 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Scale Evaluation of Speech Foundation Models
Apr 15, 2024The foundation model paradigm leverages a shared foundation model to achieve state-of-the-art (SOTA) performance for various tasks, requiring minimal downstream-specific modeling and data annotation. This approach has proven crucial in the field of Natural Language Processing (NLP). However, the speech processing community lacks a similar setup to explore the paradigm systematically. In this work, we establish the Speech processing Universal PERformance Benchmark (SUPERB) to study the effectiveness of the paradigm for speech. We propose a unified multi-tasking framework to address speech processing tasks in SUPERB using a frozen foundation model followed by task-specialized, lightweight prediction heads. Combining our results with community submissions, we verify that the foundation model paradigm is promising for speech, and our multi-tasking framework is simple yet effective, as the best-performing foundation model shows competitive generalizability across most SUPERB tasks. For reproducibility and extensibility, we have developed a long-term maintained platform that enables deterministic benchmarking, allows for result sharing via an online leaderboard, and promotes collaboration through a community-driven benchmark database to support new development cycles. Finally, we conduct a series of analyses to offer an in-depth understanding of SUPERB and speech foundation models, including information flows across tasks inside the models, the correctness of the weighted-sum benchmarking protocol and the statistical significance and robustness of the benchmark.
Investigating Human-Identifiable Features Hidden in Adversarial Perturbations
Sep 28, 2023Neural networks perform exceedingly well across various machine learning tasks but are not immune to adversarial perturbations. This vulnerability has implications for real-world applications. While much research has been conducted, the underlying reasons why neural networks fall prey to adversarial attacks are not yet fully understood. Central to our study, which explores up to five attack algorithms across three datasets, is the identification of human-identifiable features in adversarial perturbations. Additionally, we uncover two distinct effects manifesting within human-identifiable features. Specifically, the masking effect is prominent in untargeted attacks, while the generation effect is more common in targeted attacks. Using pixel-level annotations, we extract such features and demonstrate their ability to compromise target models. In addition, our findings indicate a notable extent of similarity in perturbations across different attack algorithms when averaged over multiple models. This work also provides insights into phenomena associated with adversarial perturbations, such as transferability and model interpretability. Our study contributes to a deeper understanding of the underlying mechanisms behind adversarial attacks and offers insights for the development of more resilient defense strategies for neural networks.
Ensemble knowledge distillation of self-supervised speech models
Feb 24, 2023

Distilled self-supervised models have shown competitive performance and efficiency in recent years. However, there is a lack of experience in jointly distilling multiple self-supervised speech models. In our work, we performed Ensemble Knowledge Distillation (EKD) on various self-supervised speech models such as HuBERT, RobustHuBERT, and WavLM. We tried two different aggregation techniques, layerwise-average and layerwise-concatenation, to the representations of different teacher models and found that the former was more effective. On top of that, we proposed a multiple prediction head method for student models to predict different layer outputs of multiple teacher models simultaneously. The experimental results show that our method improves the performance of the distilled models on four downstream speech processing tasks, Phoneme Recognition, Speaker Identification, Emotion Recognition, and Automatic Speech Recognition in the hidden-set track of the SUPERB benchmark.
Compressing Transformer-based self-supervised models for speech processing
Nov 17, 2022Despite the success of Transformers in self-supervised learning with applications to various downstream tasks, the computational cost of training and inference remains a major challenge for applying these models to a wide spectrum of devices. Several isolated attempts have been made to compress Transformers, prior to applying them to downstream tasks. In this work, we aim to provide context for the isolated results, studying several commonly used compression techniques, including weight pruning, head pruning, low-rank approximation, and knowledge distillation. We report wall-clock time, the number of parameters, and the number of multiply-accumulate operations for these techniques, charting the landscape of compressing Transformer-based self-supervised models.
SUPERB @ SLT 2022: Challenge on Generalization and Efficiency of Self-Supervised Speech Representation Learning
Oct 16, 2022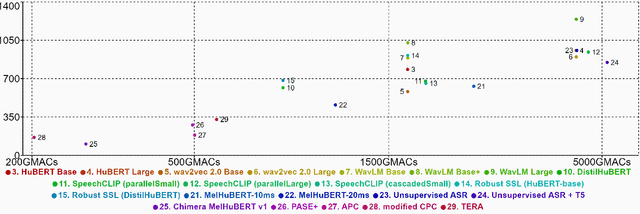
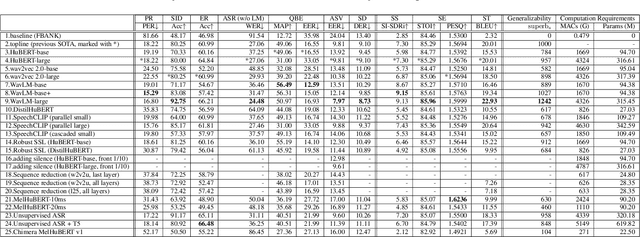
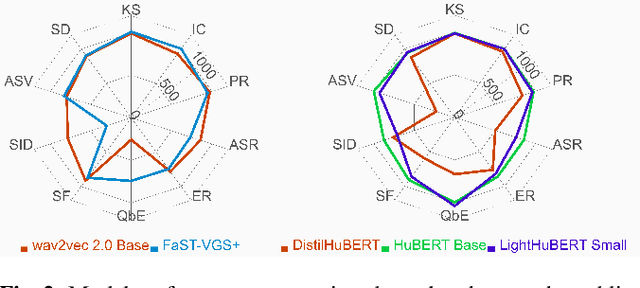
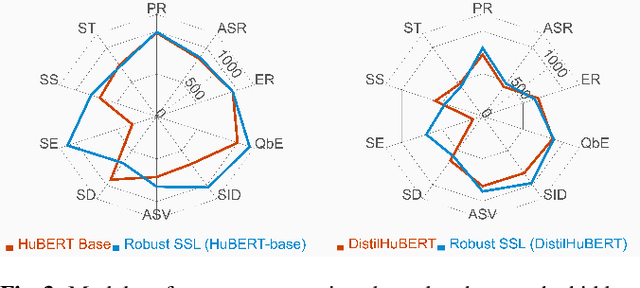
We present the SUPERB challenge at SLT 2022, which aims at learning self-supervised speech representation for better performance, generalization, and efficiency. The challenge builds upon the SUPERB benchmark and implements metrics to measure the computation requirements of self-supervised learning (SSL) representation and to evaluate its generalizability and performance across the diverse SUPERB tasks. The SUPERB benchmark provides comprehensive coverage of popular speech processing tasks, from speech and speaker recognition to audio generation and semantic understanding. As SSL has gained interest in the speech community and showed promising outcomes, we envision the challenge to uplevel the impact of SSL techniques by motivating more practical designs of techniques beyond task performance. We summarize the results of 14 submitted models in this paper. We also discuss the main findings from those submissions and the future directions of SSL research.