 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Human-Identifiable Features Hidden in Adversarial Perturbations
Sep 28, 2023Neural networks perform exceedingly well across various machine learning tasks but are not immune to adversarial perturbations. This vulnerability has implications for real-world applications. While much research has been conducted, the underlying reasons why neural networks fall prey to adversarial attacks are not yet fully understood. Central to our study, which explores up to five attack algorithms across three datasets, is the identification of human-identifiable features in adversarial perturbations. Additionally, we uncover two distinct effects manifesting within human-identifiable features. Specifically, the masking effect is prominent in untargeted attacks, while the generation effect is more common in targeted attacks. Using pixel-level annotations, we extract such features and demonstrate their ability to compromise target models. In addition, our findings indicate a notable extent of similarity in perturbations across different attack algorithms when averaged over multiple models. This work also provides insights into phenomena associated with adversarial perturbations, such as transferability and model interpretability. Our study contributes to a deeper understanding of the underlying mechanisms behind adversarial attacks and offers insights for the development of more resilient defense strategies for neural networks.
Searching for the Essence of Adversarial Perturbations
May 30, 2022


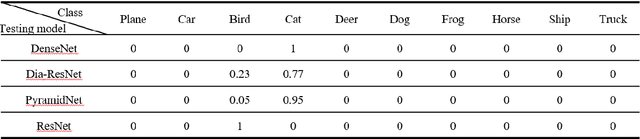
Neural networks have achieved the state-of-the-art performance on various machine learning fields, yet the incorporation of malicious perturbations with input data (adversarial example) is able to fool neural networks' predictions. This would lead to potential risks in real-world applications, for example, auto piloting and facial recognition. However, the reason for the existence of adversarial examples remains controversial. Here we demonstrate that adversarial perturbations contain human-recognizable information, which is the key conspirator responsible for a neural network's erroneous prediction. This concept of human-recognizable information allows us to explain key features related to adversarial perturbations, which include the existence of adversarial examples, the transferability among different neural networks, and the increased neural network interpretability for adversarial training. Two unique properties in adversarial perturbations that fool neural networks are uncovered: masking and generation. A special class, the complementary class, is identified when neural networks classify input images. The human-recognizable information contained in adversarial perturbations allows researchers to gain insight on the working principles of neural networks and may lead to develop techniques that detect/defense adversarial attacks.