 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeSTA2.5-Audio: Toward General-Purpose Large Audio Language Model with Self-Generated Cross-Modal Alignment
Jul 03, 2025
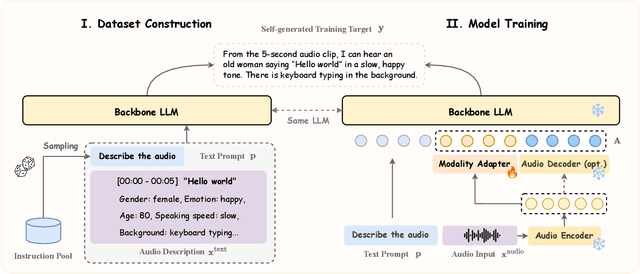


We introduce DeSTA2.5-Audio, a general-purpose Large Audio Language Model (LALM) designed for robust auditory perception and instruction-following, without requiring task-specific audio instruction-tuning. Recent LALMs typically augment Large Language Models (LLMs) with auditory capabilities by training on large-scale, manually curated or LLM-synthesized audio-instruction datasets. However, these approaches have often suffered from the catastrophic forgetting of the LLM's original language abilities. To address this, we revisit the data construction pipeline and propose DeSTA, a self-generated cross-modal alignment strategy in which the backbone LLM generates its own training targets. This approach preserves the LLM's native language proficiency while establishing effective audio-text alignment, thereby enabling zero-shot generalization without task-specific tuning. Using DeSTA, we construct DeSTA-AQA5M, a large-scale, task-agnostic dataset containing 5 million training samples derived from 7,000 hours of audio spanning 50 diverse datasets, including speech, environmental sounds, and music. DeSTA2.5-Audio achieves state-of-the-art or competitive performance across a wide range of audio-language benchmarks, including Dynamic-SUPERB, MMAU, SAKURA, Speech-IFEval, and VoiceBench. Comprehensive comparative studies demonstrate that our self-generated strategy outperforms widely adopted data construction and training strategies in both auditory perception and instruction-following capabilities. Our findings underscore the importance of carefully designed data construction in LALM development and offer practical insights for building robust, general-purpose LALMs.
Enhancing Multilingual ASR for Unseen Languages via Language Embedding Modeling
Dec 21, 2024

Multilingual Automatic Speech Recognition (ASR) aims to recognize and transcribe speech from multiple languages within a single system. Whisper, one of the most advanced ASR models, excels in this domain by handling 99 languages effectively, leveraging a vast amount of data and incorporating language tags as prefixes to guide the recognition process. However, despite its success, Whisper struggles with unseen languages, those not included in its pre-training. Motivated by the observation that many languages share linguistic characteristics, we propose methods that exploit these relationships to enhance ASR performance on unseen languages. Specifically, we introduce a weighted sum method, which computes a weighted sum of the embeddings of language tags, using Whisper's predicted language probabilities. In addition, we develop a predictor-based approach that refines the weighted sum embedding to more closely approximate the true embedding for unseen languages. Experimental results demonstrate substantial improvements in ASR performance, both in zero-shot and fine-tuning settings. Our proposed methods outperform baseline approaches, providing an effective solution for addressing unseen languages in multilingual ASR.
How to Learn a New Language? An Efficient Solution for Self-Supervised Learning Models Unseen Languages Adaption in Low-Resource Scenario
Nov 27, 2024



The utilization of speech Self-Supervised Learning (SSL) models achieves impressive performance on Automatic Speech Recognition (ASR). However, in low-resource language ASR, they encounter the domain mismatch problem between pre-trained and low-resource languages. Typical solutions like fine-tuning the SSL model suffer from high computation costs while using frozen SSL models as feature extractors comes with poor performance. To handle these issues, we extend a conventional efficient fine-tuning scheme based on the adapter. We add an extra intermediate adaptation to warm up the adapter and downstream model initialization. Remarkably, we update only 1-5% of the total model parameters to achieve the adaptation. Experimental results on the ML-SUPERB dataset show that our solution outperforms conventional efficient fine-tuning. It achieves up to a 28% relative improvement in the Character/Phoneme error rate when adapting to unseen languages.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
Do Prompts Really Prompt? Exploring the Prompt Understanding Capability of Whisper
Jun 09, 2024



This research explores the interaction between Whisper, a high-performing speech recognition model, and information in prompts. Our results unexpectedly show that Whisper may not fully grasp textual prompts as anticipated. Additionally, we find that performance improvement is not guaranteed even with stronger adherence to the topic information in textual prompts. It is also noted that English prompts generally outperform Mandarin ones on datasets of both languages, likely due to differences in training data distributions for these languages. Conversely, we discover that Whisper exhibits awareness of misleading information in language tokens by effectively ignoring incorrect language tokens and focusing on the correct ones. In summary, this work raises questions about Whisper's prompt understanding capability and encourages further studies.
Dataset-Distillation Generative Model for Speech Emotion Recognition
Jun 05, 2024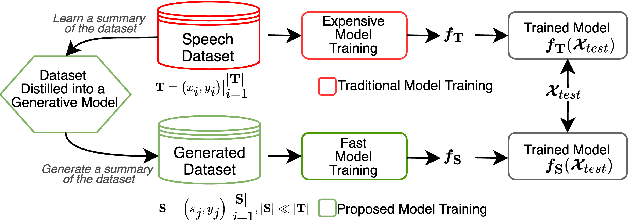

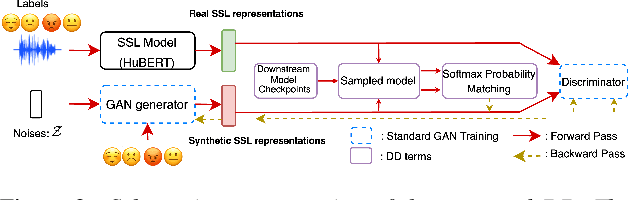
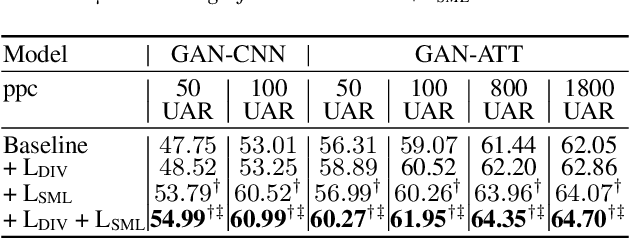
Deep learning models for speech rely on large datasets, presenting computational challenges. Yet, performance hinges on training data size. Dataset Distillation (DD) aims to learn a smaller dataset without much performance degradation when training with it. DD has been investigated in computer vision but not yet in speech. This paper presents the first approach for DD to speech targeting Speech Emotion Recognition on IEMOCAP. We employ Generative Adversarial Networks (GANs) not to mimic real data but to distil key discriminative information of IEMOCAP that is useful for downstream training. The GAN then replaces the original dataset and can sample custom synthetic dataset sizes. It performs comparably when following the original class imbalance but improves performance by 0.3% absolute UAR with balanced classes. It also reduces dataset storage and accelerates downstream training by 95% in both cases and reduces speaker information which could help for a privacy application.
Investigating Zero-Shot Generalizability on Mandarin-English Code-Switched ASR and Speech-to-text Translation of Recent Foundation Models with Self-Supervision and Weak Supervision
Dec 30, 2023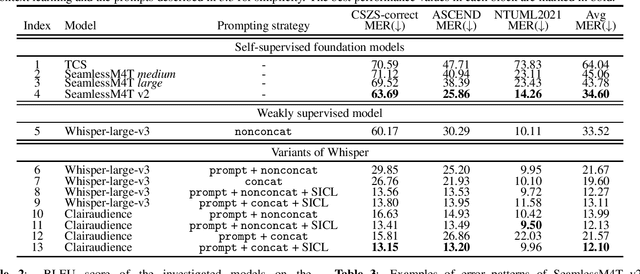

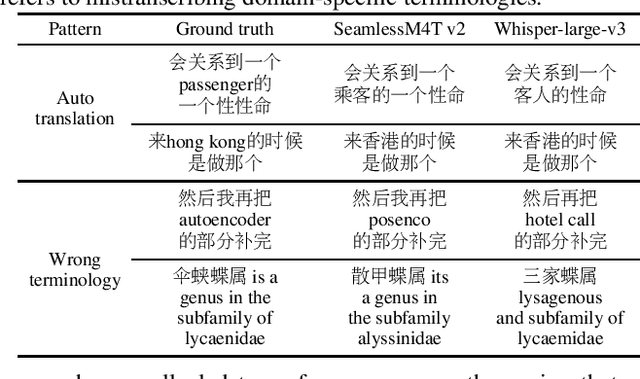
This work evaluated several cutting-edge large-scale foundation models based on self-supervision or weak supervision, including SeamlessM4T, SeamlessM4T v2, and Whisper-large-v3, on three code-switched corpora. We found that self-supervised models can achieve performances close to the supervised model, indicating the effectiveness of multilingual self-supervised pre-training. We also observed that these models still have room for improvement as they kept making similar mistakes and had unsatisfactory performances on modeling intra-sentential code-switching. In addition, the validity of several variants of Whisper was explored, and we concluded that they remained effective in a code-switching scenario, and similar techniques for self-supervised models are worth studying to boost the performance of code-switched tasks.
Noise robust distillation of self-supervised speech models via correlation metrics
Dec 19, 2023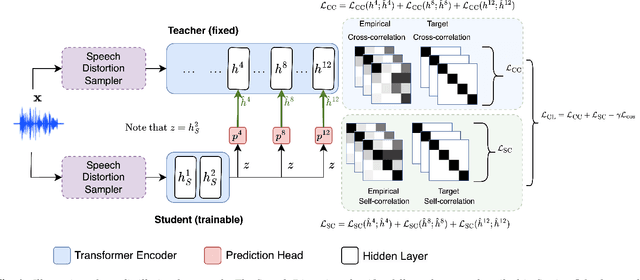
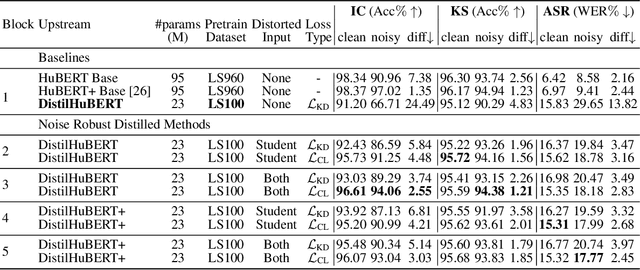

Compared to large speech foundation models, small distilled models exhibit degraded noise robustness. The student's robustness can be improved by introducing noise at the inputs during pre-training. Despite this, using the standard distillation loss still yields a student with degraded performance. Thus, this paper proposes improving student robustness via distillation with correlation metrics. Teacher behavior is learned by maximizing the teacher and student cross-correlation matrix between their representations towards identity. Noise robustness is encouraged via the student's self-correlation minimization. The proposed method is agnostic of the teacher model and consistently outperforms the previous approach. This work also proposes an heuristic to weigh the importance of the two correlation terms automatically. Experiments show consistently better clean and noise generalization on Intent Classification, Keyword Spotting, and Automatic Speech Recognition tasks on SUPERB Challenge.
Zero Resource Code-switched Speech Benchmark Using Speech Utterance Pairs For Multiple Spoken Languages
Oct 04, 2023
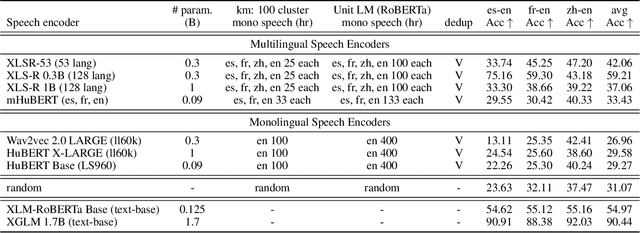
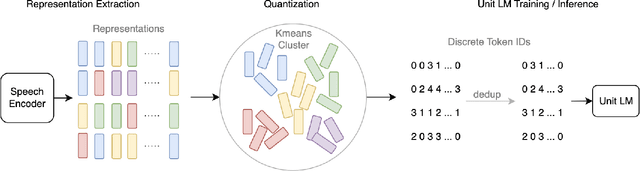
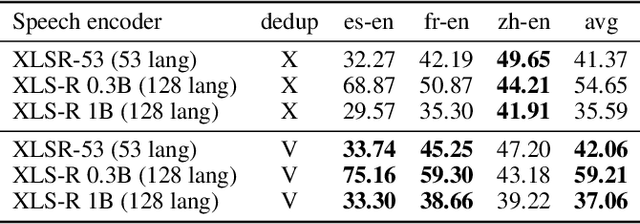
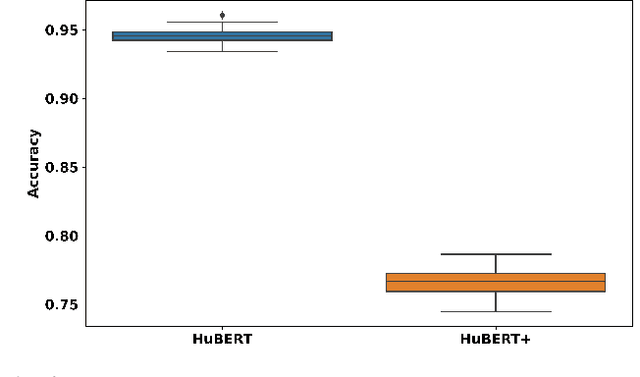
We introduce a new zero resource code-switched speech benchmark designed to directly assess the code-switching capabilities of self-supervised speech encoders. We showcase a baseline system of language modeling on discrete units to demonstrate how the code-switching abilities of speech encoders can be assessed in a zero-resource manner. Our experiments encompass a variety of well-known speech encoders, including Wav2vec 2.0, HuBERT, XLSR, etc. We examine the impact of pre-training languages and model size on benchmark performance. Notably, though our results demonstrate that speech encoders with multilingual pre-training, exemplified by XLSR, outperform monolingual variants (Wav2vec 2.0, HuBERT) in code-switching scenarios, there is still substantial room for improvement in their code-switching linguistic abilities.
Ensemble knowledge distillation of self-supervised speech models
Feb 24, 2023

Distilled self-supervised models have shown competitive performance and efficiency in recent years. However, there is a lack of experience in jointly distilling multiple self-supervised speech models. In our work, we performed Ensemble Knowledge Distillation (EKD) on various self-supervised speech models such as HuBERT, RobustHuBERT, and WavLM. We tried two different aggregation techniques, layerwise-average and layerwise-concatenation, to the representations of different teacher models and found that the former was more effective. On top of that, we proposed a multiple prediction head method for student models to predict different layer outputs of multiple teacher models simultaneously. The experimental results show that our method improves the performance of the distilled models on four downstream speech processing tasks, Phoneme Recognition, Speaker Identification, Emotion Recognition, and Automatic Speech Recognition in the hidden-set track of the SUPERB benchmark.