 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Auditory Knowledge in LLM Backbones Shapes Audio Language Models: A Holistic Evaluation
Mar 19, 2026Large language models (LLMs) have been widely used as knowledge backbones of Large Audio Language Models (LALMs), yet how much auditory knowledge they encode through text-only pre-training and how this affects downstream performance remains unclear. We study this gap by comparing different LLMs under two text-only and one audio-grounded setting: (1) direct probing on AKB-2000, a curated benchmark testing the breadth and depth of auditory knowledge; (2) cascade evaluation, where LLMs reason over text descriptions from an audio captioner; and (3) audio-grounded evaluation, where each LLM is fine-tuned into a Large Audio Language Model (LALM) with an audio encoder. Our findings reveal that auditory knowledge varies substantially across families, and text-only results are strongly correlated with audio performance. Our work provides empirical grounding for a comprehensive understanding of LLMs in audio research.
SPAR-K: Scheduled Periodic Alternating Early Exit for Spoken Language Models
Mar 10, 2026Interleaved spoken language models (SLMs) alternately generate text and speech tokens, but decoding at full transformer depth for every step becomes costly, especially due to long speech sequences. We propose SPAR-K, a modality-aware early exit framework designed to accelerate interleaved SLM inference while preserving perceptual quality. SPAR-K introduces a speech alternating-depth schedule: most speech positions exit at a fixed intermediate layer, while periodic full-depth "refresh" steps mitigate distribution shift due to early exit. We evaluate our framework using Step-Audio-2-mini and GLM-4-Voice across four datasets spanning reasoning, factual QA, and dialogue tasks, measuring performance in terms of ASR transcription accuracy and perceptual quality. Experimental results demonstrate that SPAR-K largely preserves question-answering accuracy with a maximum accuracy drop of 0.82\% while reducing average speech decoding depth by up to 11\% on Step-Audio-2-mini and 5\% on GLM-4-Voice, both with negligible changes in MOS and WER and no auxiliary computation overhead. We further demonstrate that confidence-based early exit strategies, widely used in text LLMs, are suboptimal for SLMs, highlighting that the unique statistical nature of speech tokens necessitates a specialized early exit design.
Style Amnesia: Investigating Speaking Style Degradation and Mitigation in Multi-Turn Spoken Language Models
Dec 29, 2025In this paper, we show that when spoken language models (SLMs) are instructed to speak in a specific speaking style at the beginning of a multi-turn conversation, they cannot maintain the required speaking styles after several turns of interaction; we refer to this as the style amnesia of SLMs. We focus on paralinguistic speaking styles, including emotion, accent, volume, and speaking speed. We evaluate three proprietary and two open-source SLMs, demonstrating that none of these models can maintain a consistent speaking style when instructed to do so. We further show that when SLMs are asked to recall the style instruction in later turns, they can recall the style instruction, but they fail to express it throughout the conversation. We also show that explicitly asking the model to recall the style instruction can partially mitigate style amnesia. In addition, we examine various prompting strategies and find that SLMs struggle to follow the required style when the instruction is placed in system messages rather than user messages, which contradicts the intended function of system prompts.
SHANKS: Simultaneous Hearing and Thinking for Spoken Language Models
Oct 08, 2025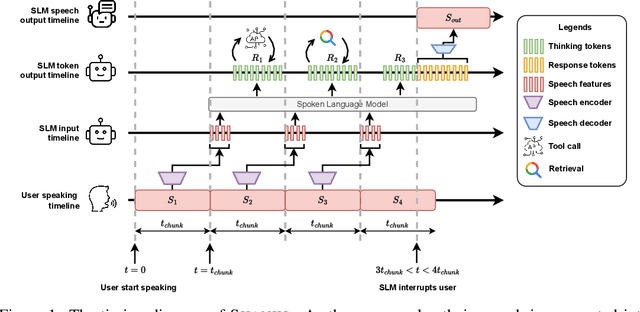
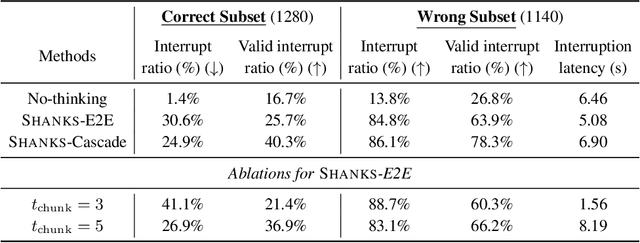

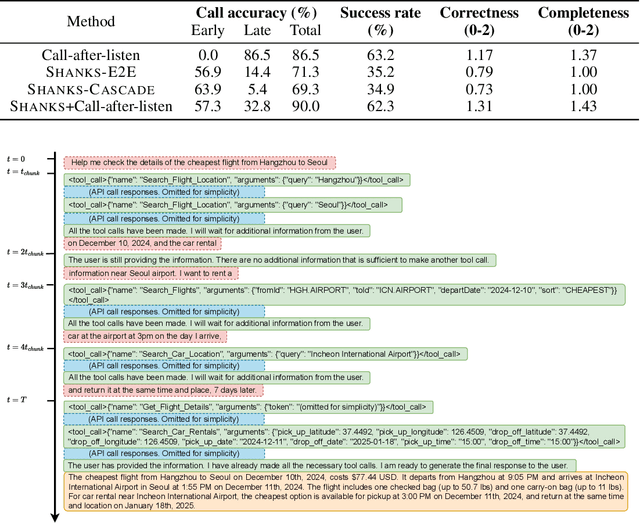
Current large language models (LLMs) and spoken language models (SLMs) begin thinking and taking actions only after the user has finished their turn. This prevents the model from interacting during the user's turn and can lead to high response latency while it waits to think. Consequently, thinking after receiving the full input is not suitable for speech-to-speech interaction, where real-time, low-latency exchange is important. We address this by noting that humans naturally "think while listening." In this paper, we propose SHANKS, a general inference framework that enables SLMs to generate unspoken chain-of-thought reasoning while listening to the user input. SHANKS streams the input speech in fixed-duration chunks and, as soon as a chunk is received, generates unspoken reasoning based on all previous speech and reasoning, while the user continues speaking. SHANKS uses this unspoken reasoning to decide whether to interrupt the user and to make tool calls to complete the task. We demonstrate that SHANKS enhances real-time user-SLM interaction in two scenarios: (1) when the user is presenting a step-by-step solution to a math problem, SHANKS can listen, reason, and interrupt when the user makes a mistake, achieving 37.1% higher interruption accuracy than a baseline that interrupts without thinking; and (2) in a tool-augmented dialogue, SHANKS can complete 56.9% of the tool calls before the user finishes their turn. Overall, SHANKS moves toward models that keep thinking throughout the conversation, not only after a turn ends. Animated illustrations of Shanks can be found at https://d223302.github.io/SHANKS/
DeSTA2.5-Audio: Toward General-Purpose Large Audio Language Model with Self-Generated Cross-Modal Alignment
Jul 03, 2025
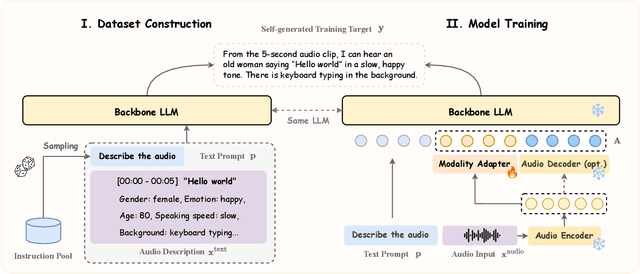


We introduce DeSTA2.5-Audio, a general-purpose Large Audio Language Model (LALM) designed for robust auditory perception and instruction-following, without requiring task-specific audio instruction-tuning. Recent LALMs typically augment Large Language Models (LLMs) with auditory capabilities by training on large-scale, manually curated or LLM-synthesized audio-instruction datasets. However, these approaches have often suffered from the catastrophic forgetting of the LLM's original language abilities. To address this, we revisit the data construction pipeline and propose DeSTA, a self-generated cross-modal alignment strategy in which the backbone LLM generates its own training targets. This approach preserves the LLM's native language proficiency while establishing effective audio-text alignment, thereby enabling zero-shot generalization without task-specific tuning. Using DeSTA, we construct DeSTA-AQA5M, a large-scale, task-agnostic dataset containing 5 million training samples derived from 7,000 hours of audio spanning 50 diverse datasets, including speech, environmental sounds, and music. DeSTA2.5-Audio achieves state-of-the-art or competitive performance across a wide range of audio-language benchmarks, including Dynamic-SUPERB, MMAU, SAKURA, Speech-IFEval, and VoiceBench. Comprehensive comparative studies demonstrate that our self-generated strategy outperforms widely adopted data construction and training strategies in both auditory perception and instruction-following capabilities. Our findings underscore the importance of carefully designed data construction in LALM development and offer practical insights for building robust, general-purpose LALMs.
Reducing Object Hallucination in Large Audio-Language Models via Audio-Aware Decoding
Jun 08, 2025Large Audio-Language Models (LALMs) can take audio and text as the inputs and answer questions about the audio. While prior LALMs have shown strong performance on standard benchmarks, there has been alarming evidence that LALMs can hallucinate what is presented in the audio. To mitigate the hallucination of LALMs, we introduce Audio-Aware Decoding (AAD), a lightweight inference-time strategy that uses contrastive decoding to compare the token prediction logits with and without the audio context. By contrastive decoding, AAD promotes the tokens whose probability increases when the audio is present. We conduct our experiment on object hallucination datasets with three LALMs and show that AAD improves the F1 score by 0.046 to 0.428. We also show that AAD can improve the accuracy on general audio QA datasets like Clotho-AQA by 5.4% to 10.3%. We conduct thorough ablation studies to understand the effectiveness of each component in AAD.
Audio-Aware Large Language Models as Judges for Speaking Styles
Jun 06, 2025Audio-aware large language models (ALLMs) can understand the textual and non-textual information in the audio input. In this paper, we explore using ALLMs as an automatic judge to assess the speaking styles of speeches. We use ALLM judges to evaluate the speeches generated by SLMs on two tasks: voice style instruction following and role-playing. The speaking style we consider includes emotion, volume, speaking pace, word emphasis, pitch control, and non-verbal elements. We use four spoken language models (SLMs) to complete the two tasks and use humans and ALLMs to judge the SLMs' responses. We compare two ALLM judges, GPT-4o-audio and Gemini-2.5-pro, with human evaluation results and show that the agreement between Gemini and human judges is comparable to the agreement between human evaluators. These promising results show that ALLMs can be used as a judge to evaluate SLMs. Our results also reveal that current SLMs, even GPT-4o-audio, still have room for improvement in controlling the speaking style and generating natural dialogues.
TRACT: Regression-Aware Fine-tuning Meets Chain-of-Thought Reasoning for LLM-as-a-Judge
Mar 06, 2025The LLM-as-a-judge paradigm uses large language models (LLMs) for automated text evaluation, where a numerical assessment is assigned by an LLM to the input text following scoring rubrics. Existing methods for LLM-as-a-judge use cross-entropy (CE) loss for fine-tuning, which neglects the numeric nature of score prediction. Recent work addresses numerical prediction limitations of LLM fine-tuning through regression-aware fine-tuning, which, however, does not consider chain-of-thought (CoT) reasoning for score prediction. In this paper, we introduce TRACT (Two-stage Regression-Aware fine-tuning with CoT), a method combining CoT reasoning with regression-aware training. TRACT consists of two stages: first, seed LLM is fine-tuned to generate CoTs, which serve as supervision for the second stage fine-tuning. The training objective of TRACT combines the CE loss for learning the CoT reasoning capabilities, and the regression-aware loss for the score prediction. Experiments across four LLM-as-a-judge datasets and two LLMs show that TRACT significantly outperforms existing methods. Extensive ablation studies validate the importance of each component in TRACT.
Large Language Model as an Assignment Evaluator: Insights, Feedback, and Challenges in a 1000+ Student Course
Jul 07, 2024



Using large language models (LLMs) for automatic evaluation has become an important evaluation method in NLP research. However, it is unclear whether these LLM-based evaluators can be applied in real-world classrooms to assess student assignments. This empirical report shares how we use GPT-4 as an automatic assignment evaluator in a university course with 1,028 students. Based on student responses, we find that LLM-based assignment evaluators are generally acceptable to students when students have free access to these LLM-based evaluators. However, students also noted that the LLM sometimes fails to adhere to the evaluation instructions. Additionally, we observe that students can easily manipulate the LLM-based evaluator to output specific strings, allowing them to achieve high scores without meeting the assignment rubric. Based on student feedback and our experience, we provide several recommendations for integrating LLM-based evaluators into future classrooms.
Merging Facts, Crafting Fallacies: Evaluating the Contradictory Nature of Aggregated Factual Claims in Long-Form Generations
Feb 23, 2024



Long-form generations from large language models (LLMs) contains a mix of factual and non-factual claims, making evaluating factuality difficult. To evaluate factual precision of long-form generations in a more fine-grained way, prior works propose to decompose long-form generations into multiple verifiable facts and verify those facts independently. The factuality of the generation is the proportion of verifiable facts among all the facts. Such methods assume that combining factual claims forms a factual paragraph. This paper shows that the assumption can be violated due to entity ambiguity. We show that LLMs can generate paragraphs that contain verifiable facts, but the facts are combined to form a non-factual paragraph due to entity ambiguity. We further reveal that existing factual precision metrics, including FActScore and citation recall, cannot properly evaluate the factuality of these non-factual paragraphs. To address this, we introduce an enhanced metric, D-FActScore, specifically designed for content with ambiguous entities. We evaluate the D-FActScores of people biographies generated with retrieval-augmented generation (RAG). We show that D-FActScore can better assess the factuality of paragraphs with entity ambiguity than FActScore. We also find that four widely used open-source LLMs tend to mix information of distinct entities to form non-factual paragraphs.