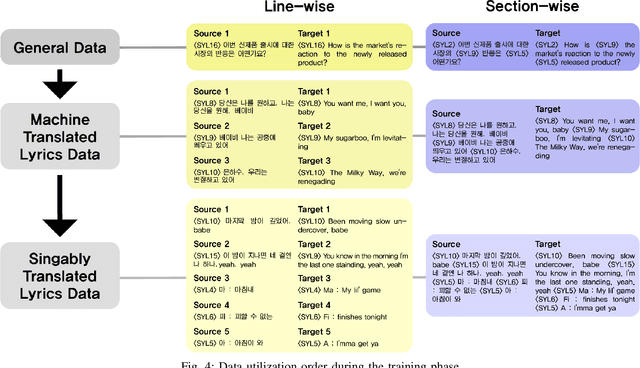
Lyric translation, a field studied for over a century, is now attracting computational linguistics researchers. We identified two limitations in previous studies. Firstly, lyric translation studies have predominantly focused on Western genres and languages, with no previous study centering on K-pop despite its popularity. Second, the field of lyric translation suffers from a lack of publicly available datasets; to the best of our knowledge, no such dataset exists. To broaden the scope of genres and languages in lyric translation studies, we introduce a novel singable lyric translation dataset, approximately 89\% of which consists of K-pop song lyrics. This dataset aligns Korean and English lyrics line-by-line and section-by-section. We leveraged this dataset to unveil unique characteristics of K-pop lyric translation, distinguishing it from other extensively studied genres, and to construct a neural lyric translation model, thereby underscoring the importance of a dedicated dataset for singable lyric translations.
The Biased Journey of MSD_AUDIO.ZIP
Sep 02, 2023The equitable distribution of academic data is crucial for ensuring equal research opportunities, and ultimately further progress. Yet, due to the complexity of using the API for audio data that corresponds to the Million Song Dataset along with its misreporting (before 2016) and the discontinuation of this API (after 2016), access to this data has become restricted to those within certain affiliations that are connected peer-to-peer. In this paper, we delve into this issue, drawing insights from the experiences of 22 individuals who either attempted to access the data or played a role in its creation. With this, we hope to initiate more critical dialogue and more thoughtful consideration with regard to access privilege in the MIR community.
A Computational Evaluation Framework for Singable Lyric Translation
Aug 26, 2023



Lyric translation plays a pivotal role in amplifying the global resonance of music, bridging cultural divides, and fostering universal connections. Translating lyrics, unlike conventional translation tasks, requires a delicate balance between singability and semantics. In this paper, we present a computational framework for the quantitative evaluation of singable lyric translation, which seamlessly integrates musical, linguistic, and cultural dimensions of lyrics. Our comprehensive framework consists of four metrics that measure syllable count distance, phoneme repetition similarity, musical structure distance, and semantic similarity. To substantiate the efficacy of our framework, we collected a singable lyrics dataset, which precisely aligns English, Japanese, and Korean lyrics on a line-by-line and section-by-section basis, and conducted a comparative analysis between singable and non-singable lyrics. Our multidisciplinary approach provides insights into the key components that underlie the art of lyric translation and establishes a solid groundwork for the future of computational lyric translation assessment.
Music Playlist Title Generation Using Artist Information
Jan 14, 2023Automatically generating or captioning music playlist titles given a set of tracks is of significant interest in music streaming services as customized playlists are widely used in personalized music recommendation, and well-composed text titles attract users and help their music discovery. We present an encoder-decoder model that generates a playlist title from a sequence of music tracks. While previous work takes track IDs as tokenized input for playlist title generation, we use artist IDs corresponding to the tracks to mitigate the issue from the long-tail distribution of tracks included in the playlist dataset. Also, we introduce a chronological data split method to deal with newly-released tracks in real-world scenarios. Comparing the track IDs and artist IDs as input sequences, we show that the artist-based approach significantly enhances the performance in terms of word overlap, semantic relevance, and diversity.