 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeSTA2.5-Audio: Toward General-Purpose Large Audio Language Model with Self-Generated Cross-Modal Alignment
Jul 03, 2025We introduce DeSTA2.5-Audio, a general-purpose Large Audio Language Model (LALM) designed for robust auditory perception and instruction-following, without requiring task-specific audio instruction-tuning. Recent LALMs typically augment Large Language Models (LLMs) with auditory capabilities by training on large-scale, manually curated or LLM-synthesized audio-instruction datasets. However, these approaches have often suffered from the catastrophic forgetting of the LLM's original language abilities. To address this, we revisit the data construction pipeline and propose DeSTA, a self-generated cross-modal alignment strategy in which the backbone LLM generates its own training targets. This approach preserves the LLM's native language proficiency while establishing effective audio-text alignment, thereby enabling zero-shot generalization without task-specific tuning. Using DeSTA, we construct DeSTA-AQA5M, a large-scale, task-agnostic dataset containing 5 million training samples derived from 7,000 hours of audio spanning 50 diverse datasets, including speech, environmental sounds, and music. DeSTA2.5-Audio achieves state-of-the-art or competitive performance across a wide range of audio-language benchmarks, including Dynamic-SUPERB, MMAU, SAKURA, Speech-IFEval, and VoiceBench. Comprehensive comparative studies demonstrate that our self-generated strategy outperforms widely adopted data construction and training strategies in both auditory perception and instruction-following capabilities. Our findings underscore the importance of carefully designed data construction in LALM development and offer practical insights for building robust, general-purpose LALMs.
AudioLens: A Closer Look at Auditory Attribute Perception of Large Audio-Language Models
Jun 05, 2025Understanding the internal mechanisms of large audio-language models (LALMs) is crucial for interpreting their behavior and improving performance. This work presents the first in-depth analysis of how LALMs internally perceive and recognize auditory attributes. By applying vocabulary projection on three state-of-the-art LALMs, we track how attribute information evolves across layers and token positions. We find that attribute information generally decreases with layer depth when recognition fails, and that resolving attributes at earlier layers correlates with better accuracy. Moreover, LALMs heavily rely on querying auditory inputs for predicting attributes instead of aggregating necessary information in hidden states at attribute-mentioning positions. Based on our findings, we demonstrate a method to enhance LALMs. Our results offer insights into auditory attribute processing, paving the way for future improvements.
Analyzing Mitigation Strategies for Catastrophic Forgetting in End-to-End Training of Spoken Language Models
May 23, 2025End-to-end training of Spoken Language Models (SLMs) commonly involves adapting pre-trained text-based Large Language Models (LLMs) to the speech modality through multi-stage training on diverse tasks such as ASR, TTS and spoken question answering (SQA). Although this multi-stage continual learning equips LLMs with both speech understanding and generation capabilities, the substantial differences in task and data distributions across stages can lead to catastrophic forgetting, where previously acquired knowledge is lost. This paper investigates catastrophic forgetting and evaluates three mitigation strategies-model merging, discounting the LoRA scaling factor, and experience replay to balance knowledge retention with new learning. Results show that experience replay is the most effective, with further gains achieved by combining it with other methods. These findings provide insights for developing more robust and efficient SLM training pipelines.
Towards Holistic Evaluation of Large Audio-Language Models: A Comprehensive Survey
May 21, 2025With advancements in large audio-language models (LALMs), which enhance large language models (LLMs) with auditory capabilities, these models are expected to demonstrate universal proficiency across various auditory tasks. While numerous benchmarks have emerged to assess LALMs' performance, they remain fragmented and lack a structured taxonomy. To bridge this gap, we conduct a comprehensive survey and propose a systematic taxonomy for LALM evaluations, categorizing them into four dimensions based on their objectives: (1) General Auditory Awareness and Processing, (2) Knowledge and Reasoning, (3) Dialogue-oriented Ability, and (4) Fairness, Safety, and Trustworthiness. We provide detailed overviews within each category and highlight challenges in this field, offering insights into promising future directions. To the best of our knowledge, this is the first survey specifically focused on the evaluations of LALMs, providing clear guidelines for the community. We will release the collection of the surveyed papers and actively maintain it to support ongoing advancements in the field.
SAKURA: On the Multi-hop Reasoning of Large Audio-Language Models Based on Speech and Audio Information
May 19, 2025Large audio-language models (LALMs) extend the large language models with multimodal understanding in speech, audio, etc. While their performances on speech and audio-processing tasks are extensively studied, their reasoning abilities remain underexplored. Particularly, their multi-hop reasoning, the ability to recall and integrate multiple facts, lacks systematic evaluation. Existing benchmarks focus on general speech and audio-processing tasks, conversational abilities, and fairness but overlook this aspect. To bridge this gap, we introduce SAKURA, a benchmark assessing LALMs' multi-hop reasoning based on speech and audio information. Results show that LALMs struggle to integrate speech/audio representations for multi-hop reasoning, even when they extract the relevant information correctly, highlighting a fundamental challenge in multimodal reasoning. Our findings expose a critical limitation in LALMs, offering insights and resources for future research.
Building a Taiwanese Mandarin Spoken Language Model: A First Attempt
Nov 11, 2024



This technical report presents our initial attempt to build a spoken large language model (LLM) for Taiwanese Mandarin, specifically tailored to enable real-time, speech-to-speech interaction in multi-turn conversations. Our end-to-end model incorporates a decoder-only transformer architecture and aims to achieve seamless interaction while preserving the conversational flow, including full-duplex capabilities allowing simultaneous speaking and listening. The paper also details the training process, including data preparation with synthesized dialogues and adjustments for real-time interaction. We also developed a platform to evaluate conversational fluency and response coherence in multi-turn dialogues. We hope the release of the report can contribute to the future development of spoken LLMs in Taiwanese Mandarin.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
Speech-Copilot: Leveraging Large Language Models for Speech Processing via Task Decomposition, Modularization, and Program Generation
Jul 13, 2024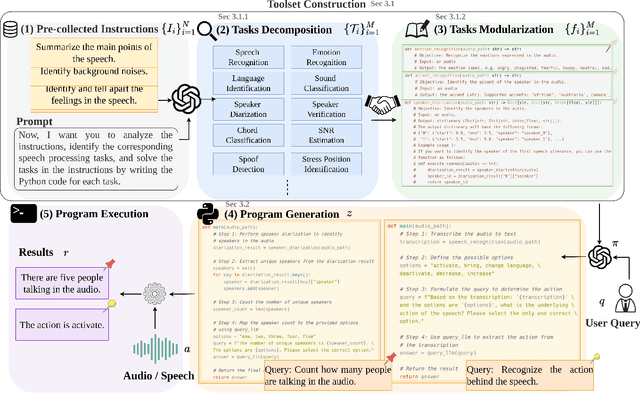
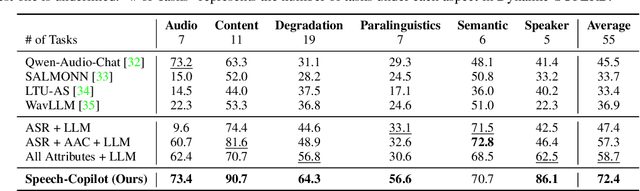


In this work, we introduce Speech-Copilot, a modular framework for instruction-oriented speech-processing tasks that minimizes human effort in toolset construction. Unlike end-to-end methods using large audio-language models, Speech-Copilot builds speech processing-specific toolsets by analyzing pre-collected task instructions and breaking tasks into manageable sub-tasks. It features a flexible agent based on large language models that performs tasks through program generation. Our approach achieves state-of-the-art performance on the Dynamic-SUPERB benchmark, demonstrating its effectiveness across diverse speech-processing tasks. Key contributions include: 1) developing an innovative framework for speech processing-specific toolset construction, 2) establishing a high-performing agent based on large language models, and 3) offering a new perspective on addressing challenging instruction-oriented speech-processing tasks. Without additional training processes required by end-to-end approaches, our method provides a flexible and extendable solution for a wide range of speech-processing applications.
Listen and Speak Fairly: A Study on Semantic Gender Bias in Speech Integrated Large Language Models
Jul 09, 2024Speech Integrated Large Language Models (SILLMs) combine large language models with speech perception to perform diverse tasks, such as emotion recognition to speaker verification, demonstrating universal audio understanding capability. However, these models may amplify biases present in training data, potentially leading to biased access to information for marginalized groups. This work introduces a curated spoken bias evaluation toolkit and corresponding dataset. We evaluate gender bias in SILLMs across four semantic-related tasks: speech-to-text translation (STT), spoken coreference resolution (SCR), spoken sentence continuation (SSC), and spoken question answering (SQA). Our analysis reveals that bias levels are language-dependent and vary with different evaluation methods. Our findings emphasize the necessity of employing multiple approaches to comprehensively assess biases in SILLMs, providing insights for developing fairer SILLM systems.
Do Prompts Really Prompt? Exploring the Prompt Understanding Capability of Whisper
Jun 09, 2024



This research explores the interaction between Whisper, a high-performing speech recognition model, and information in prompts. Our results unexpectedly show that Whisper may not fully grasp textual prompts as anticipated. Additionally, we find that performance improvement is not guaranteed even with stronger adherence to the topic information in textual prompts. It is also noted that English prompts generally outperform Mandarin ones on datasets of both languages, likely due to differences in training data distributions for these languages. Conversely, we discover that Whisper exhibits awareness of misleading information in language tokens by effectively ignoring incorrect language tokens and focusing on the correct ones. In summary, this work raises questions about Whisper's prompt understanding capability and encourages further studies.