 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Video Representations with Spatio-Temporal Sparse Autoencoders
Apr 05, 2026We present the first systematic study of Sparse Autoencoders (SAEs) on video representations. Standard SAEs decompose video into interpretable, monosemantic features but destroy temporal coherence: hard TopK selection produces unstable feature assignments across frames, reducing autocorrelation by 36%. We propose spatio-temporal contrastive objectives and Matryoshka hierarchical grouping that recover and even exceed raw temporal coherence. The contrastive loss weight controls a tunable trade-off between reconstruction and temporal coherence. A systematic ablation on two backbones and two datasets shows that different configurations excel at different goals: reconstruction fidelity, temporal coherence, action discrimination, or interpretability. Contrastive SAE features improve action classification by +3.9% over raw features and text-video retrieval by up to 2.8xR@1. A cross-backbone analysis reveals that standard monosemanticity metrics contain a backbone-alignment artifact: both DINOv2 and VideoMAE produce equally monosemantic features under neutral (CLIP) similarity. Causal ablation confirms that contrastive training concentrates predictive signal into a small number of identifiable features.
TensorCommitments: A Lightweight Verifiable Inference for Language Models
Feb 13, 2026Most large language models (LLMs) run on external clouds: users send a prompt, pay for inference, and must trust that the remote GPU executes the LLM without any adversarial tampering. We critically ask how to achieve verifiable LLM inference, where a prover (the service) must convince a verifier (the client) that an inference was run correctly without rerunning the LLM. Existing cryptographic works are too slow at the LLM scale, while non-cryptographic ones require a strong verifier GPU. We propose TensorCommitments (TCs), a tensor-native proof-of-inference scheme. TC binds the LLM inference to a commitment, an irreversible tag that breaks under tampering, organized in our multivariate Terkle Trees. For LLaMA2, TC adds only 0.97% prover and 0.12% verifier time over inference while improving robustness to tailored LLM attacks by up to 48% over the best prior work requiring a verifier GPU.
Minimax Rates for Hyperbolic Hierarchical Learning
Jan 27, 2026We prove an exponential separation in sample complexity between Euclidean and hyperbolic representations for learning on hierarchical data under standard Lipschitz regularization. For depth-$R$ hierarchies with branching factor $m$, we first establish a geometric obstruction for Euclidean space: any bounded-radius embedding forces volumetric collapse, mapping exponentially many tree-distant points to nearby locations. This necessitates Lipschitz constants scaling as $\exp(Ω(R))$ to realize even simple hierarchical targets, yielding exponential sample complexity under capacity control. We then show this obstruction vanishes in hyperbolic space: constant-distortion hyperbolic embeddings admit $O(1)$-Lipschitz realizability, enabling learning with $n = O(mR \log m)$ samples. A matching $Ω(mR \log m)$ lower bound via Fano's inequality establishes that hyperbolic representations achieve the information-theoretic optimum. We also show a geometry-independent bottleneck: any rank-$k$ prediction space captures only $O(k)$ canonical hierarchical contrasts.
Learnings from Scaling Visual Tokenizers for Reconstruction and Generation
Jan 16, 2025



Visual tokenization via auto-encoding empowers state-of-the-art image and video generative models by compressing pixels into a latent space. Although scaling Transformer-based generators has been central to recent advances, the tokenizer component itself is rarely scaled, leaving open questions about how auto-encoder design choices influence both its objective of reconstruction and downstream generative performance. Our work aims to conduct an exploration of scaling in auto-encoders to fill in this blank. To facilitate this exploration, we replace the typical convolutional backbone with an enhanced Vision Transformer architecture for Tokenization (ViTok). We train ViTok on large-scale image and video datasets far exceeding ImageNet-1K, removing data constraints on tokenizer scaling. We first study how scaling the auto-encoder bottleneck affects both reconstruction and generation -- and find that while it is highly correlated with reconstruction, its relationship with generation is more complex. We next explored the effect of separately scaling the auto-encoders' encoder and decoder on reconstruction and generation performance. Crucially, we find that scaling the encoder yields minimal gains for either reconstruction or generation, while scaling the decoder boosts reconstruction but the benefits for generation are mixed. Building on our exploration, we design ViTok as a lightweight auto-encoder that achieves competitive performance with state-of-the-art auto-encoders on ImageNet-1K and COCO reconstruction tasks (256p and 512p) while outperforming existing auto-encoders on 16-frame 128p video reconstruction for UCF-101, all with 2-5x fewer FLOPs. When integrated with Diffusion Transformers, ViTok demonstrates competitive performance on image generation for ImageNet-1K and sets new state-of-the-art benchmarks for class-conditional video generation on UCF-101.
MultiTok: Variable-Length Tokenization for Efficient LLMs Adapted from LZW Compression
Oct 28, 2024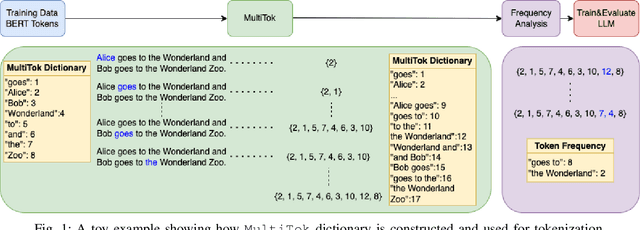
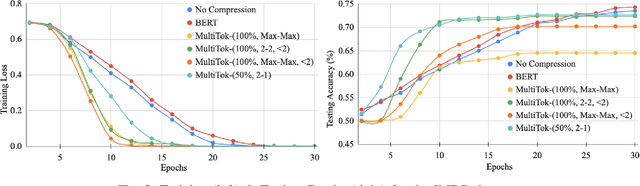
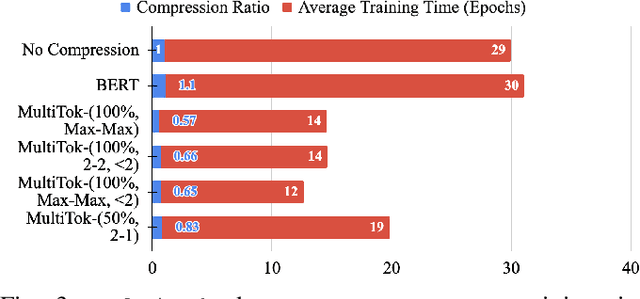

Large language models have drastically changed the prospects of AI by introducing technologies for more complex natural language processing. However, current methodologies to train such LLMs require extensive resources including but not limited to large amounts of data, expensive machinery, and lengthy training. To solve this problem, this paper proposes a new tokenization method inspired by universal Lempel-Ziv-Welch data compression that compresses repetitive phrases into multi-word tokens. With MultiTok as a new tokenizing tool, we show that language models are able to be trained notably more efficiently while offering a similar accuracy on more succinct and compressed training data. In fact, our results demonstrate that MultiTok achieves a comparable performance to the BERT standard as a tokenizer while also providing close to 2.5x faster training with more than 30% less training data.
Enhancing K-user Interference Alignment for Discrete Constellations via Learning
Jul 21, 2024



In this paper, we consider a K-user interference channel where interference among the users is neither too strong nor too weak, a scenario that is relatively underexplored in the literature. We propose a novel deep learning-based approach to design the encoder and decoder functions that aim to maximize the sumrate of the interference channel for discrete constellations. We first consider the MaxSINR algorithm, a state-of-the-art linear scheme for Gaussian inputs, as the baseline and then propose a modified version of the algorithm for discrete inputs. We then propose a neural network-based approach that learns a constellation mapping with the objective of maximizing the sumrate. We provide numerical results to show that the constellations learned by the neural network-based approach provide enhanced alignments, not just in beamforming directions but also in terms of the effective constellation at the receiver, thereby leading to improved sum-rate performance.
Unified Auto-Encoding with Masked Diffusion
Jun 25, 2024At the core of both successful generative and self-supervised representation learning models there is a reconstruction objective that incorporates some form of image corruption. Diffusion models implement this approach through a scheduled Gaussian corruption process, while masked auto-encoder models do so by masking patches of the image. Despite their different approaches, the underlying similarity in their methodologies suggests a promising avenue for an auto-encoder capable of both de-noising tasks. We propose a unified self-supervised objective, dubbed Unified Masked Diffusion (UMD), that combines patch-based and noise-based corruption techniques within a single auto-encoding framework. Specifically, UMD modifies the diffusion transformer (DiT) training process by introducing an additional noise-free, high masking representation step in the diffusion noising schedule, and utilizes a mixed masked and noised image for subsequent timesteps. By integrating features useful for diffusion modeling and for predicting masked patch tokens, UMD achieves strong performance in downstream generative and representation learning tasks, including linear probing and class-conditional generation. This is achieved without the need for heavy data augmentations, multiple views, or additional encoders. Furthermore, UMD improves over the computational efficiency of prior diffusion based methods in total training time. We release our code at https://github.com/philippe-eecs/small-vision.
OpenDebateEvidence: A Massive-Scale Argument Mining and Summarization Dataset
Jun 20, 2024



We introduce OpenDebateEvidence, a comprehensive dataset for argument mining and summarization sourced from the American Competitive Debate community. This dataset includes over 3.5 million documents with rich metadata, making it one of the most extensive collections of debate evidence. OpenDebateEvidence captures the complexity of arguments in high school and college debates, providing valuable resources for training and evaluation. Our extensive experiments demonstrate the efficacy of fine-tuning state-of-the-art large language models for argumentative abstractive summarization across various methods, models, and datasets. By providing this comprehensive resource, we aim to advance computational argumentation and support practical applications for debaters, educators, and researchers. OpenDebateEvidence is publicly available to support further research and innovation in computational argumentation. Access it here: https://huggingface.co/datasets/Yusuf5/OpenCaselist
TexShape: Information Theoretic Sentence Embedding for Language Models
Feb 05, 2024



With the exponential growth in data volume and the emergence of data-intensive applications, particularly in the field of machine learning, concerns related to resource utilization, privacy, and fairness have become paramount. This paper focuses on the textual domain of data and addresses challenges regarding encoding sentences to their optimized representations through the lens of information-theory. In particular, we use empirical estimates of mutual information, using the Donsker-Varadhan definition of Kullback-Leibler divergence. Our approach leverages this estimation to train an information-theoretic sentence embedding, called TexShape, for (task-based) data compression or for filtering out sensitive information, enhancing privacy and fairness. In this study, we employ a benchmark language model for initial text representation, complemented by neural networks for information-theoretic compression and mutual information estimations. Our experiments demonstrate significant advancements in preserving maximal targeted information and minimal sensitive information over adverse compression ratios, in terms of predictive accuracy of downstream models that are trained using the compressed data.
Investigating Human-Identifiable Features Hidden in Adversarial Perturbations
Sep 28, 2023Neural networks perform exceedingly well across various machine learning tasks but are not immune to adversarial perturbations. This vulnerability has implications for real-world applications. While much research has been conducted, the underlying reasons why neural networks fall prey to adversarial attacks are not yet fully understood. Central to our study, which explores up to five attack algorithms across three datasets, is the identification of human-identifiable features in adversarial perturbations. Additionally, we uncover two distinct effects manifesting within human-identifiable features. Specifically, the masking effect is prominent in untargeted attacks, while the generation effect is more common in targeted attacks. Using pixel-level annotations, we extract such features and demonstrate their ability to compromise target models. In addition, our findings indicate a notable extent of similarity in perturbations across different attack algorithms when averaged over multiple models. This work also provides insights into phenomena associated with adversarial perturbations, such as transferability and model interpretability. Our study contributes to a deeper understanding of the underlying mechanisms behind adversarial attacks and offers insights for the development of more resilient defense strategies for neural networks.