 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalking Through Uncertainty: An Empirical Study of Uncertainty Estimation for Audio-Aware Large Language Models
Apr 28, 2026Recent audio-aware large language models (ALLMs) have demonstrated strong capabilities across diverse audio understanding and reasoning tasks, but they still frequently produce hallucinated or overly confident outputs. While uncertainty estimation has been extensively studied in text-only LLMs, it remains largely unexplored for ALLMs, where audio-conditioned generation introduces additional challenges such as perceptual ambiguity and cross-modal grounding. In this work, we present the first systematic empirical study of uncertainty estimation in ALLMs. We benchmark five representative methods, including predictive entropy, length-normalized entropy, semantic entropy, discrete semantic entropy, and P(True), across multiple models and diverse evaluation settings spanning general audio understanding, reasoning, hallucination detection, and unanswerable question answering. Our results reveal two key findings. First, semantic-level and verification-based methods consistently outperform token-level baselines on general audio reasoning benchmarks. Second, on trustworthiness-oriented benchmarks, the relative effectiveness of uncertainty methods becomes notably more model- and benchmark-dependent, indicating that conclusions drawn from general reasoning settings do not straightforwardly transfer to hallucination and unanswerable-question scenarios. We further explore uncertainty-based adaptive inference as a potential downstream application. We hope this study provides a foundation for future research on reliable, uncertainty-aware audio-language systems.
AQAScore: Evaluating Semantic Alignment in Text-to-Audio Generation via Audio Question Answering
Jan 21, 2026Although text-to-audio generation has made remarkable progress in realism and diversity, the development of evaluation metrics has not kept pace. Widely-adopted approaches, typically based on embedding similarity like CLAPScore, effectively measure general relevance but remain limited in fine-grained semantic alignment and compositional reasoning. To address this, we introduce AQAScore, a backbone-agnostic evaluation framework that leverages the reasoning capabilities of audio-aware large language models (ALLMs). AQAScore reformulates assessment as a probabilistic semantic verification task; rather than relying on open-ended text generation, it estimates alignment by computing the exact log-probability of a "Yes" answer to targeted semantic queries. We evaluate AQAScore across multiple benchmarks, including human-rated relevance, pairwise comparison, and compositional reasoning tasks. Experimental results show that AQAScore consistently achieves higher correlation with human judgments than similarity-based metrics and generative prompting baselines, showing its effectiveness in capturing subtle semantic inconsistencies and scaling with the capability of underlying ALLMs.
AQUA-Bench: Beyond Finding Answers to Knowing When There Are None in Audio Question Answering
Jan 18, 2026Recent advances in audio-aware large language models have shown strong performance on audio question answering. However, existing benchmarks mainly cover answerable questions and overlook the challenge of unanswerable ones, where no reliable answer can be inferred from the audio. Such cases are common in real-world settings, where questions may be misleading, ill-posed, or incompatible with the information. To address this gap, we present AQUA-Bench, a benchmark for Audio Question Unanswerability Assessment. It systematically evaluates three scenarios: Absent Answer Detection (the correct option is missing), Incompatible Answer Set Detection (choices are categorically mismatched with the question), and Incompatible Audio Question Detection (the question is irrelevant or lacks sufficient grounding in the audio). By assessing these cases, AQUA-Bench offers a rigorous measure of model reliability and promotes the development of audio-language systems that are more robust and trustworthy. Our experiments suggest that while models excel on standard answerable tasks, they often face notable challenges with unanswerable ones, pointing to a blind spot in current audio-language understanding.
DeSTA2.5-Audio: Toward General-Purpose Large Audio Language Model with Self-Generated Cross-Modal Alignment
Jul 03, 2025
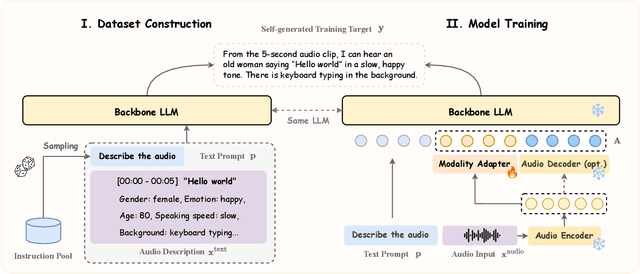


We introduce DeSTA2.5-Audio, a general-purpose Large Audio Language Model (LALM) designed for robust auditory perception and instruction-following, without requiring task-specific audio instruction-tuning. Recent LALMs typically augment Large Language Models (LLMs) with auditory capabilities by training on large-scale, manually curated or LLM-synthesized audio-instruction datasets. However, these approaches have often suffered from the catastrophic forgetting of the LLM's original language abilities. To address this, we revisit the data construction pipeline and propose DeSTA, a self-generated cross-modal alignment strategy in which the backbone LLM generates its own training targets. This approach preserves the LLM's native language proficiency while establishing effective audio-text alignment, thereby enabling zero-shot generalization without task-specific tuning. Using DeSTA, we construct DeSTA-AQA5M, a large-scale, task-agnostic dataset containing 5 million training samples derived from 7,000 hours of audio spanning 50 diverse datasets, including speech, environmental sounds, and music. DeSTA2.5-Audio achieves state-of-the-art or competitive performance across a wide range of audio-language benchmarks, including Dynamic-SUPERB, MMAU, SAKURA, Speech-IFEval, and VoiceBench. Comprehensive comparative studies demonstrate that our self-generated strategy outperforms widely adopted data construction and training strategies in both auditory perception and instruction-following capabilities. Our findings underscore the importance of carefully designed data construction in LALM development and offer practical insights for building robust, general-purpose LALMs.
From Alignment to Advancement: Bootstrapping Audio-Language Alignment with Synthetic Data
May 26, 2025Audio-aware large language models (ALLMs) have recently made great strides in understanding and processing audio inputs. These models are typically adapted from text-based large language models (LLMs) through additional training on audio-related tasks. However, this adaptation process presents two major limitations. First, ALLMs often suffer from catastrophic forgetting, where important textual capabilities such as instruction-following are lost after training on audio data. In some cases, models may even hallucinate sounds that are not present in the input audio, raising concerns about their reliability. Second, achieving cross-modal alignment between audio and language typically relies on large collections of task-specific question-answer pairs for instruction tuning, making the process resource-intensive. To address these issues, we leverage the backbone LLMs from ALLMs to synthesize general-purpose caption-style alignment data. We refer to this process as bootstrapping audio-language alignment via synthetic data generation from backbone LLMs (BALSa). Building on BALSa, we introduce LISTEN (Learning to Identify Sounds Through Extended Negative Samples), a contrastive-like training method designed to improve ALLMs' ability to distinguish between present and absent sounds. We further extend BALSa to multi-audio scenarios, where the model either explains the differences between audio inputs or produces a unified caption that describes them all, thereby enhancing audio-language alignment. Experimental results indicate that our method effectively mitigates audio hallucinations while reliably maintaining strong performance in audio understanding, reasoning, and instruction-following skills. Moreover, incorporating multi-audio training further enhances the model's comprehension and reasoning capabilities. Overall, BALSa offers an efficient and scalable approach to the development of ALLMs.
Speech-IFEval: Evaluating Instruction-Following and Quantifying Catastrophic Forgetting in Speech-Aware Language Models
May 25, 2025We introduce Speech-IFeval, an evaluation framework designed to assess instruction-following capabilities and quantify catastrophic forgetting in speech-aware language models (SLMs). Recent SLMs integrate speech perception with large language models (LLMs), often degrading textual capabilities due to speech-centric training. Existing benchmarks conflate speech perception with instruction-following, hindering evaluation of these distinct skills. To address this gap, we provide a benchmark for diagnosing the instruction-following abilities of SLMs. Our findings show that most SLMs struggle with even basic instructions, performing far worse than text-based LLMs. Additionally, these models are highly sensitive to prompt variations, often yielding inconsistent and unreliable outputs. We highlight core challenges and provide insights to guide future research, emphasizing the need for evaluation beyond task-level metrics.
Teaching Audio-Aware Large Language Models What Does Not Hear: Mitigating Hallucinations through Synthesized Negative Samples
May 20, 2025



Recent advancements in audio-aware large language models (ALLMs) enable them to process and understand audio inputs. However, these models often hallucinate non-existent sound events, reducing their reliability in real-world applications. To address this, we propose LISTEN (Learning to Identify Sounds Through Extended Negative Samples), a contrastive-like training method that enhances ALLMs' ability to distinguish between present and absent sounds using synthesized data from the backbone LLM. Unlike prior approaches, our method requires no modification to LLM parameters and efficiently integrates audio representations via a lightweight adapter. Experiments show that LISTEN effectively mitigates hallucinations while maintaining impressive performance on existing audio question and reasoning benchmarks. At the same time, it is more efficient in both data and computation.
Gender Bias in Instruction-Guided Speech Synthesis Models
Feb 08, 2025



Recent advancements in controllable expressive speech synthesis, especially in text-to-speech (TTS) models, have allowed for the generation of speech with specific styles guided by textual descriptions, known as style prompts. While this development enhances the flexibility and naturalness of synthesized speech, there remains a significant gap in understanding how these models handle vague or abstract style prompts. This study investigates the potential gender bias in how models interpret occupation-related prompts, specifically examining their responses to instructions like "Act like a nurse". We explore whether these models exhibit tendencies to amplify gender stereotypes when interpreting such prompts. Our experimental results reveal the model's tendency to exhibit gender bias for certain occupations. Moreover, models of different sizes show varying degrees of this bias across these occupations.
Building a Taiwanese Mandarin Spoken Language Model: A First Attempt
Nov 11, 2024



This technical report presents our initial attempt to build a spoken large language model (LLM) for Taiwanese Mandarin, specifically tailored to enable real-time, speech-to-speech interaction in multi-turn conversations. Our end-to-end model incorporates a decoder-only transformer architecture and aims to achieve seamless interaction while preserving the conversational flow, including full-duplex capabilities allowing simultaneous speaking and listening. The paper also details the training process, including data preparation with synthesized dialogues and adjustments for real-time interaction. We also developed a platform to evaluate conversational fluency and response coherence in multi-turn dialogues. We hope the release of the report can contribute to the future development of spoken LLMs in Taiwanese Mandarin.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.