 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CMU-AIST submission for the ICME 2025 Audio Encoder Challenge
Jan 22, 2026This technical report describes our submission to the ICME 2025 audio encoder challenge. Our submitted system is built on BEATs, a masked speech token prediction based audio encoder. We extend the BEATs model using 74,000 hours of data derived from various speech, music, and sound corpora and scale its architecture upto 300 million parameters. We experiment with speech-heavy and balanced pre-training mixtures to study the impact of different domains on final performance. Our submitted system consists of an ensemble of the Dasheng 1.2 billion model with two custom scaled-up BEATs models trained on the aforementioned pre-training data mixtures. We also propose a simple ensembling technique that retains the best capabilities of constituent models and surpasses both the baseline and Dasheng 1.2B. For open science, we publicly release our trained checkpoints via huggingface at https://huggingface.co/shikhar7ssu/OpenBEATs-ICME-SOUND and https://huggingface.co/shikhar7ssu/OpenBEATs-ICME.
OpenBEATs: A Fully Open-Source General-Purpose Audio Encoder
Jul 18, 2025



Masked token prediction has emerged as a powerful pre-training objective across language, vision, and speech, offering the potential to unify these diverse modalities through a single pre-training task. However, its application for general audio understanding remains underexplored, with BEATs being the only notable example. BEATs has seen limited modifications due to the absence of open-source pre-training code. Furthermore, BEATs was trained only on AudioSet, restricting its broader downstream applicability. To address these gaps, we present OpenBEATs, an open-source framework that extends BEATs via multi-domain audio pre-training. We conduct comprehensive evaluations across six types of tasks, twenty five datasets, and three audio domains, including audio reasoning tasks such as audio question answering, entailment, and captioning. OpenBEATs achieves state-of-the-art performance on six bioacoustics datasets, two environmental sound datasets and five reasoning datasets, performing better than models exceeding a billion parameters at one-fourth their parameter size. These results demonstrate the effectiveness of multi-domain datasets and masked token prediction task to learn general-purpose audio representations. To promote further research and reproducibility, we release all pre-training and evaluation code, pretrained and fine-tuned checkpoints, and training logs at https://shikhar-s.github.io/OpenBEATs
Voice Conversion for Likability Control via Automated Rating of Speech Synthesis Corpora
Jul 02, 2025



Perceived voice likability plays a crucial role in various social interactions, such as partner selection and advertising. A system that provides reference likable voice samples tailored to target audiences would enable users to adjust their speaking style and voice quality, facilitating smoother communication. To this end, we propose a voice conversion method that controls the likability of input speech while preserving both speaker identity and linguistic content. To improve training data scalability, we train a likability predictor on an existing voice likability dataset and employ it to automatically annotate a large speech synthesis corpus with likability ratings. Experimental evaluations reveal a significant correlation between the predictor's outputs and human-provided likability ratings. Subjective and objective evaluations further demonstrate that the proposed approach effectively controls voice likability while preserving both speaker identity and linguistic content.
IdolSongsJp Corpus: A Multi-Singer Song Corpus in the Style of Japanese Idol Groups
Jul 02, 2025Japanese idol groups, comprising performers known as "idols," are an indispensable part of Japanese pop culture. They frequently appear in live concerts and television programs, entertaining audiences with their singing and dancing. Similar to other J-pop songs, idol group music covers a wide range of styles, with various types of chord progressions and instrumental arrangements. These tracks often feature numerous instruments and employ complex mastering techniques, resulting in high signal loudness. Additionally, most songs include a song division (utawari) structure, in which members alternate between singing solos and performing together. Hence, these songs are well-suited for benchmarking various music information processing techniques such as singer diarization, music source separation, and automatic chord estimation under challenging conditions. Focusing on these characteristics, we constructed a song corpus titled IdolSongsJp by commissioning professional composers to create 15 tracks in the style of Japanese idol groups. This corpus includes not only mastered audio tracks but also stems for music source separation, dry vocal tracks, and chord annotations. This paper provides a detailed description of the corpus, demonstrates its diversity through comparisons with real-world idol group songs, and presents its application in evaluating several music information processing techniques.
Discrete Tokens Exhibit Interlanguage Speech Intelligibility Benefit: an Analytical Study Towards Accent-robust ASR Only with Native Speech Data
May 22, 2025



In this study, we gained insight that contributes to achieving accent-robust ASR using only native speech data. In human perception of non-native speech, the phenomenon known as "interlanguage speech intelligibility benefit" (ISIB) is observed, where non-native listeners who share the native language with the speaker understand the speech better compared even to native listeners. Based on the idea that discrete tokens extracted from self-supervised learning (SSL) models represent the human perception of speech, we conducted an analytical study on the robustness of discrete token-based ASR to non-native speech, varying the language used for training the tokenization, which is viewed as a technical implementation of ISIB. The results showed that ISIB actually occurred in the discrete token-based ASR. Since our approach relies only on native speech data to simulate the behavior of human perception, it is expected to be applicable to a wide range of accents for which speech data is scarce.
Prosodically Enhanced Foreign Accent Simulation by Discrete Token-based Resynthesis Only with Native Speech Corpora
May 22, 2025Recently, a method for synthesizing foreign-accented speech only with native speech data using discrete tokens obtained from self-supervised learning (SSL) models was proposed. Considering limited availability of accented speech data, this method is expected to make it much easier to simulate foreign accents. By using the synthesized accented speech as listening materials for humans or training data for automatic speech recognition (ASR), both of them will acquire higher robustness against foreign accents. However, the previous method has a fatal flaw that it cannot reproduce duration-related accents. Durational accents are commonly seen when L2 speakers, whose native language has syllable-timed or mora-timed rhythm, speak stress-timed languages, such as English. In this paper, we integrate duration modification to the previous method to simulate foreign accents more accurately. Experiments show that the proposed method successfully replicates durational accents seen in real L2 speech.
Discrete Speech Unit Extraction via Independent Component Analysis
Jan 11, 2025



Self-supervised speech models (S3Ms) have become a common tool for the speech processing community, leveraging representations for downstream tasks. Clustering S3M representations yields discrete speech units (DSUs), which serve as compact representations for speech signals. DSUs are typically obtained by k-means clustering. Using DSUs often leads to strong performance in various tasks, including automatic speech recognition (ASR). However, even with the high dimensionality and redundancy of S3M representations, preprocessing S3M representations for better clustering remains unexplored, even though it can affect the quality of DSUs. In this paper, we investigate the potential of linear preprocessing methods for extracting DSUs. We evaluate standardization, principal component analysis, whitening, and independent component analysis (ICA) on DSU-based ASR benchmarks and demonstrate their effectiveness as preprocessing for k-means. We also conduct extensive analyses of their behavior, such as orthogonality or interpretability of individual components of ICA.
Self-Supervised Speech Representations are More Phonetic than Semantic
Jun 12, 2024



Self-supervised speech models (S3Ms) have become an effective backbone for speech applications. Various analyses suggest that S3Ms encode linguistic properties. In this work, we seek a more fine-grained analysis of the word-level linguistic properties encoded in S3Ms. Specifically, we curate a novel dataset of near homophone (phonetically similar) and synonym (semantically similar) word pairs and measure the similarities between S3M word representation pairs. Our study reveals that S3M representations consistently and significantly exhibit more phonetic than semantic similarity. Further, we question whether widely used intent classification datasets such as Fluent Speech Commands and Snips Smartlights are adequate for measuring semantic abilities. Our simple baseline, using only the word identity, surpasses S3M-based models. This corroborates our findings and suggests that high scores on these datasets do not necessarily guarantee the presence of semantic content.
jaCappella Corpus: A Japanese a Cappella Vocal Ensemble Corpus
Dec 09, 2022



We construct a corpus of Japanese a cappella vocal ensembles (jaCappella corpus) for vocal ensemble separation and synthesis. It consists of 35 copyright-cleared vocal ensemble songs and their audio recordings of individual voice parts. These songs were arranged from out-of-copyright Japanese children's songs and have six voice parts (lead vocal, soprano, alto, tenor, bass, and vocal percussion). They are divided into seven subsets, each of which features typical characteristics of a music genre such as jazz and enka. The variety in genre and voice part match vocal ensembles recently widespread in social media services such as YouTube, although the main targets of conventional vocal ensemble datasets are choral singing made up of soprano, alto, tenor, and bass. Experimental evaluation demonstrates that our corpus is a challenging resource for vocal ensemble separation. Our corpus is available on our project page (https://tomohikonakamura.github.io/jaCappella_corpus/).
Hyperbolic Timbre Embedding for Musical Instrument Sound Synthesis Based on Variational Autoencoders
Sep 27, 2022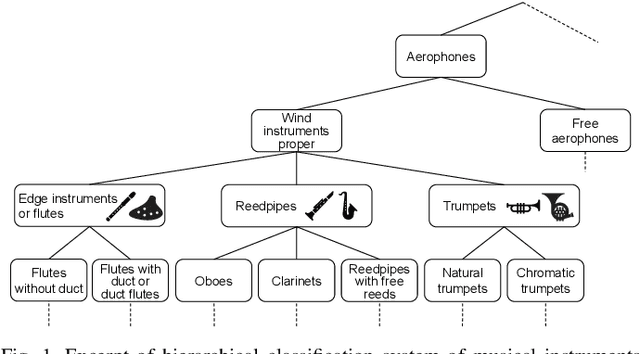
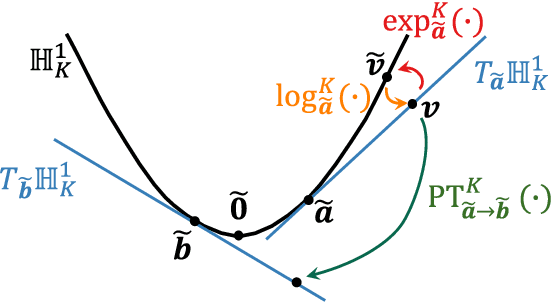
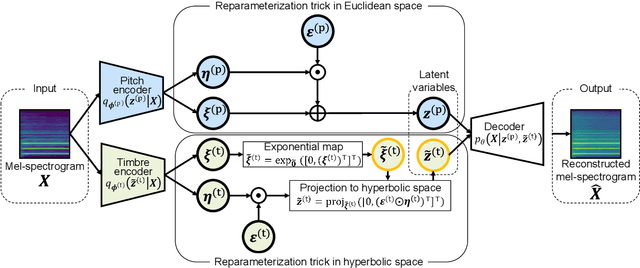
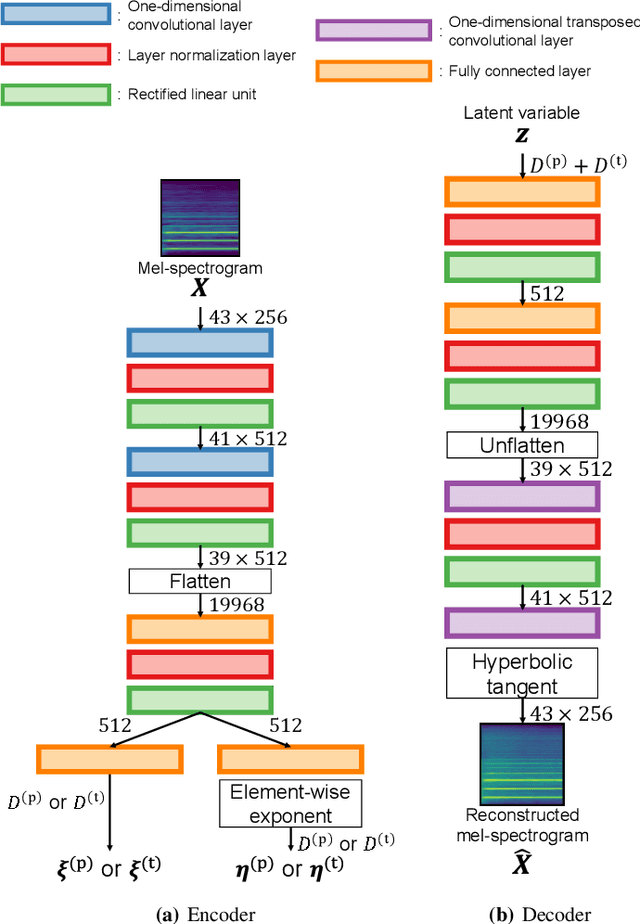
In this paper, we propose a musical instrument sound synthesis (MISS) method based on a variational autoencoder (VAE) that has a hierarchy-inducing latent space for timbre. VAE-based MISS methods embed an input signal into a low-dimensional latent representation that captures the characteristics of the input. Adequately manipulating this representation leads to sound morphing and timbre replacement. Although most VAE-based MISS methods seek a disentangled representation of pitch and timbre, how to capture an underlying structure in timbre remains an open problem. To address this problem, we focus on the fact that musical instruments can be hierarchically classified on the basis of their physical mechanisms. Motivated by this hierarchy, we propose a VAE-based MISS method by introducing a hyperbolic space for timbre. The hyperbolic space can represent treelike data more efficiently than the Euclidean space owing to its exponential growth property. Results of experiments show that the proposed method provides an efficient latent representation of timbre compared with the method using the Euclidean space.