 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompound Word Transformer: Learning to Compose Full-Song Music over Dynamic Directed Hypergraphs
Jan 07, 2021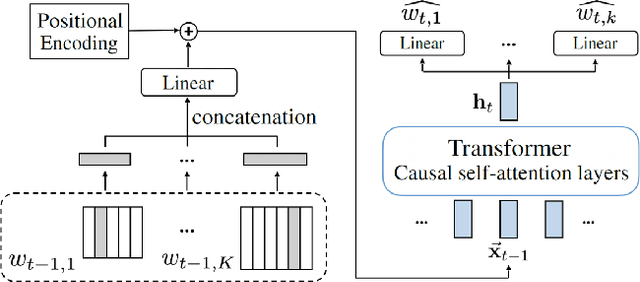
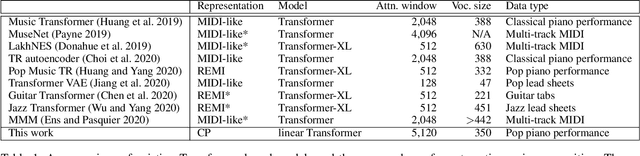
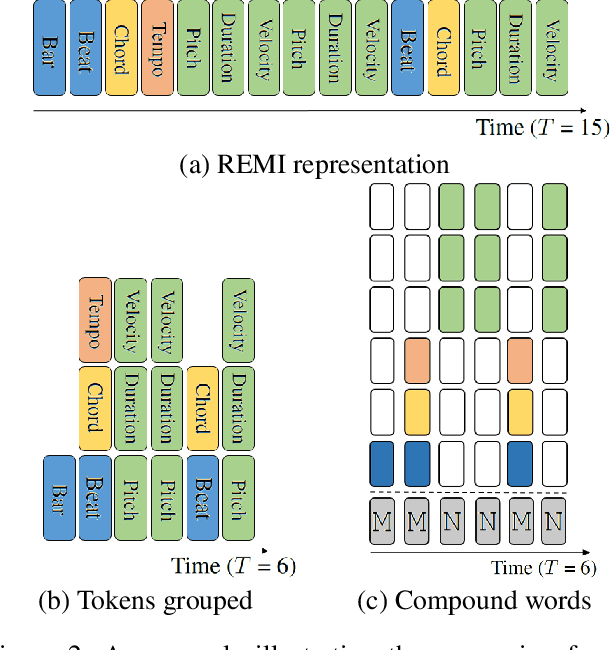

To apply neural sequence models such as the Transformers to music generation tasks, one has to represent a piece of music by a sequence of tokens drawn from a finite set of pre-defined vocabulary. Such a vocabulary usually involves tokens of various types. For example, to describe a musical note, one needs separate tokens to indicate the note's pitch, duration, velocity (dynamics), and placement (onset time) along the time grid. While different types of tokens may possess different properties, existing models usually treat them equally, in the same way as modeling words in natural languages. In this paper, we present a conceptually different approach that explicitly takes into account the type of the tokens, such as note types and metric types. And, we propose a new Transformer decoder architecture that uses different feed-forward heads to model tokens of different types. With an expansion-compression trick, we convert a piece of music to a sequence of compound words by grouping neighboring tokens, greatly reducing the length of the token sequences. We show that the resulting model can be viewed as a learner over dynamic directed hypergraphs. And, we employ it to learn to compose expressive Pop piano music of full-song length (involving up to 10K individual tokens per song), both conditionally and unconditionally. Our experiment shows that, compared to state-of-the-art models, the proposed model converges 5--10 times faster at training (i.e., within a day on a single GPU with 11 GB memory), and with comparable quality in the generated music.
Mixing-Specific Data Augmentation Techniques for Improved Blind Violin/Piano Source Separation
Aug 06, 2020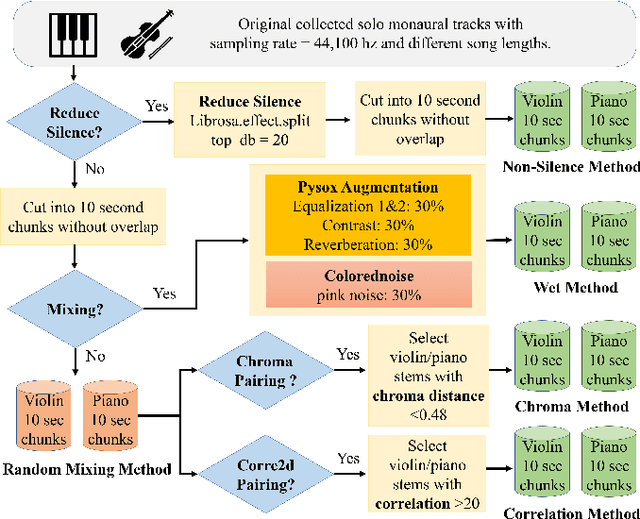
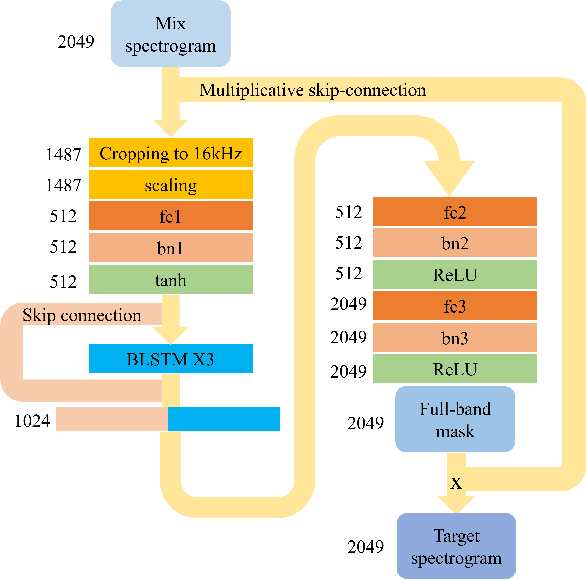
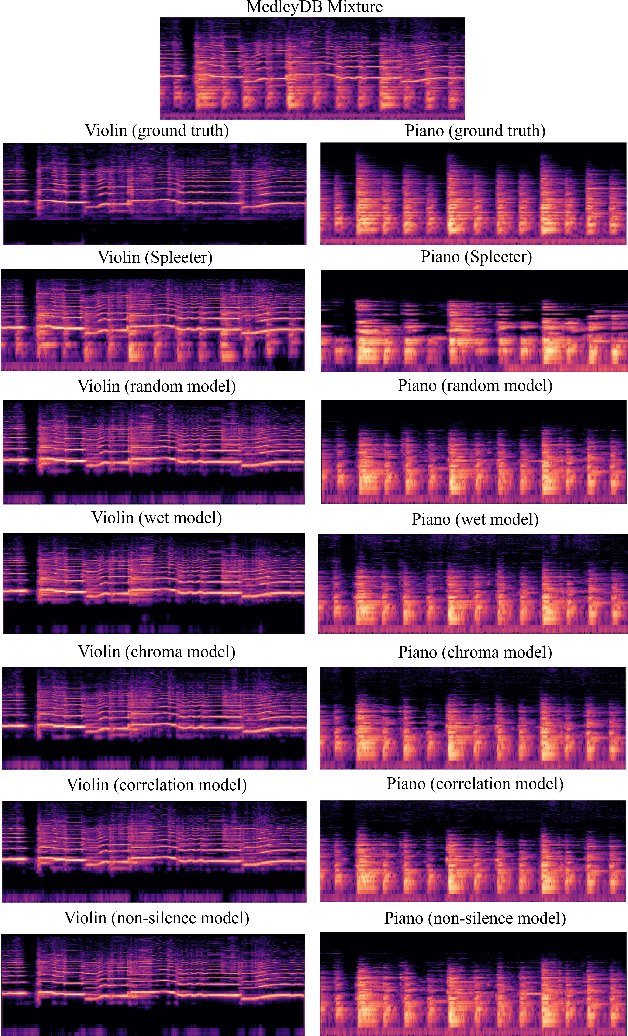
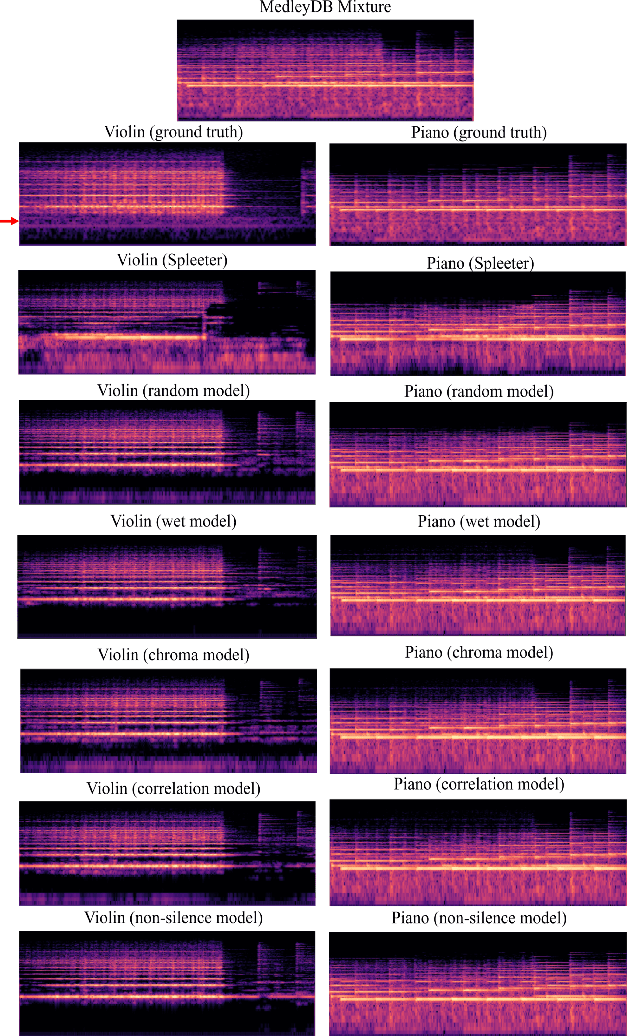
Blind music source separation has been a popular and active subject of research in both the music information retrieval and signal processing communities. To counter the lack of available multi-track data for supervised model training, a data augmentation method that creates artificial mixtures by combining tracks from different songs has been shown useful in recent works. Following this light, we examine further in this paper extended data augmentation methods that consider more sophisticated mixing settings employed in the modern music production routine, the relationship between the tracks to be combined, and factors of silence. As a case study, we consider the separation of violin and piano tracks in a violin piano ensemble, evaluating the performance in terms of common metrics, namely SDR, SIR, and SAR. In addition to examining the effectiveness of these new data augmentation methods, we also study the influence of the amount of training data. Our evaluation shows that the proposed mixing-specific data augmentation methods can help improve the performance of a deep learning-based model for source separation, especially in the case of small training data.
Unconditional Audio Generation with Generative Adversarial Networks and Cycle Regularization
May 18, 2020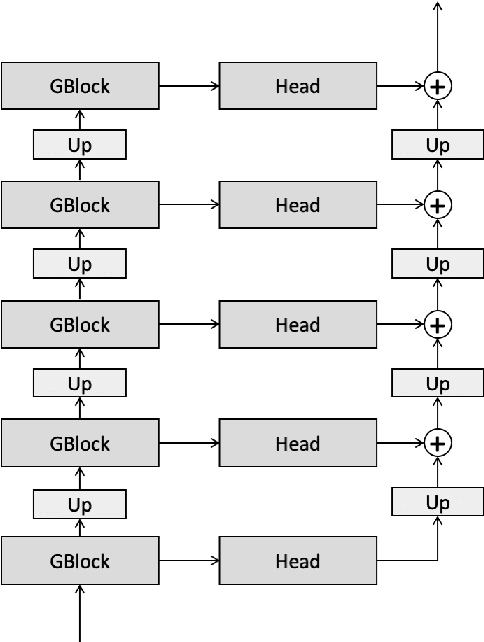
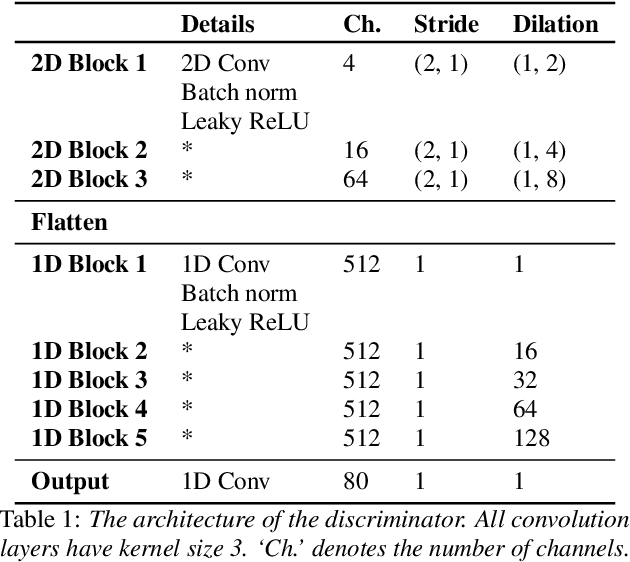
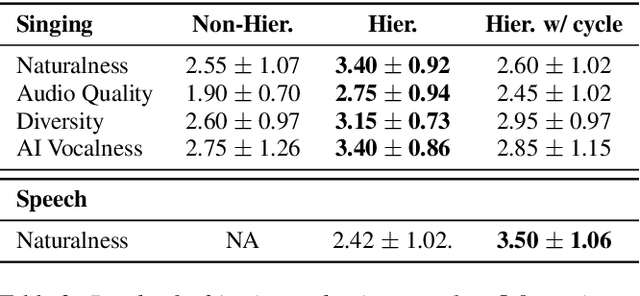
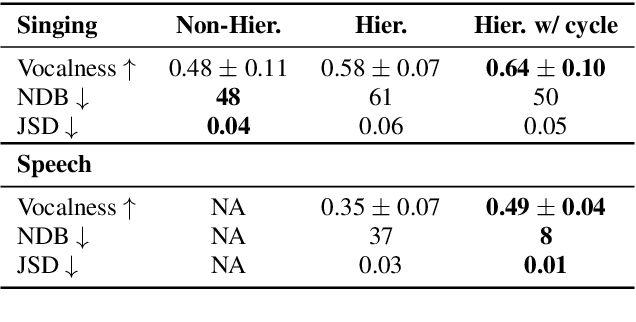
In a recent paper, we have presented a generative adversarial network (GAN)-based model for unconditional generation of the mel-spectrograms of singing voices. As the generator of the model is designed to take a variable-length sequence of noise vectors as input, it can generate mel-spectrograms of variable length. However, our previous listening test shows that the quality of the generated audio leaves room for improvement. The present paper extends and expands that previous work in the following aspects. First, we employ a hierarchical architecture in the generator to induce some structure in the temporal dimension. Second, we introduce a cycle regularization mechanism to the generator to avoid mode collapse. Third, we evaluate the performance of the new model not only for generating singing voices, but also for generating speech voices. Evaluation result shows that new model outperforms the prior one both objectively and subjectively. We also employ the model to unconditionally generate sequences of piano and violin music and find the result promising. Audio examples, as well as the code for implementing our model, will be publicly available online upon paper publication.
Automatic Melody Harmonization with Triad Chords: A Comparative Study
Jan 08, 2020
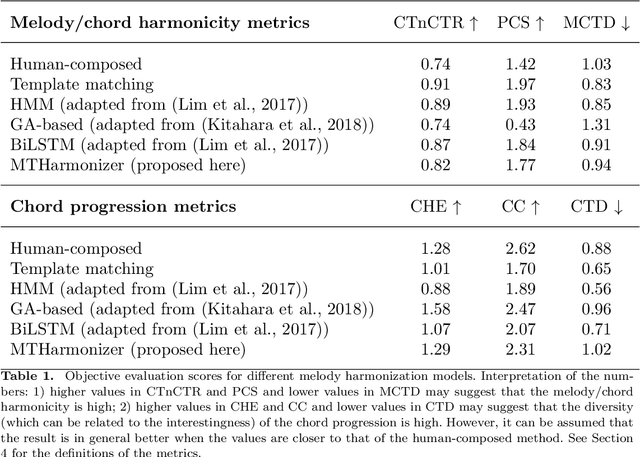
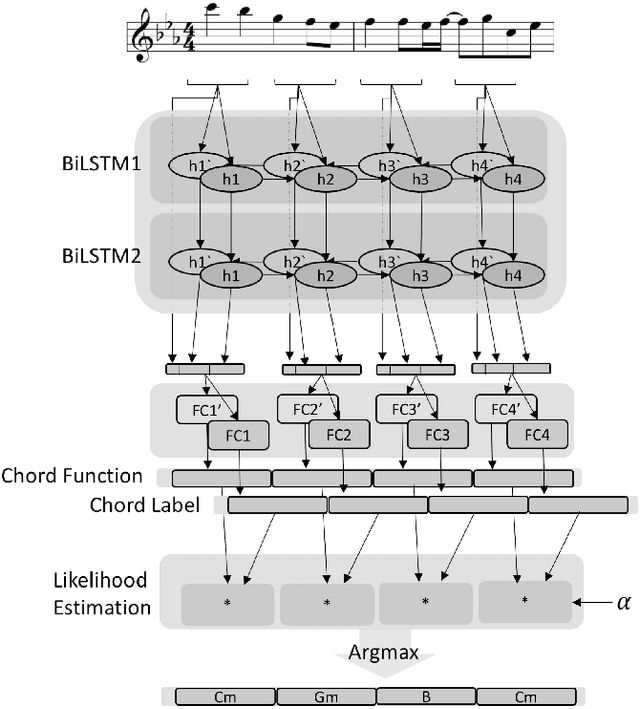

Several prior works have proposed various methods for the task of automatic melody harmonization, in which a model aims to generate a sequence of chords to serve as the harmonic accompaniment of a given multiple-bar melody sequence. In this paper, we present a comparative study evaluating and comparing the performance of a set of canonical approaches to this task, including a template matching based model, a hidden Markov based model, a genetic algorithm based model, and two deep learning based models. The evaluation is conducted on a dataset of 9,226 melody/chord pairs we newly collect for this study, considering up to 48 triad chords, using a standardized training/test split. We report the result of an objective evaluation using six different metrics and a subjective study with 202 participants.
Score and Lyrics-Free Singing Voice Generation
Dec 26, 2019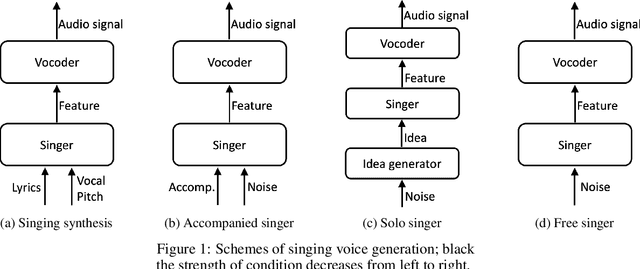
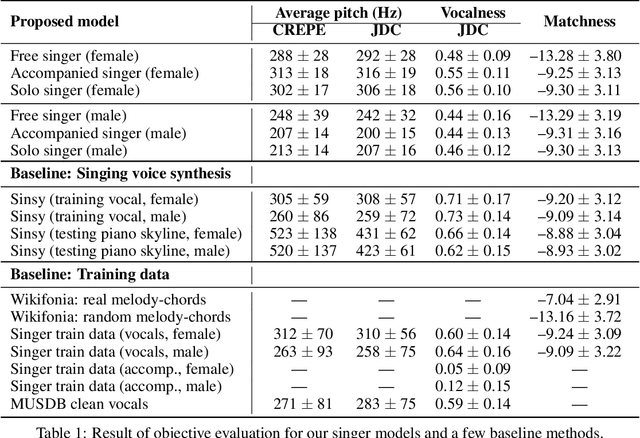
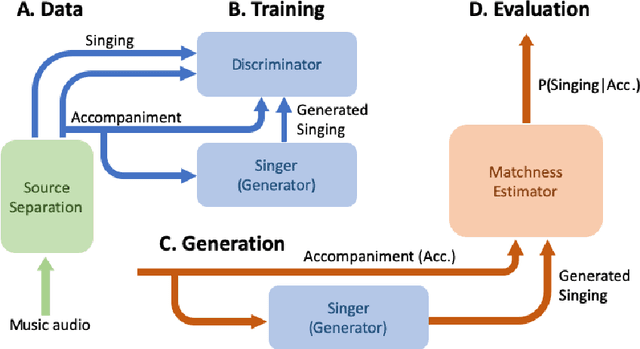

Generative models for singing voice have been mostly concerned with the task of "singing voice synthesis," i.e., to produce singing voice waveforms given musical scores and text lyrics. In this work, we explore a novel yet challenging alternative: singing voice generation without pre-assigned scores and lyrics, in both training and inference time. In particular, we propose three either unconditioned or weakly conditioned singing voice generation schemes. We outline the associated challenges and propose a pipeline to tackle these new tasks. This involves the development of source separation and transcription models for data preparation, adversarial networks for audio generation, and customized metrics for evaluation.