 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Audio Reasoning in Multimodal Foundation Models
May 20, 2026Reasoning has become a defining capability of modern foundation models, yet its development in the audio modality remains limited. Audio poses challenges that are distinct from those of text and vision. It is continuous, temporally dense, and contains linguistic, paralinguistic, and environmental information at multiple time scales. As a result, audio reasoning models must align acoustic signals with the discrete semantic space of large language models, while still preserving fine-grained information needed for reliable inference. Progress is also limited by three major obstacles: the scarcity of genuinely audio-grounded reasoning data, shortcut learning and modality hallucination, and the tension between reasoning depth and real-time latency in spoken interaction. In this paper, we present the first dedicated survey of audio reasoning. We provide a unified formulation that distinguishes direct predictive modeling from reasoning-augmented generation, review the architectural and training foundations of audio reasoning models, and systematically organize recent advances in Audio-to-Text, Audio-to-Speech, Audio-Visual Reasoning and Agentic Audio Reasoning. We further examine emerging paradigms such as Chain-of-Thought prompting, supervised fine-tuning, reinforcement learning, and latency-aware spoken interaction, and discuss evaluation practices, open challenges, and future directions. Our goal is to offer a coherent roadmap for developing robust, efficient, and natively grounded audio reasoning systems.
ASPIRin: Action Space Projection for Interactivity-Optimized Reinforcement Learning in Full-Duplex Speech Language Models
Apr 11, 2026End-to-end full-duplex Speech Language Models (SLMs) require precise turn-taking for natural interaction. However, optimizing temporal dynamics via standard raw-token reinforcement learning (RL) degrades semantic quality, causing severe generative collapse and repetition. We propose ASPIRin, an interactivity-optimized RL framework that explicitly decouples when to speak from what to say. Using Action Space Projection, ASPIRin maps the text vocabulary into a coarse-grained binary state (active speech vs. inactive silence). By applying Group Relative Policy Optimization (GRPO) with rule-based rewards, it balances user interruption and response latency. Empirical evaluations show ASPIRin optimizes interactivity across turn-taking, backchanneling, and pause handling. Crucially, isolating timing from token selection preserves semantic coherence and reduces the portion of duplicate n-grams by over 50% compared to standard GRPO, effectively eliminating degenerative repetition.
Full-Duplex-Bench-v3: Benchmarking Tool Use for Full-Duplex Voice Agents Under Real-World Disfluency
Apr 06, 2026We introduce Full-Duplex-Bench-v3 (FDB-v3), a benchmark for evaluating spoken language models under naturalistic speech conditions and multi-step tool use. Unlike prior work, our dataset consists entirely of real human audio annotated for five disfluency categories, paired with scenarios requiring chained API calls across four task domains. We evaluate six model configurations -- GPT-Realtime, Gemini Live 2.5, Gemini Live 3.1, Grok, Ultravox v0.7, and a traditional Cascaded pipeline (Whisper$\rightarrow$GPT-4o$\rightarrow$TTS) -- across accuracy, latency, and turn-taking dimensions. GPT-Realtime leads on Pass@1 (0.600) and interruption avoidance (13.5\%); Gemini Live 3.1 achieves the fastest latency (4.25~s) but the lowest turn-take rate (78.0\%); and the Cascaded baseline, despite a perfect turn-take rate, incurs the highest latency (10.12~s). Across all systems, self-correction handling and multi-step reasoning under hard scenarios remain the most consistent failure modes.
Full-Duplex-Bench-v2: A Multi-Turn Evaluation Framework for Duplex Dialogue Systems with an Automated Examiner
Oct 09, 2025While full-duplex speech agents enable natural, low-latency interaction by speaking and listening simultaneously, their consistency and task performance in multi-turn settings remain underexplored. We introduce Full-Duplex-Bench-v2 (FDB-v2), a streaming framework that integrates with an automated examiner that enforces staged goals under two pacing setups (Fast vs. Slow). FDB-v2 covers four task families: daily, correction, entity tracking, and safety. We report turn-taking fluency, multi-turn instruction following, and task-specific competence. The framework is extensible, supporting both commercial APIs and open source models. When we test full-duplex systems with FDB-v2, they often get confused when people talk at the same time, struggle to handle corrections smoothly, and sometimes lose track of who or what is being talked about. Through an open-sourced, standardized streaming protocol and a task set, FDB-v2 makes it easy to extend to new task families, allowing the community to tailor and accelerate evaluation of multi-turn full-duplex systems.
EMO-Reasoning: Benchmarking Emotional Reasoning Capabilities in Spoken Dialogue Systems
Aug 25, 2025Speech emotions play a crucial role in human-computer interaction, shaping engagement and context-aware communication. Despite recent advances in spoken dialogue systems, a holistic system for evaluating emotional reasoning is still lacking. To address this, we introduce EMO-Reasoning, a benchmark for assessing emotional coherence in dialogue systems. It leverages a curated dataset generated via text-to-speech to simulate diverse emotional states, overcoming the scarcity of emotional speech data. We further propose the Cross-turn Emotion Reasoning Score to assess the emotion transitions in multi-turn dialogues. Evaluating seven dialogue systems through continuous, categorical, and perceptual metrics, we show that our framework effectively detects emotional inconsistencies, providing insights for improving current dialogue systems. By releasing a systematic evaluation benchmark, we aim to advance emotion-aware spoken dialogue modeling toward more natural and adaptive interactions.
Full-Duplex-Bench: A Benchmark to Evaluate Full-duplex Spoken Dialogue Models on Turn-taking Capabilities
Mar 06, 2025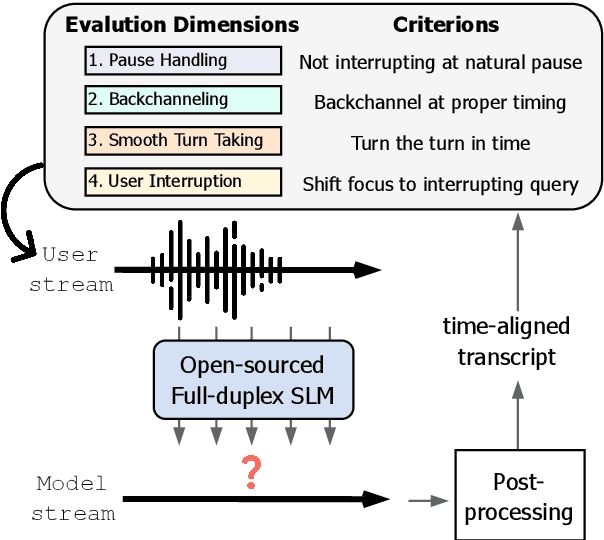
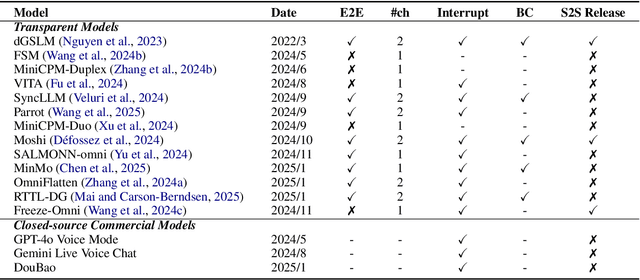
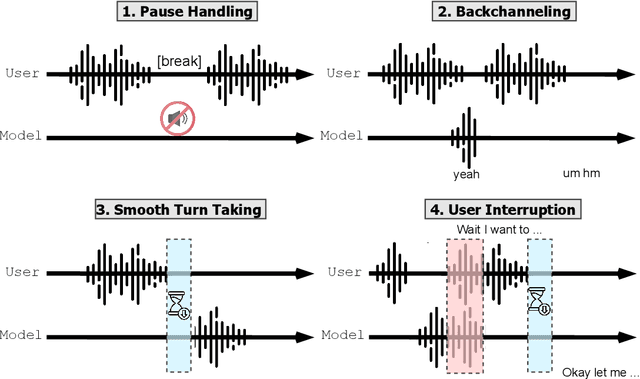

Spoken dialogue modeling introduces unique challenges beyond text-based language modeling, demanding robust turn-taking, backchanneling, and real-time interaction. Although most Spoken Dialogue Models (SDMs) rely on half-duplex processing (handling speech one turn at a time), emerging full-duplex SDMs can listen and speak simultaneously, enabling more natural and engaging conversations. However, current evaluations of such models remain limited, often focusing on turn-based metrics or high-level corpus analyses (e.g., turn gaps, pauses). To address this gap, we present Full-Duplex-Bench, a new benchmark that systematically evaluates key conversational behaviors: pause handling, backchanneling, turn-taking, and interruption management. Our framework uses automatic metrics for consistent and reproducible assessments of SDMs' interactive performance. By offering an open and standardized evaluation benchmark, we aim to advance spoken dialogue modeling and encourage the development of more interactive and natural dialogue systems.
How to Learn a New Language? An Efficient Solution for Self-Supervised Learning Models Unseen Languages Adaption in Low-Resource Scenario
Nov 27, 2024



The utilization of speech Self-Supervised Learning (SSL) models achieves impressive performance on Automatic Speech Recognition (ASR). However, in low-resource language ASR, they encounter the domain mismatch problem between pre-trained and low-resource languages. Typical solutions like fine-tuning the SSL model suffer from high computation costs while using frozen SSL models as feature extractors comes with poor performance. To handle these issues, we extend a conventional efficient fine-tuning scheme based on the adapter. We add an extra intermediate adaptation to warm up the adapter and downstream model initialization. Remarkably, we update only 1-5% of the total model parameters to achieve the adaptation. Experimental results on the ML-SUPERB dataset show that our solution outperforms conventional efficient fine-tuning. It achieves up to a 28% relative improvement in the Character/Phoneme error rate when adapting to unseen languages.
Align-SLM: Textless Spoken Language Models with Reinforcement Learning from AI Feedback
Nov 04, 2024



While textless Spoken Language Models (SLMs) have shown potential in end-to-end speech-to-speech modeling, they still lag behind text-based Large Language Models (LLMs) in terms of semantic coherence and relevance. This work introduces the Align-SLM framework, which leverages preference optimization inspired by Reinforcement Learning with AI Feedback (RLAIF) to enhance the semantic understanding of SLMs. Our approach generates multiple speech continuations from a given prompt and uses semantic metrics to create preference data for Direct Preference Optimization (DPO). We evaluate the framework using ZeroSpeech 2021 benchmarks for lexical and syntactic modeling, the spoken version of the StoryCloze dataset for semantic coherence, and other speech generation metrics, including the GPT4-o score and human evaluation. Experimental results show that our method achieves state-of-the-art performance for SLMs on most benchmarks, highlighting the importance of preference optimization to improve the semantics of SLMs.
Property Neurons in Self-Supervised Speech Transformers
Sep 07, 2024



There have been many studies on analyzing self-supervised speech Transformers, in particular, with layer-wise analysis. It is, however, desirable to have an approach that can pinpoint exactly a subset of neurons that is responsible for a particular property of speech, being amenable to model pruning and model editing. In this work, we identify a set of property neurons in the feedforward layers of Transformers to study how speech-related properties, such as phones, gender, and pitch, are stored. When removing neurons of a particular property (a simple form of model editing), the respective downstream performance significantly degrades, showing the importance of the property neurons. We apply this approach to pruning the feedforward layers in Transformers, where most of the model parameters are. We show that protecting property neurons during pruning is significantly more effective than norm-based pruning.
Continual Test-time Adaptation for End-to-end Speech Recognition on Noisy Speech
Jun 16, 2024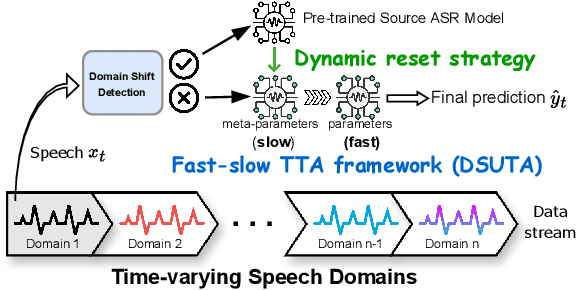
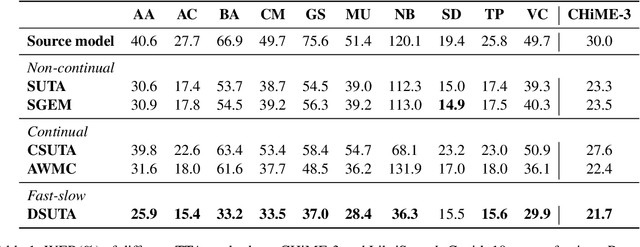
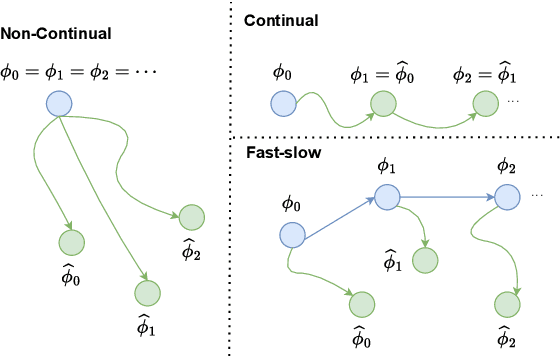
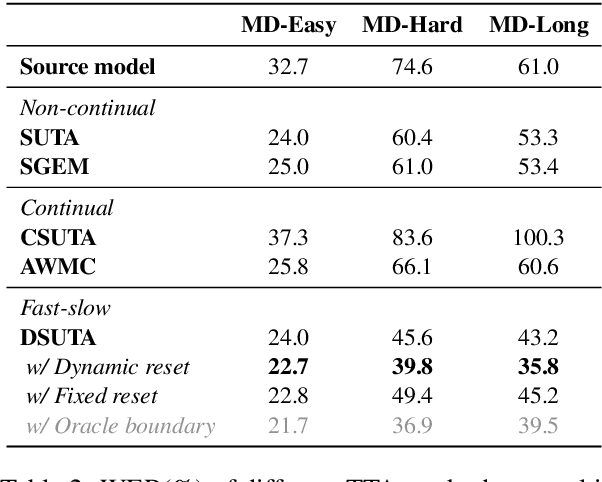
Deep learning-based end-to-end automatic speech recognition (ASR) has made significant strides but still struggles with performance on out-of-domain (OOD) samples due to domain shifts in real-world scenarios. Test-Time Adaptation (TTA) methods address this issue by adapting models using test samples at inference time. However, current ASR TTA methods have largely focused on non-continual TTA, which limits cross-sample knowledge learning compared to continual TTA. In this work, we propose a Fast-slow TTA framework for ASR, which leverages the advantage of continual and non-continual TTA. Within this framework, we introduce Dynamic SUTA (DSUTA), an entropy-minimization-based continual TTA method for ASR. To enhance DSUTA's robustness on time-varying data, we propose a dynamic reset strategy that automatically detects domain shifts and resets the model, making it more effective at handling multi-domain data. Our method demonstrates superior performance on various noisy ASR datasets, outperforming both non-continual and continual TTA baselines while maintaining robustness to domain changes without requiring domain boundary information.