 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does Instrumental Music Help SingFake Detection?
Sep 18, 2025Although many models exist to detect singing voice deepfakes (SingFake), how these models operate, particularly with instrumental accompaniment, is unclear. We investigate how instrumental music affects SingFake detection from two perspectives. To investigate the behavioral effect, we test different backbones, unpaired instrumental tracks, and frequency subbands. To analyze the representational effect, we probe how fine-tuning alters encoders' speech and music capabilities. Our results show that instrumental accompaniment acts mainly as data augmentation rather than providing intrinsic cues (e.g., rhythm or harmony). Furthermore, fine-tuning increases reliance on shallow speaker features while reducing sensitivity to content, paralinguistic, and semantic information. These insights clarify how models exploit vocal versus instrumental cues and can inform the design of more interpretable and robust SingFake detection systems.
CodecFake-Omni: A Large-Scale Codec-based Deepfake Speech Dataset
Jan 14, 2025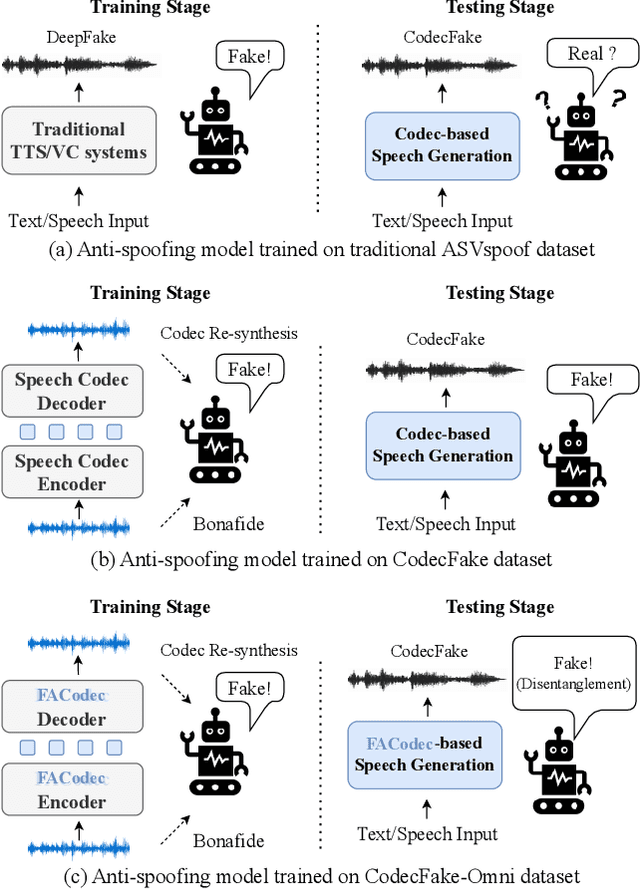
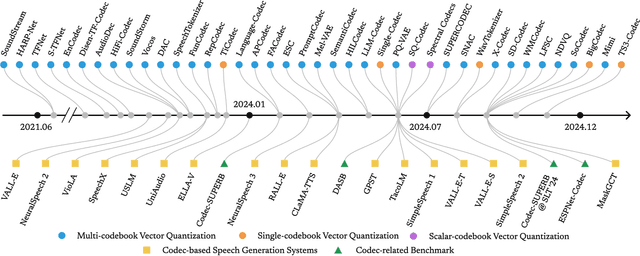

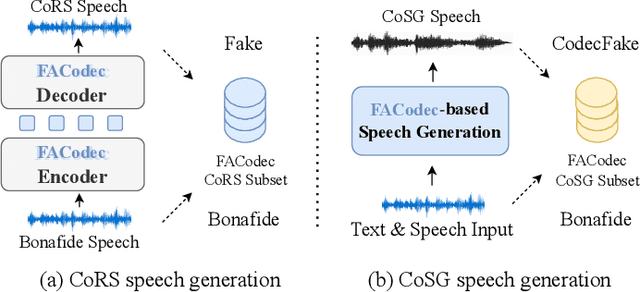
With the rapid advancement of codec-based speech generation (CoSG) systems, creating fake speech that mimics an individual's identity and spreads misinformation has become remarkably easy. Addressing the risks posed by such deepfake speech has attracted significant attention. However, most existing studies focus on detecting fake data generated by traditional speech generation models. Research on detecting fake speech generated by CoSG systems remains limited and largely unexplored. In this paper, we introduce CodecFake-Omni, a large-scale dataset specifically designed to advance the study of neural codec-based deepfake speech (CodecFake) detection and promote progress within the anti-spoofing community. To the best of our knowledge, CodecFake-Omni is the largest dataset of its kind till writing this paper, encompassing the most diverse range of codec architectures. The training set is generated through re-synthesis using nearly all publicly available open-source 31 neural audio codec models across 21 different codec families (one codec family with different configurations will result in multiple different codec models). The evaluation set includes web-sourced data collected from websites generated by 17 advanced CoSG models with eight codec families. Using this large-scale dataset, we reaffirm our previous findings that anti-spoofing models trained on traditional spoofing datasets generated by vocoders struggle to detect synthesized speech from current CoSG systems. Additionally, we propose a comprehensive neural audio codec taxonomy, categorizing neural audio codecs by their root components: vector quantizer, auxiliary objectives, and decoder types, with detailed explanations and representative examples for each. Using this comprehensive taxonomy, we conduct stratified analysis to provide valuable insights for future CodecFake detection research.
Building a Taiwanese Mandarin Spoken Language Model: A First Attempt
Nov 11, 2024



This technical report presents our initial attempt to build a spoken large language model (LLM) for Taiwanese Mandarin, specifically tailored to enable real-time, speech-to-speech interaction in multi-turn conversations. Our end-to-end model incorporates a decoder-only transformer architecture and aims to achieve seamless interaction while preserving the conversational flow, including full-duplex capabilities allowing simultaneous speaking and listening. The paper also details the training process, including data preparation with synthesized dialogues and adjustments for real-time interaction. We also developed a platform to evaluate conversational fluency and response coherence in multi-turn dialogues. We hope the release of the report can contribute to the future development of spoken LLMs in Taiwanese Mandarin.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
DFADD: The Diffusion and Flow-Matching Based Audio Deepfake Dataset
Sep 13, 2024



Mainstream zero-shot TTS production systems like Voicebox and Seed-TTS achieve human parity speech by leveraging Flow-matching and Diffusion models, respectively. Unfortunately, human-level audio synthesis leads to identity misuse and information security issues. Currently, many antispoofing models have been developed against deepfake audio. However, the efficacy of current state-of-the-art anti-spoofing models in countering audio synthesized by diffusion and flowmatching based TTS systems remains unknown. In this paper, we proposed the Diffusion and Flow-matching based Audio Deepfake (DFADD) dataset. The DFADD dataset collected the deepfake audio based on advanced diffusion and flowmatching TTS models. Additionally, we reveal that current anti-spoofing models lack sufficient robustness against highly human-like audio generated by diffusion and flow-matching TTS systems. The proposed DFADD dataset addresses this gap and provides a valuable resource for developing more resilient anti-spoofing models.
AV-SUPERB: A Multi-Task Evaluation Benchmark for Audio-Visual Representation Models
Sep 19, 2023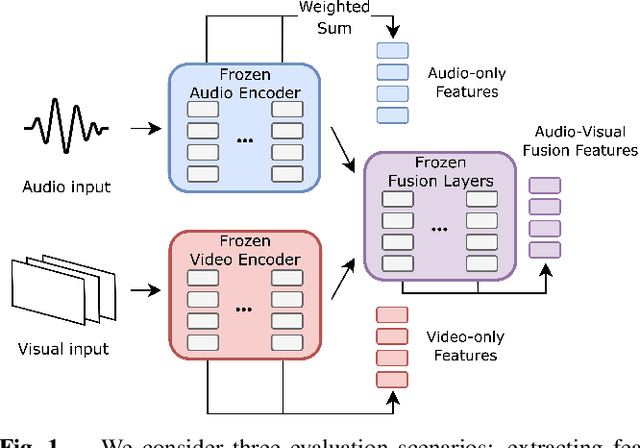
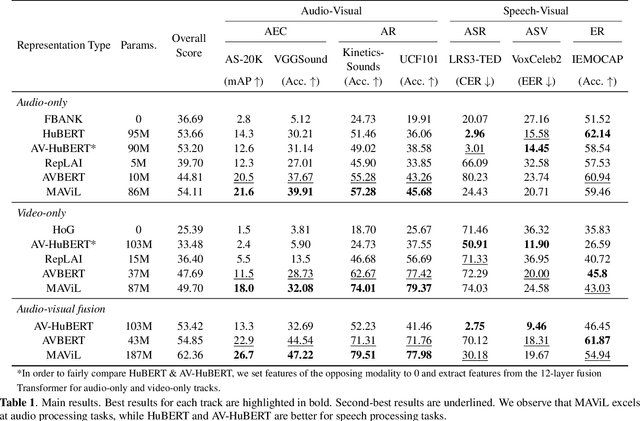
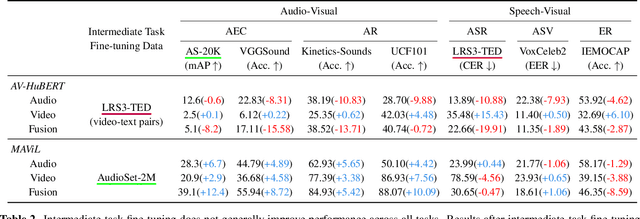
Audio-visual representation learning aims to develop systems with human-like perception by utilizing correlation between auditory and visual information. However, current models often focus on a limited set of tasks, and generalization abilities of learned representations are unclear. To this end, we propose the AV-SUPERB benchmark that enables general-purpose evaluation of unimodal audio/visual and bimodal fusion representations on 7 datasets covering 5 audio-visual tasks in speech and audio processing. We evaluate 5 recent self-supervised models and show that none of these models generalize to all tasks, emphasizing the need for future study on improving universal model performance. In addition, we show that representations may be improved with intermediate-task fine-tuning and audio event classification with AudioSet serves as a strong intermediate task. We release our benchmark with evaluation code and a model submission platform to encourage further research in audio-visual learning.