 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASPIRin: Action Space Projection for Interactivity-Optimized Reinforcement Learning in Full-Duplex Speech Language Models
Apr 11, 2026End-to-end full-duplex Speech Language Models (SLMs) require precise turn-taking for natural interaction. However, optimizing temporal dynamics via standard raw-token reinforcement learning (RL) degrades semantic quality, causing severe generative collapse and repetition. We propose ASPIRin, an interactivity-optimized RL framework that explicitly decouples when to speak from what to say. Using Action Space Projection, ASPIRin maps the text vocabulary into a coarse-grained binary state (active speech vs. inactive silence). By applying Group Relative Policy Optimization (GRPO) with rule-based rewards, it balances user interruption and response latency. Empirical evaluations show ASPIRin optimizes interactivity across turn-taking, backchanneling, and pause handling. Crucially, isolating timing from token selection preserves semantic coherence and reduces the portion of duplicate n-grams by over 50% compared to standard GRPO, effectively eliminating degenerative repetition.
Building a Taiwanese Mandarin Spoken Language Model: A First Attempt
Nov 11, 2024



This technical report presents our initial attempt to build a spoken large language model (LLM) for Taiwanese Mandarin, specifically tailored to enable real-time, speech-to-speech interaction in multi-turn conversations. Our end-to-end model incorporates a decoder-only transformer architecture and aims to achieve seamless interaction while preserving the conversational flow, including full-duplex capabilities allowing simultaneous speaking and listening. The paper also details the training process, including data preparation with synthesized dialogues and adjustments for real-time interaction. We also developed a platform to evaluate conversational fluency and response coherence in multi-turn dialogues. We hope the release of the report can contribute to the future development of spoken LLMs in Taiwanese Mandarin.
Investigating the Effects of Large-Scale Pseudo-Stereo Data and Different Speech Foundation Model on Dialogue Generative Spoken Language Model
Jul 02, 2024


Recent efforts in Spoken Dialogue Modeling aim to synthesize spoken dialogue without the need for direct transcription, thereby preserving the wealth of non-textual information inherent in speech. However, this approach faces a challenge when speakers talk simultaneously, requiring stereo dialogue data with speakers recorded on separate channels, a notably scarce resource. To address this, we have developed an innovative pipeline capable of transforming single-channel dialogue data into pseudo-stereo data. This expanded our training dataset from a mere 2,000 to an impressive 17,600 hours, significantly enriching the diversity and quality of the training examples available. The inclusion of this pseudo-stereo data has proven to be effective in improving the performance of spoken dialogue language models. Additionally, we explored the use of discrete units of different speech foundation models for spoken dialogue generation.
Zero Resource Code-switched Speech Benchmark Using Speech Utterance Pairs For Multiple Spoken Languages
Oct 04, 2023
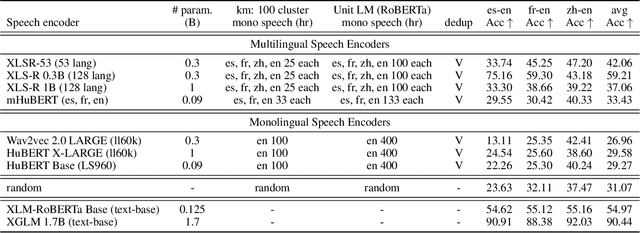
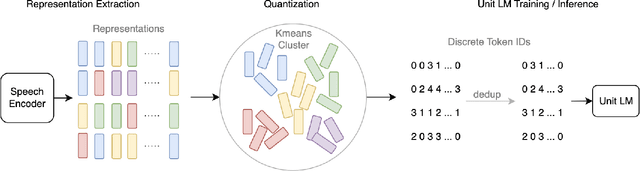
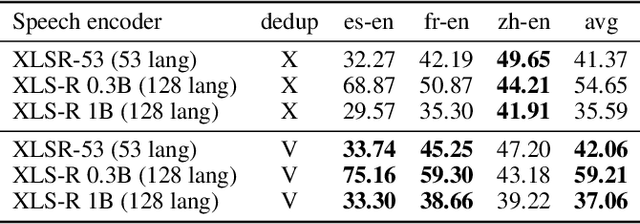
We introduce a new zero resource code-switched speech benchmark designed to directly assess the code-switching capabilities of self-supervised speech encoders. We showcase a baseline system of language modeling on discrete units to demonstrate how the code-switching abilities of speech encoders can be assessed in a zero-resource manner. Our experiments encompass a variety of well-known speech encoders, including Wav2vec 2.0, HuBERT, XLSR, etc. We examine the impact of pre-training languages and model size on benchmark performance. Notably, though our results demonstrate that speech encoders with multilingual pre-training, exemplified by XLSR, outperform monolingual variants (Wav2vec 2.0, HuBERT) in code-switching scenarios, there is still substantial room for improvement in their code-switching linguistic abilities.
Improving Cascaded Unsupervised Speech Translation with Denoising Back-translation
May 12, 2023



Most of the speech translation models heavily rely on parallel data, which is hard to collect especially for low-resource languages. To tackle this issue, we propose to build a cascaded speech translation system without leveraging any kind of paired data. We use fully unpaired data to train our unsupervised systems and evaluate our results on CoVoST 2 and CVSS. The results show that our work is comparable with some other early supervised methods in some language pairs. While cascaded systems always suffer from severe error propagation problems, we proposed denoising back-translation (DBT), a novel approach to building robust unsupervised neural machine translation (UNMT). DBT successfully increases the BLEU score by 0.7--0.9 in all three translation directions. Moreover, we simplified the pipeline of our cascaded system to reduce inference latency and conducted a comprehensive analysis of every part of our work. We also demonstrate our unsupervised speech translation results on the established website.
Ensemble knowledge distillation of self-supervised speech models
Feb 24, 2023

Distilled self-supervised models have shown competitive performance and efficiency in recent years. However, there is a lack of experience in jointly distilling multiple self-supervised speech models. In our work, we performed Ensemble Knowledge Distillation (EKD) on various self-supervised speech models such as HuBERT, RobustHuBERT, and WavLM. We tried two different aggregation techniques, layerwise-average and layerwise-concatenation, to the representations of different teacher models and found that the former was more effective. On top of that, we proposed a multiple prediction head method for student models to predict different layer outputs of multiple teacher models simultaneously. The experimental results show that our method improves the performance of the distilled models on four downstream speech processing tasks, Phoneme Recognition, Speaker Identification, Emotion Recognition, and Automatic Speech Recognition in the hidden-set track of the SUPERB benchmark.
Improving generalizability of distilled self-supervised speech processing models under distorted settings
Oct 20, 2022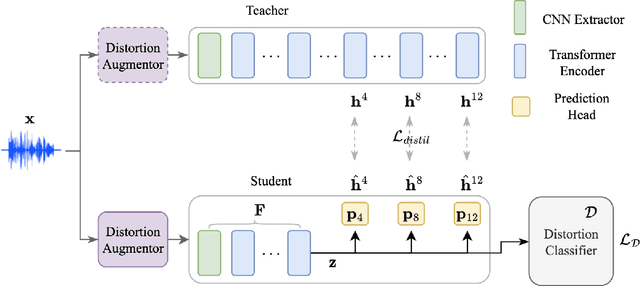
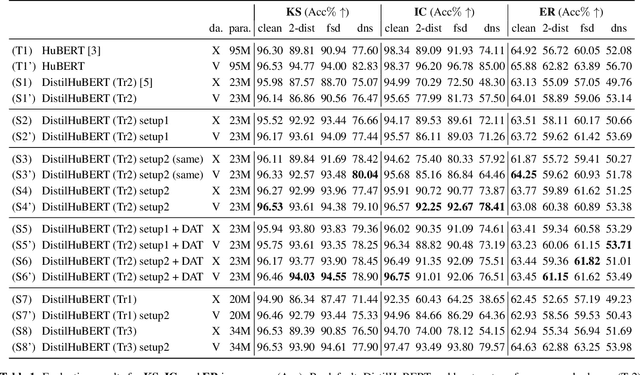
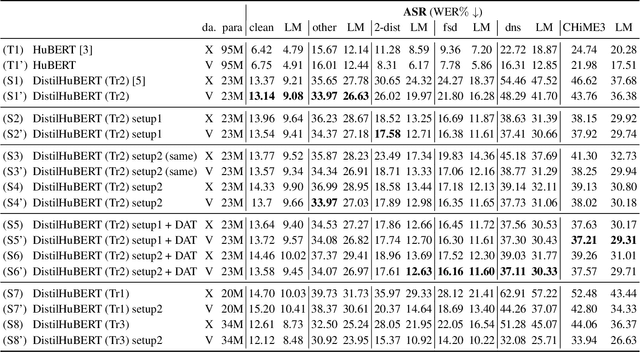
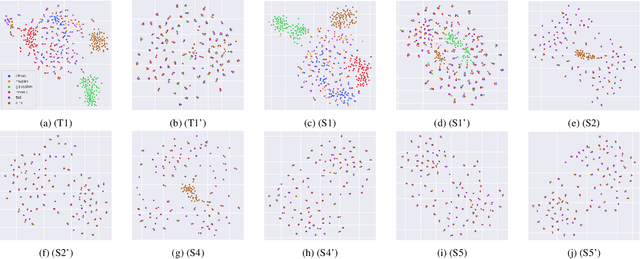
Self-supervised learned (SSL) speech pre-trained models perform well across various speech processing tasks. Distilled versions of SSL models have been developed to match the needs of on-device speech applications. Though having similar performance as original SSL models, distilled counterparts suffer from performance degradation even more than their original versions in distorted environments. This paper proposes to apply Cross-Distortion Mapping and Domain Adversarial Training to SSL models during knowledge distillation to alleviate the performance gap caused by the domain mismatch problem. Results show consistent performance improvements under both in- and out-of-domain distorted setups for different downstream tasks while keeping efficient model size.
Improving Distortion Robustness of Self-supervised Speech Processing Tasks with Domain Adaptation
Mar 30, 2022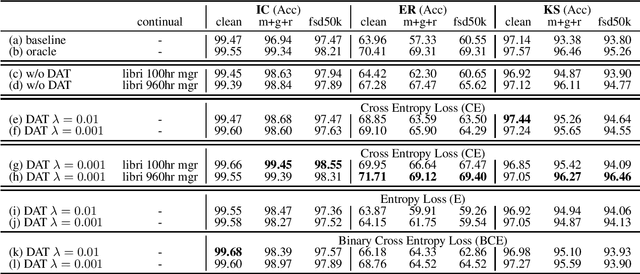
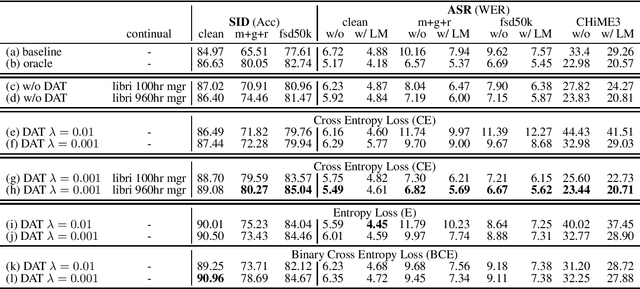
Speech distortions are a long-standing problem that degrades the performance of supervisely trained speech processing models. It is high time that we enhance the robustness of speech processing models to obtain good performance when encountering speech distortions while not hurting the original performance on clean speech. In this work, we propose to improve the robustness of speech processing models by domain adversarial training (DAT). We conducted experiments based on the SUPERB framework on five different speech processing tasks. In case we do not always have knowledge of the distortion types for speech data, we analyzed the binary-domain and multi-domain settings, where the former treats all distorted speech as one domain, and the latter views different distortions as different domains. In contrast to supervised training methods, we obtained promising results in target domains where speech data is distorted with different distortions including new unseen distortions introduced during testing.
Mandarin-English Code-switching Speech Recognition with Self-supervised Speech Representation Models
Oct 07, 2021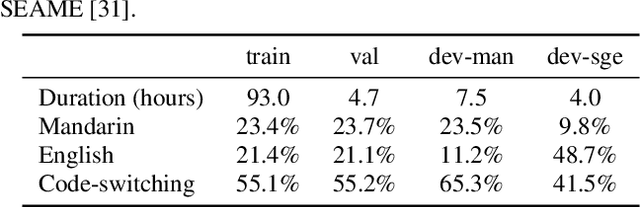
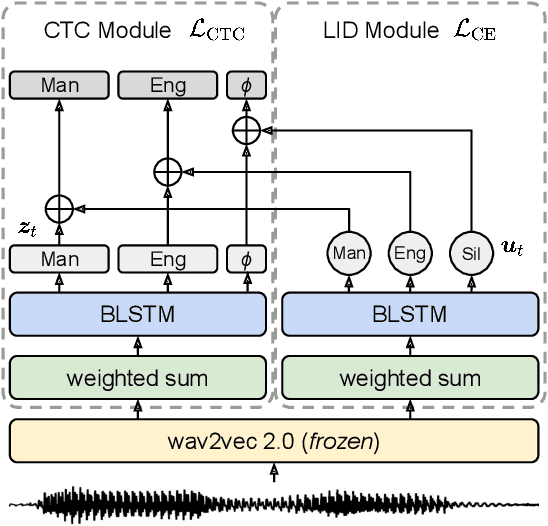
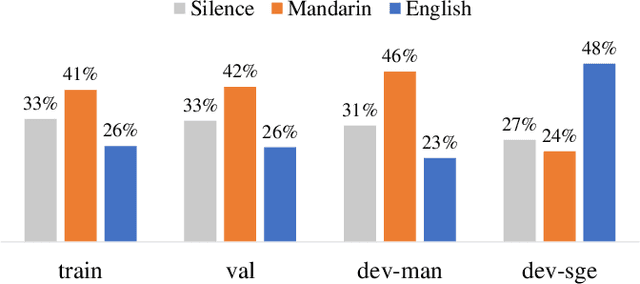
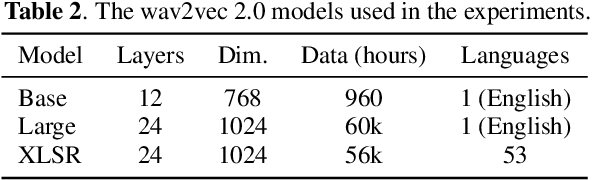
Code-switching (CS) is common in daily conversations where more than one language is used within a sentence. The difficulties of CS speech recognition lie in alternating languages and the lack of transcribed data. Therefore, this paper uses the recently successful self-supervised learning (SSL) methods to leverage many unlabeled speech data without CS. We show that hidden representations of SSL models offer frame-level language identity even if the models are trained with English speech only. Jointly training CTC and language identification modules with self-supervised speech representations improves CS speech recognition performance. Furthermore, using multilingual speech data for pre-training obtains the best CS speech recognition.