 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does Instrumental Music Help SingFake Detection?
Sep 18, 2025Although many models exist to detect singing voice deepfakes (SingFake), how these models operate, particularly with instrumental accompaniment, is unclear. We investigate how instrumental music affects SingFake detection from two perspectives. To investigate the behavioral effect, we test different backbones, unpaired instrumental tracks, and frequency subbands. To analyze the representational effect, we probe how fine-tuning alters encoders' speech and music capabilities. Our results show that instrumental accompaniment acts mainly as data augmentation rather than providing intrinsic cues (e.g., rhythm or harmony). Furthermore, fine-tuning increases reliance on shallow speaker features while reducing sensitivity to content, paralinguistic, and semantic information. These insights clarify how models exploit vocal versus instrumental cues and can inform the design of more interpretable and robust SingFake detection systems.
Towards Generalized Source Tracing for Codec-Based Deepfake Speech
Jun 08, 2025Recent attempts at source tracing for codec-based deepfake speech (CodecFake), generated by neural audio codec-based speech generation (CoSG) models, have exhibited suboptimal performance. However, how to train source tracing models using simulated CoSG data while maintaining strong performance on real CoSG-generated audio remains an open challenge. In this paper, we show that models trained solely on codec-resynthesized data tend to overfit to non-speech regions and struggle to generalize to unseen content. To mitigate these challenges, we introduce the Semantic-Acoustic Source Tracing Network (SASTNet), which jointly leverages Whisper for semantic feature encoding and Wav2vec2 with AudioMAE for acoustic feature encoding. Our proposed SASTNet achieves state-of-the-art performance on the CoSG test set of the CodecFake+ dataset, demonstrating its effectiveness for reliable source tracing.
Codec-Based Deepfake Source Tracing via Neural Audio Codec Taxonomy
May 19, 2025



Recent advances in neural audio codec-based speech generation (CoSG) models have produced remarkably realistic audio deepfakes. We refer to deepfake speech generated by CoSG systems as codec-based deepfake, or CodecFake. Although existing anti-spoofing research on CodecFake predominantly focuses on verifying the authenticity of audio samples, almost no attention was given to tracing the CoSG used in generating these deepfakes. In CodecFake generation, processes such as speech-to-unit encoding, discrete unit modeling, and unit-to-speech decoding are fundamentally based on neural audio codecs. Motivated by this, we introduce source tracing for CodecFake via neural audio codec taxonomy, which dissects neural audio codecs to trace CoSG. Our experimental results on the CodecFake+ dataset provide promising initial evidence for the feasibility of CodecFake source tracing while also highlighting several challenges that warrant further investigation.
Towards Generalizability to Tone and Content Variations in the Transcription of Amplifier Rendered Electric Guitar Audio
Apr 10, 2025Transcribing electric guitar recordings is challenging due to the scarcity of diverse datasets and the complex tone-related variations introduced by amplifiers, cabinets, and effect pedals. To address these issues, we introduce EGDB-PG, a novel dataset designed to capture a wide range of tone-related characteristics across various amplifier-cabinet configurations. In addition, we propose the Tone-informed Transformer (TIT), a Transformer-based transcription model enhanced with a tone embedding mechanism that leverages learned representations to improve the model's adaptability to tone-related nuances. Experiments demonstrate that TIT, trained on EGDB-PG, outperforms existing baselines across diverse amplifier types, with transcription accuracy improvements driven by the dataset's diversity and the tone embedding technique. Through detailed benchmarking and ablation studies, we evaluate the impact of tone augmentation, content augmentation, audio normalization, and tone embedding on transcription performance. This work advances electric guitar transcription by overcoming limitations in dataset diversity and tone modeling, providing a robust foundation for future research.
CodecFake-Omni: A Large-Scale Codec-based Deepfake Speech Dataset
Jan 14, 2025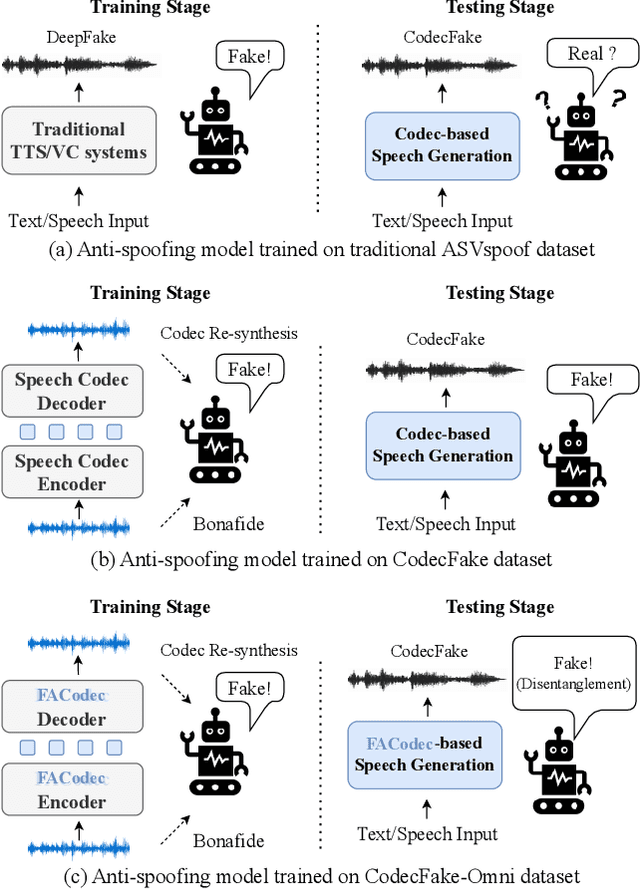
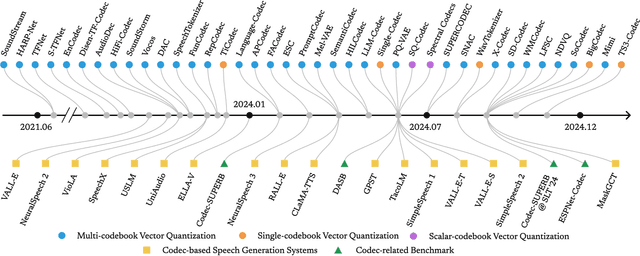

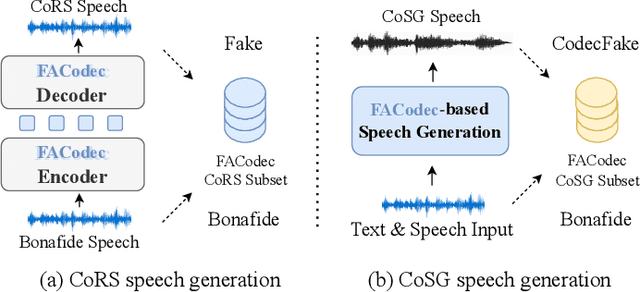
With the rapid advancement of codec-based speech generation (CoSG) systems, creating fake speech that mimics an individual's identity and spreads misinformation has become remarkably easy. Addressing the risks posed by such deepfake speech has attracted significant attention. However, most existing studies focus on detecting fake data generated by traditional speech generation models. Research on detecting fake speech generated by CoSG systems remains limited and largely unexplored. In this paper, we introduce CodecFake-Omni, a large-scale dataset specifically designed to advance the study of neural codec-based deepfake speech (CodecFake) detection and promote progress within the anti-spoofing community. To the best of our knowledge, CodecFake-Omni is the largest dataset of its kind till writing this paper, encompassing the most diverse range of codec architectures. The training set is generated through re-synthesis using nearly all publicly available open-source 31 neural audio codec models across 21 different codec families (one codec family with different configurations will result in multiple different codec models). The evaluation set includes web-sourced data collected from websites generated by 17 advanced CoSG models with eight codec families. Using this large-scale dataset, we reaffirm our previous findings that anti-spoofing models trained on traditional spoofing datasets generated by vocoders struggle to detect synthesized speech from current CoSG systems. Additionally, we propose a comprehensive neural audio codec taxonomy, categorizing neural audio codecs by their root components: vector quantizer, auxiliary objectives, and decoder types, with detailed explanations and representative examples for each. Using this comprehensive taxonomy, we conduct stratified analysis to provide valuable insights for future CodecFake detection research.
Knowledge Retrieval Based on Generative AI
Jan 08, 2025



This study develops a question-answering system based on Retrieval-Augmented Generation (RAG) using Chinese Wikipedia and Lawbank as retrieval sources. Using TTQA and TMMLU+ as evaluation datasets, the system employs BGE-M3 for dense vector retrieval to obtain highly relevant search results and BGE-reranker to reorder these results based on query relevance. The most pertinent retrieval outcomes serve as reference knowledge for a Large Language Model (LLM), enhancing its ability to answer questions and establishing a knowledge retrieval system grounded in generative AI. The system's effectiveness is assessed through a two-stage evaluation: automatic and assisted performance evaluations. The automatic evaluation calculates accuracy by comparing the model's auto-generated labels with ground truth answers, measuring performance under standardized conditions without human intervention. The assisted performance evaluation involves 20 finance-related multiple-choice questions answered by 20 participants without financial backgrounds. Initially, participants answer independently. Later, they receive system-generated reference information to assist in answering, examining whether the system improves accuracy when assistance is provided. The main contributions of this research are: (1) Enhanced LLM Capability: By integrating BGE-M3 and BGE-reranker, the system retrieves and reorders highly relevant results, reduces hallucinations, and dynamically accesses authorized or public knowledge sources. (2) Improved Data Privacy: A customized RAG architecture enables local operation of the LLM, eliminating the need to send private data to external servers. This approach enhances data security, reduces reliance on commercial services, lowers operational costs, and mitigates privacy risks.
Improving Location-based Thermal Emission Side-Channel Analysis Using Iterative Transfer Learning
Dec 30, 2024This paper proposes the use of iterative transfer learning applied to deep learning models for side-channel attacks. Currently, most of the side-channel attack methods train a model for each individual byte, without considering the correlation between bytes. However, since the models' parameters for attacking different bytes may be similar, we can leverage transfer learning, meaning that we first train the model for one of the key bytes, then use the trained model as a pretrained model for the remaining bytes. This technique can be applied iteratively, a process known as iterative transfer learning. Experimental results show that when using thermal or power consumption map images as input, and multilayer perceptron or convolutional neural network as the model, our method improves average performance, especially when the amount of data is insufficient.
Music2Fail: Transfer Music to Failed Recorder Style
Nov 27, 2024



The goal of music style transfer is to convert a music performance by one instrument into another while keeping the musical contents unchanged. In this paper, we investigate another style transfer scenario called ``failed-music style transfer''. Unlike the usual music style transfer where the content remains the same and only the instrumental characteristics are changed, this scenario seeks to transfer the music from the source instrument to the target instrument which is deliberately performed off-pitch. Our work attempts to transfer normally played music into off-pitch recorder music, which we call ``failed-style recorder'', and study the results of the conversion. To carry out this work, we have also proposed a dataset of failed-style recorders for this task, called ``FR109 Dataset''. Such an experiment explores the music style transfer task in a more expressive setting, as the generated audio should sound like an ``off-pitch recorder'' while maintaining a certain degree of naturalness.
BLAPose: Enhancing 3D Human Pose Estimation with Bone Length Adjustment
Oct 29, 2024



Current approaches in 3D human pose estimation primarily focus on regressing 3D joint locations, often neglecting critical physical constraints such as bone length consistency and body symmetry. This work introduces a recurrent neural network architecture designed to capture holistic information across entire video sequences, enabling accurate prediction of bone lengths. To enhance training effectiveness, we propose a novel augmentation strategy using synthetic bone lengths that adhere to physical constraints. Moreover, we present a bone length adjustment method that preserves bone orientations while substituting bone lengths with predicted values. Our results demonstrate that existing 3D human pose estimation models can be significantly enhanced through this adjustment process. Furthermore, we fine-tune human pose estimation models using inferred bone lengths, observing notable improvements. Our bone length prediction model surpasses the previous best results, and our adjustment and fine-tuning method enhance performance across several metrics on the Human3.6M dataset.
Demo of Zero-Shot Guitar Amplifier Modelling: Enhancing Modeling with Hyper Neural Networks
Oct 07, 2024
Electric guitar tone modeling typically focuses on the non-linear transformation from clean to amplifier-rendered audio. Traditional methods rely on one-to-one mappings, incorporating device parameters into neural models to replicate specific amplifiers. However, these methods are limited by the need for specific training data. In this paper, we adapt a model based on the previous work, which leverages a tone embedding encoder and a feature wise linear modulation (FiLM) condition method. In this work, we altered conditioning method using a hypernetwork-based gated convolutional network (GCN) to generate audio that blends clean input with the tone characteristics of reference audio. By extending the training data to cover a wider variety of amplifier tones, our model is able to capture a broader range of tones. Additionally, we developed a real-time plugin to demonstrate the system's practical application, allowing users to experience its performance interactively. Our results indicate that the proposed system achieves superior tone modeling versatility compared to traditional methods.