 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalizability to Tone and Content Variations in the Transcription of Amplifier Rendered Electric Guitar Audio
Apr 10, 2025Transcribing electric guitar recordings is challenging due to the scarcity of diverse datasets and the complex tone-related variations introduced by amplifiers, cabinets, and effect pedals. To address these issues, we introduce EGDB-PG, a novel dataset designed to capture a wide range of tone-related characteristics across various amplifier-cabinet configurations. In addition, we propose the Tone-informed Transformer (TIT), a Transformer-based transcription model enhanced with a tone embedding mechanism that leverages learned representations to improve the model's adaptability to tone-related nuances. Experiments demonstrate that TIT, trained on EGDB-PG, outperforms existing baselines across diverse amplifier types, with transcription accuracy improvements driven by the dataset's diversity and the tone embedding technique. Through detailed benchmarking and ablation studies, we evaluate the impact of tone augmentation, content augmentation, audio normalization, and tone embedding on transcription performance. This work advances electric guitar transcription by overcoming limitations in dataset diversity and tone modeling, providing a robust foundation for future research.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
Demo of Zero-Shot Guitar Amplifier Modelling: Enhancing Modeling with Hyper Neural Networks
Oct 07, 2024
Electric guitar tone modeling typically focuses on the non-linear transformation from clean to amplifier-rendered audio. Traditional methods rely on one-to-one mappings, incorporating device parameters into neural models to replicate specific amplifiers. However, these methods are limited by the need for specific training data. In this paper, we adapt a model based on the previous work, which leverages a tone embedding encoder and a feature wise linear modulation (FiLM) condition method. In this work, we altered conditioning method using a hypernetwork-based gated convolutional network (GCN) to generate audio that blends clean input with the tone characteristics of reference audio. By extending the training data to cover a wider variety of amplifier tones, our model is able to capture a broader range of tones. Additionally, we developed a real-time plugin to demonstrate the system's practical application, allowing users to experience its performance interactively. Our results indicate that the proposed system achieves superior tone modeling versatility compared to traditional methods.
DDSP Guitar Amp: Interpretable Guitar Amplifier Modeling
Aug 21, 2024


Neural network models for guitar amplifier emulation, while being effective, often demand high computational cost and lack interpretability. Drawing ideas from physical amplifier design, this paper aims to address these issues with a new differentiable digital signal processing (DDSP)-based model, called ``DDSP guitar amp,'' that models the four components of a guitar amp (i.e., preamp, tone stack, power amp, and output transformer) using specific DSP-inspired designs. With a set of time- and frequency-domain metrics, we demonstrate that DDSP guitar amp achieves performance comparable with that of black-box baselines while requiring less than 10\% of the computational operations per audio sample, thereby holding greater potential for usages in real-time applications.
Towards zero-shot amplifier modeling: One-to-many amplifier modeling via tone embedding control
Jul 15, 2024



Replicating analog device circuits through neural audio effect modeling has garnered increasing interest in recent years. Existing work has predominantly focused on a one-to-one emulation strategy, modeling specific devices individually. In this paper, we tackle the less-explored scenario of one-to-many emulation, utilizing conditioning mechanisms to emulate multiple guitar amplifiers through a single neural model. For condition representation, we use contrastive learning to build a tone embedding encoder that extracts style-related features of various amplifiers, leveraging a dataset of comprehensive amplifier settings. Targeting zero-shot application scenarios, we also examine various strategies for tone embedding representation, evaluating referenced tone embedding against two retrieval-based embedding methods for amplifiers unseen in the training time. Our findings showcase the efficacy and potential of the proposed methods in achieving versatile one-to-many amplifier modeling, contributing a foundational step towards zero-shot audio modeling applications.
Improving Unsupervised Clean-to-Rendered Guitar Tone Transformation Using GANs and Integrated Unaligned Clean Data
Jun 22, 2024



Recent years have seen increasing interest in applying deep learning methods to the modeling of guitar amplifiers or effect pedals. Existing methods are mainly based on the supervised approach, requiring temporally-aligned data pairs of unprocessed and rendered audio. However, this approach does not scale well, due to the complicated process involved in creating the data pairs. A very recent work done by Wright et al. has explored the potential of leveraging unpaired data for training, using a generative adversarial network (GAN)-based framework. This paper extends their work by using more advanced discriminators in the GAN, and using more unpaired data for training. Specifically, drawing inspiration from recent advancements in neural vocoders, we employ in our GAN-based model for guitar amplifier modeling two sets of discriminators, one based on multi-scale discriminator (MSD) and the other multi-period discriminator (MPD). Moreover, we experiment with adding unprocessed audio signals that do not have the corresponding rendered audio of a target tone to the training data, to see how much the GAN model benefits from the unpaired data. Our experiments show that the proposed two extensions contribute to the modeling of both low-gain and high-gain guitar amplifiers.
GTR-CTRL: Instrument and Genre Conditioning for Guitar-Focused Music Generation with Transformers
Feb 10, 2023Recently, symbolic music generation with deep learning techniques has witnessed steady improvements. Most works on this topic focus on MIDI representations, but less attention has been paid to symbolic music generation using guitar tablatures (tabs) which can be used to encode multiple instruments. Tabs include information on expressive techniques and fingerings for fretted string instruments in addition to rhythm and pitch. In this work, we use the DadaGP dataset for guitar tab music generation, a corpus of over 26k songs in GuitarPro and token formats. We introduce methods to condition a Transformer-XL deep learning model to generate guitar tabs (GTR-CTRL) based on desired instrumentation (inst-CTRL) and genre (genre-CTRL). Special control tokens are appended at the beginning of each song in the training corpus. We assess the performance of the model with and without conditioning. We propose instrument presence metrics to assess the inst-CTRL model's response to a given instrumentation prompt. We trained a BERT model for downstream genre classification and used it to assess the results obtained with the genre-CTRL model. Statistical analyses evidence significant differences between the conditioned and unconditioned models. Overall, results indicate that the GTR-CTRL methods provide more flexibility and control for guitar-focused symbolic music generation than an unconditioned model.
* This preprint is licensed under a Creative Commons Attribution 4.0 International License (CC BY 4.0). The Version of Record of this contribution is published in Proceedings of EvoMUSART: International Conference on Computational Intelligence in Music, Sound, Art and Design (Part of EvoStar) 2023
towards automatic transcription of polyphonic electric guitar music:a new dataset and a multi-loss transformer model
Feb 20, 2022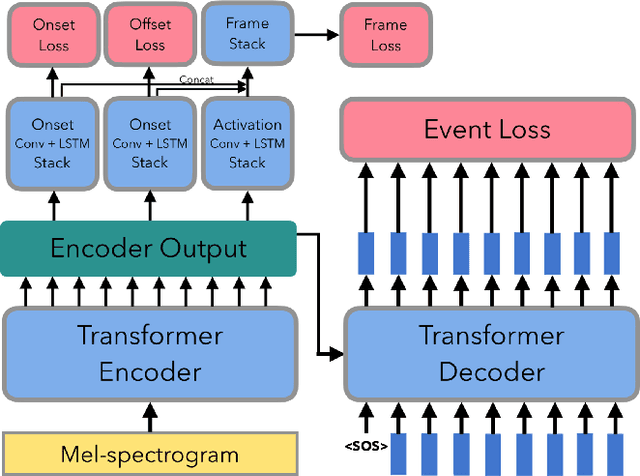
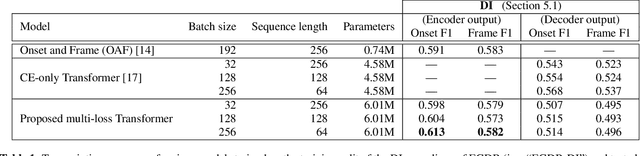

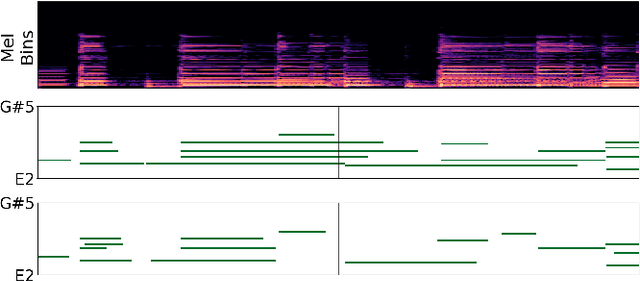
In this paper, we propose a new dataset named EGDB, that con-tains transcriptions of the electric guitar performance of 240 tab-latures rendered with different tones. Moreover, we benchmark theperformance of two well-known transcription models proposed orig-inally for the piano on this dataset, along with a multi-loss Trans-former model that we newly propose. Our evaluation on this datasetand a separate set of real-world recordings demonstrate the influenceof timbre on the accuracy of guitar sheet transcription, the potentialof using multiple losses for Transformers, as well as the room forfurther improvement for this task.
Source Separation-based Data Augmentation for Improved Joint Beat and Downbeat Tracking
Jun 16, 2021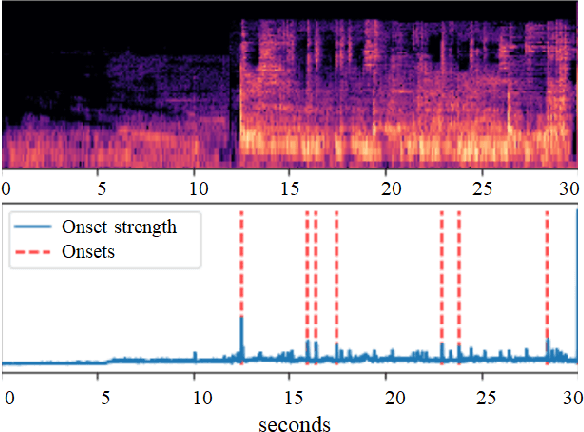
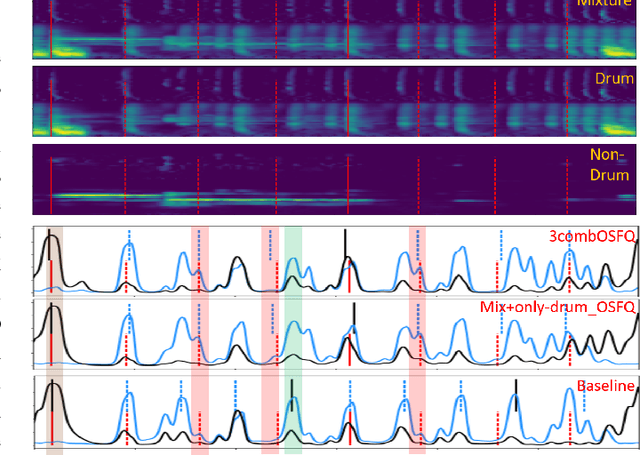
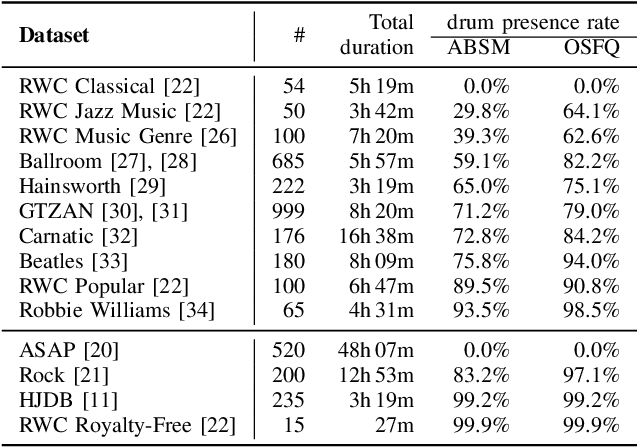
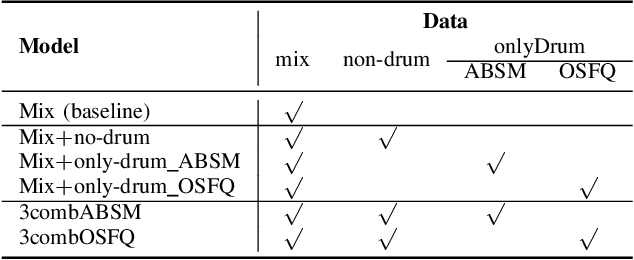
Due to advances in deep learning, the performance of automatic beat and downbeat tracking in musical audio signals has seen great improvement in recent years. In training such deep learning based models, data augmentation has been found an important technique. However, existing data augmentation methods for this task mainly target at balancing the distribution of the training data with respect to their tempo. In this paper, we investigate another approach for data augmentation, to account for the composition of the training data in terms of the percussive and non-percussive sound sources. Specifically, we propose to employ a blind drum separation model to segregate the drum and non-drum sounds from each training audio signal, filtering out training signals that are drumless, and then use the obtained drum and non-drum stems to augment the training data. We report experiments on four completely unseen test sets, validating the effectiveness of the proposed method, and accordingly the importance of drum sound composition in the training data for beat and downbeat tracking.
Unconditional Audio Generation with Generative Adversarial Networks and Cycle Regularization
May 18, 2020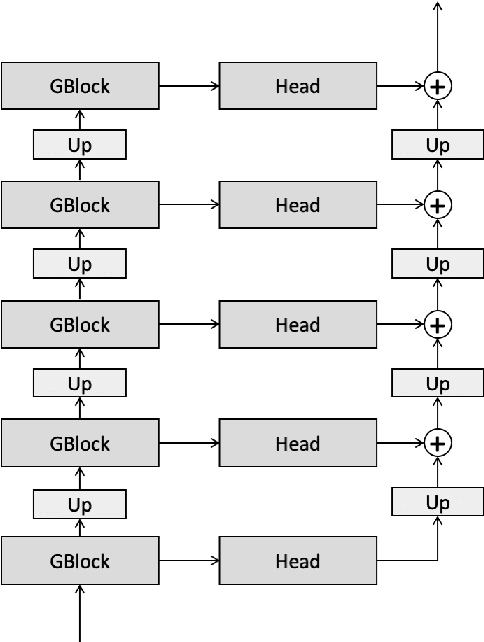
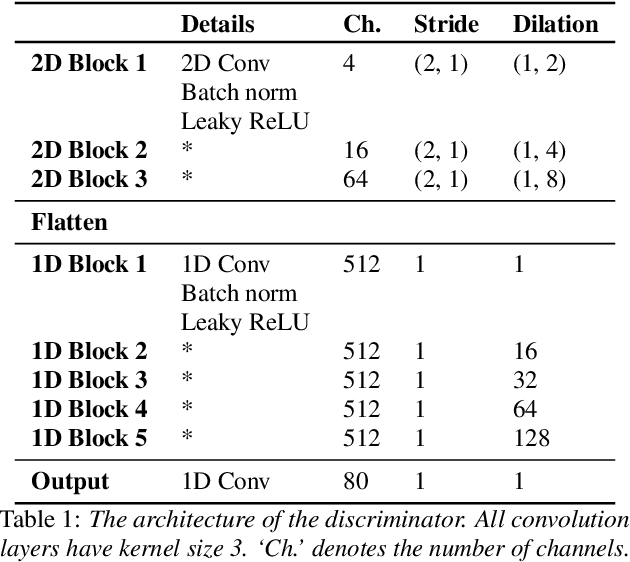
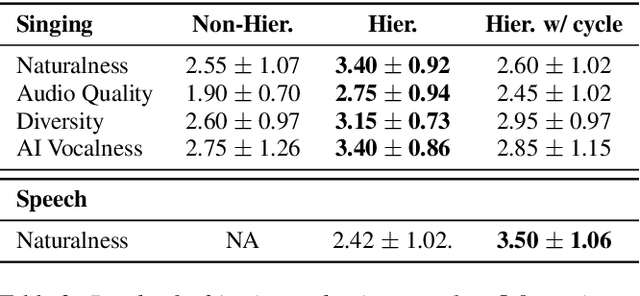
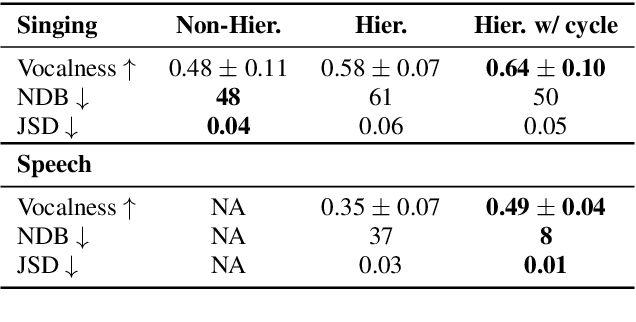
In a recent paper, we have presented a generative adversarial network (GAN)-based model for unconditional generation of the mel-spectrograms of singing voices. As the generator of the model is designed to take a variable-length sequence of noise vectors as input, it can generate mel-spectrograms of variable length. However, our previous listening test shows that the quality of the generated audio leaves room for improvement. The present paper extends and expands that previous work in the following aspects. First, we employ a hierarchical architecture in the generator to induce some structure in the temporal dimension. Second, we introduce a cycle regularization mechanism to the generator to avoid mode collapse. Third, we evaluate the performance of the new model not only for generating singing voices, but also for generating speech voices. Evaluation result shows that new model outperforms the prior one both objectively and subjectively. We also employ the model to unconditionally generate sequences of piano and violin music and find the result promising. Audio examples, as well as the code for implementing our model, will be publicly available online upon paper publication.