 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferring trust in recommendation systems from brain, behavioural, and physiological data
Oct 31, 2025As people nowadays increasingly rely on artificial intelligence (AI) to curate information and make decisions, assigning the appropriate amount of trust in automated intelligent systems has become ever more important. However, current measurements of trust in automation still largely rely on self-reports that are subjective and disruptive to the user. Here, we take music recommendation as a model to investigate the neural and cognitive processes underlying trust in automation. We observed that system accuracy was directly related to users' trust and modulated the influence of recommendation cues on music preference. Modelling users' reward encoding process with a reinforcement learning model further revealed that system accuracy, expected reward, and prediction error were related to oscillatory neural activity recorded via EEG and changes in pupil diameter. Our results provide a neurally grounded account of calibrating trust in automation and highlight the promises of a multimodal approach towards developing trustable AI systems.
Constrained Preferential Bayesian Optimization and Its Application in Banner Ad Design
May 16, 2025Preferential Bayesian optimization (PBO) is a variant of Bayesian optimization that observes relative preferences (e.g., pairwise comparisons) instead of direct objective values, making it especially suitable for human-in-the-loop scenarios. However, real-world optimization tasks often involve inequality constraints, which existing PBO methods have not yet addressed. To fill this gap, we propose constrained preferential Bayesian optimization (CPBO), an extension of PBO that incorporates inequality constraints for the first time. Specifically, we present a novel acquisition function for this purpose. Our technical evaluation shows that our CPBO method successfully identifies optimal solutions by focusing on exploring feasible regions. As a practical application, we also present a designer-in-the-loop system for banner ad design using CPBO, where the objective is the designer's subjective preference, and the constraint ensures a target predicted click-through rate. We conducted a user study with professional ad designers, demonstrating the potential benefits of our approach in guiding creative design under real-world constraints.
* 17 pages, 15 figures
A Computational Evaluation Framework for Singable Lyric Translation
Aug 26, 2023



Lyric translation plays a pivotal role in amplifying the global resonance of music, bridging cultural divides, and fostering universal connections. Translating lyrics, unlike conventional translation tasks, requires a delicate balance between singability and semantics. In this paper, we present a computational framework for the quantitative evaluation of singable lyric translation, which seamlessly integrates musical, linguistic, and cultural dimensions of lyrics. Our comprehensive framework consists of four metrics that measure syllable count distance, phoneme repetition similarity, musical structure distance, and semantic similarity. To substantiate the efficacy of our framework, we collected a singable lyrics dataset, which precisely aligns English, Japanese, and Korean lyrics on a line-by-line and section-by-section basis, and conducted a comparative analysis between singable and non-singable lyrics. Our multidisciplinary approach provides insights into the key components that underlie the art of lyric translation and establishes a solid groundwork for the future of computational lyric translation assessment.
IteraTTA: An interface for exploring both text prompts and audio priors in generating music with text-to-audio models
Jul 24, 2023Recent text-to-audio generation techniques have the potential to allow novice users to freely generate music audio. Even if they do not have musical knowledge, such as about chord progressions and instruments, users can try various text prompts to generate audio. However, compared to the image domain, gaining a clear understanding of the space of possible music audios is difficult because users cannot listen to the variations of the generated audios simultaneously. We therefore facilitate users in exploring not only text prompts but also audio priors that constrain the text-to-audio music generation process. This dual-sided exploration enables users to discern the impact of different text prompts and audio priors on the generation results through iterative comparison of them. Our developed interface, IteraTTA, is specifically designed to aid users in refining text prompts and selecting favorable audio priors from the generated audios. With this, users can progressively reach their loosely-specified goals while understanding and exploring the space of possible results. Our implementation and discussions highlight design considerations that are specifically required for text-to-audio models and how interaction techniques can contribute to their effectiveness.
CatAlyst: Domain-Extensible Intervention for Preventing Task Procrastination Using Large Generative Models
Feb 11, 2023
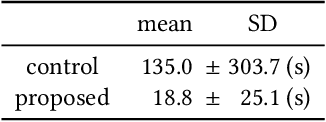

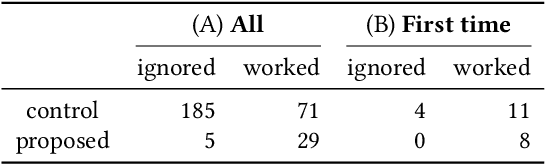
CatAlyst uses generative models to help workers' progress by influencing their task engagement instead of directly contributing to their task outputs. It prompts distracted workers to resume their tasks by generating a continuation of their work and presenting it as an intervention that is more context-aware than conventional (predetermined) feedback. The prompt can function by drawing their interest and lowering the hurdle for resumption even when the generated continuation is insufficient to substitute their work, while recent human-AI collaboration research aiming at work substitution depends on a stable high accuracy. This frees CatAlyst from domain-specific model-tuning and makes it applicable to various tasks. Our studies involving writing and slide-editing tasks demonstrated CatAlyst's effectiveness in helping workers swiftly resume tasks with a lowered cognitive load. The results suggest a new form of human-AI collaboration where large generative models publicly available but imperfect for each individual domain can contribute to workers' digital well-being.
Tool- and Domain-Agnostic Parameterization of Style Transfer Effects Leveraging Pretrained Perceptual Metrics
May 19, 2021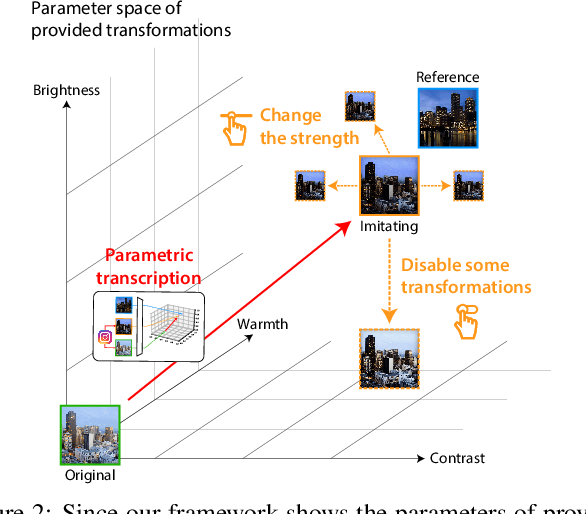


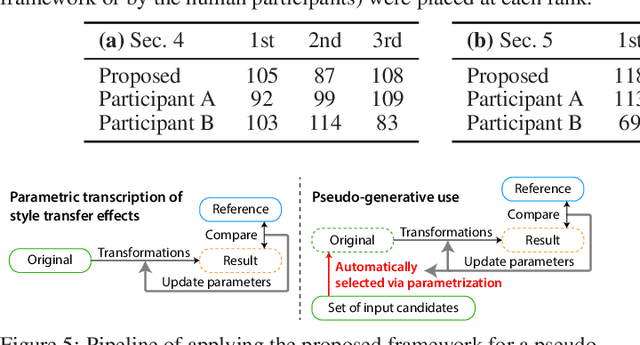
Current deep learning techniques for style transfer would not be optimal for design support since their "one-shot" transfer does not fit exploratory design processes. To overcome this gap, we propose parametric transcription, which transcribes an end-to-end style transfer effect into parameter values of specific transformations available in an existing content editing tool. With this approach, users can imitate the style of a reference sample in the tool that they are familiar with and thus can easily continue further exploration by manipulating the parameters. To enable this, we introduce a framework that utilizes an existing pretrained model for style transfer to calculate a perceptual style distance to the reference sample and uses black-box optimization to find the parameters that minimize this distance. Our experiments with various third-party tools, such as Instagram and Blender, show that our framework can effectively leverage deep learning techniques for computational design support.
Lyric Video Analysis Using Text Detection and Tracking
Jun 21, 2020
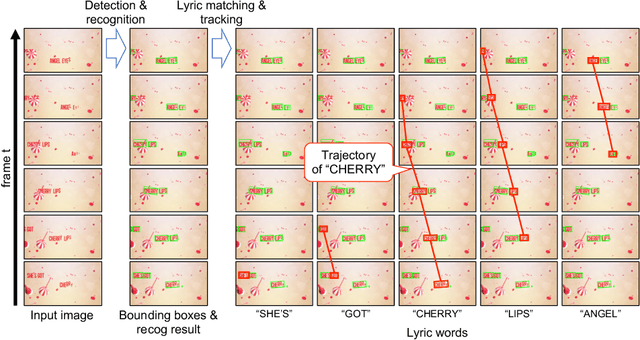

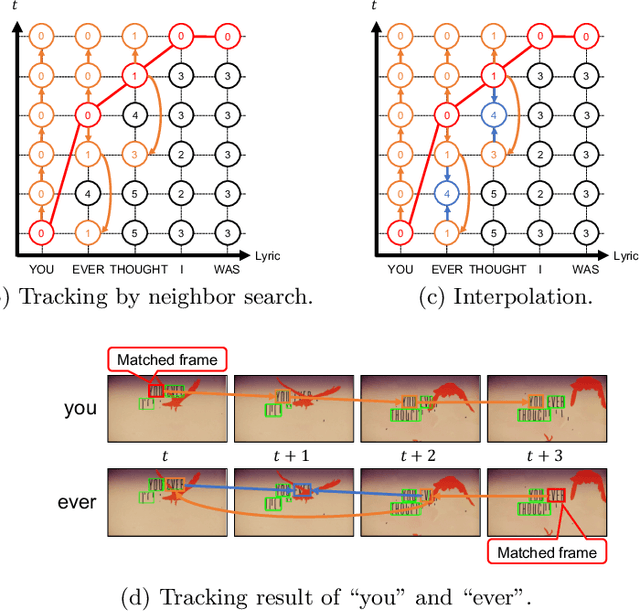
We attempt to recognize and track lyric words in lyric videos. Lyric video is a music video showing the lyric words of a song. The main characteristic of lyric videos is that the lyric words are shown at frames synchronously with the music. The difficulty of recognizing and tracking the lyric words is that (1) the words are often decorated and geometrically distorted and (2) the words move arbitrarily and drastically in the video frame. The purpose of this paper is to analyze the motion of the lyric words in lyric videos, as the first step of automatic lyric video generation. In order to analyze the motion of lyric words, we first apply a state-of-the-art scene text detector and recognizer to each video frame. Then, lyric-frame matching is performed to establish the optimal correspondence between lyric words and the frames. After fixing the motion trajectories of individual lyric words from correspondence, we analyze the trajectories of the lyric words by k-medoids clustering and dynamic time warping (DTW).
Sequential Gallery for Interactive Visual Design Optimization
May 08, 2020
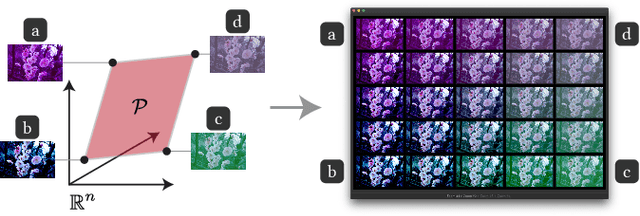


Visual design tasks often involve tuning many design parameters. For example, color grading of a photograph involves many parameters, some of which non-expert users might be unfamiliar with. We propose a novel user-in-the-loop optimization method that allows users to efficiently find an appropriate parameter set by exploring such a high-dimensional design space through much easier two-dimensional search subtasks. This method, called sequential plane search, is based on Bayesian optimization to keep necessary queries to users as few as possible. To help users respond to plane-search queries, we also propose using a gallery-based interface that provides options in the two-dimensional subspace arranged in an adaptive grid view. We call this interactive framework Sequential Gallery since users sequentially select the best option from the options provided by the interface. Our experiment with synthetic functions shows that our sequential plane search can find satisfactory solutions in fewer iterations than baselines. We also conducted a preliminary user study, results of which suggest that novices can effectively complete search tasks with Sequential Gallery in a photo-enhancement scenario.
* To be published at ACM Trans. Graph. (Proc. SIGGRAPH 2020); Project page available at https://koyama.xyz/project/sequential_gallery/
MirrorNet: A Deep Bayesian Approach to Reflective 2D Pose Estimation from Human Images
Apr 08, 2020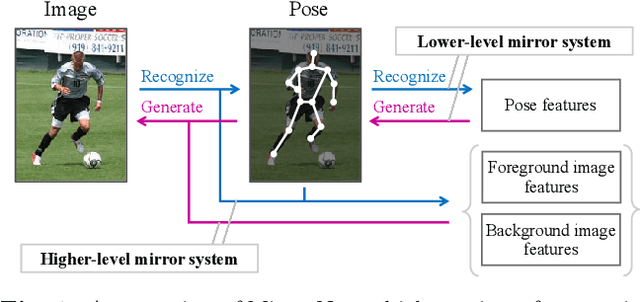

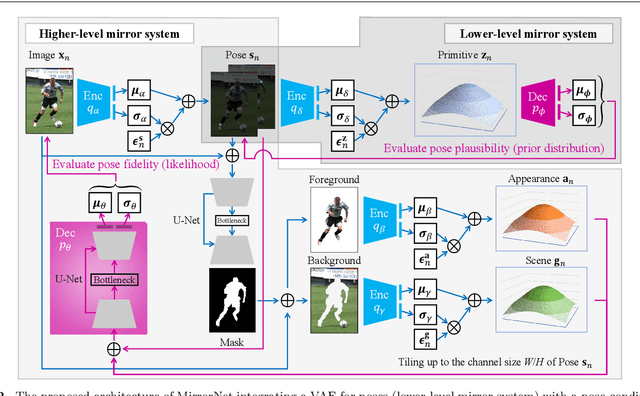
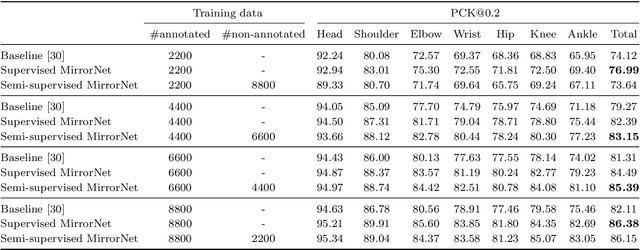
This paper proposes a statistical approach to 2D pose estimation from human images. The main problems with the standard supervised approach, which is based on a deep recognition (image-to-pose) model, are that it often yields anatomically implausible poses, and its performance is limited by the amount of paired data. To solve these problems, we propose a semi-supervised method that can make effective use of images with and without pose annotations. Specifically, we formulate a hierarchical generative model of poses and images by integrating a deep generative model of poses from pose features with that of images from poses and image features. We then introduce a deep recognition model that infers poses from images. Given images as observed data, these models can be trained jointly in a hierarchical variational autoencoding (image-to-pose-to-feature-to-pose-to-image) manner. The results of experiments show that the proposed reflective architecture makes estimated poses anatomically plausible, and the performance of pose estimation improved by integrating the recognition and generative models and also by feeding non-annotated images.
Taste or Addiction?: Using Play Logs to Infer Song Selection Motivation
May 26, 2017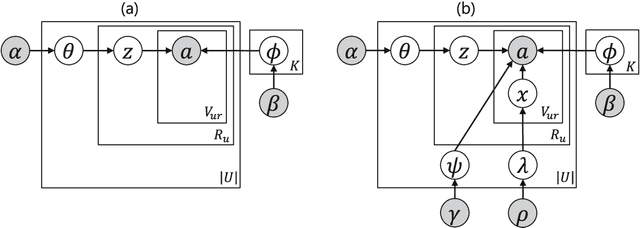
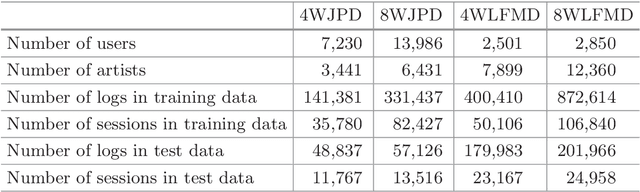
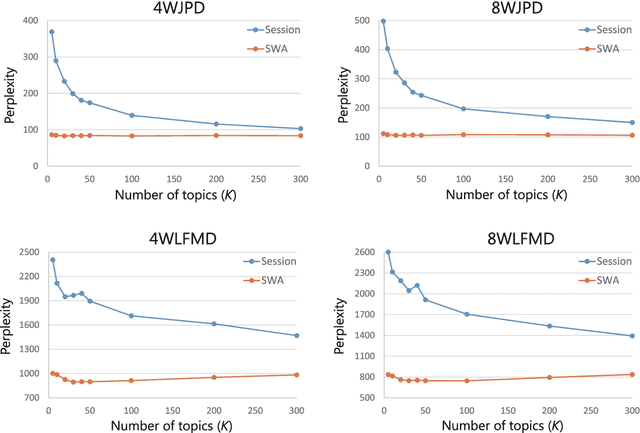
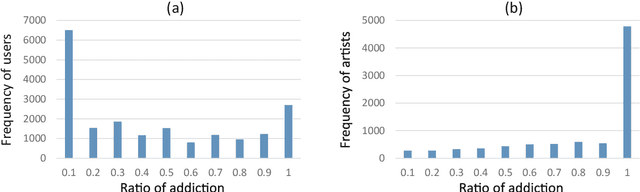
Online music services are increasing in popularity. They enable us to analyze people's music listening behavior based on play logs. Although it is known that people listen to music based on topic (e.g., rock or jazz), we assume that when a user is addicted to an artist, s/he chooses the artist's songs regardless of topic. Based on this assumption, in this paper, we propose a probabilistic model to analyze people's music listening behavior. Our main contributions are three-fold. First, to the best of our knowledge, this is the first study modeling music listening behavior by taking into account the influence of addiction to artists. Second, by using real-world datasets of play logs, we showed the effectiveness of our proposed model. Third, we carried out qualitative experiments and showed that taking addiction into account enables us to analyze music listening behavior from a new viewpoint in terms of how people listen to music according to the time of day, how an artist's songs are listened to by people, etc. We also discuss the possibility of applying the analysis results to applications such as artist similarity computation and song recommendation.