 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecureSpectra: Safeguarding Digital Identity from Deep Fake Threats via Intelligent Signatures
Jul 01, 2024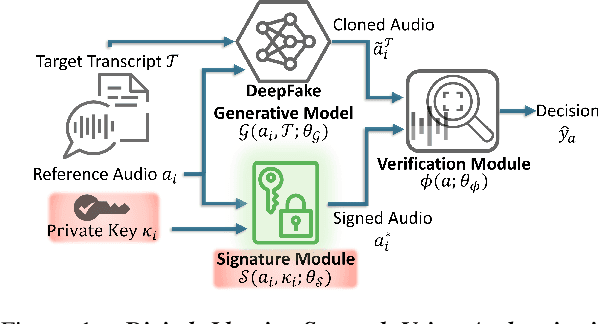
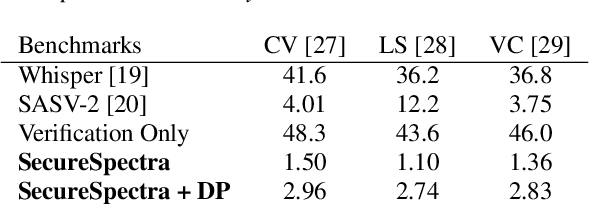
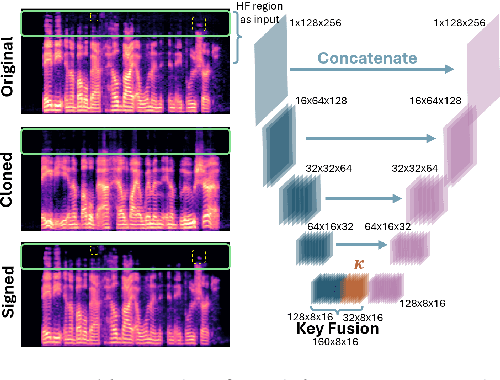
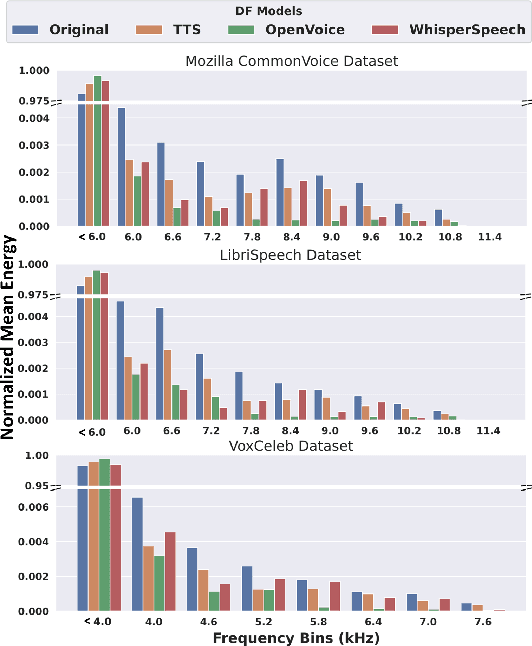
Advancements in DeepFake (DF) audio models pose a significant threat to voice authentication systems, leading to unauthorized access and the spread of misinformation. We introduce a defense mechanism, SecureSpectra, addressing DF threats by embedding orthogonal, irreversible signatures within audio. SecureSpectra leverages the inability of DF models to replicate high-frequency content, which we empirically identify across diverse datasets and DF models. Integrating differential privacy into the pipeline protects signatures from reverse engineering and strikes a delicate balance between enhanced security and minimal performance compromises. Our evaluations on Mozilla Common Voice, LibriSpeech, and VoxCeleb datasets showcase SecureSpectra's superior performance, outperforming recent works by up to 71% in detection accuracy. We open-source SecureSpectra to benefit the research community.
TexShape: Information Theoretic Sentence Embedding for Language Models
Feb 05, 2024



With the exponential growth in data volume and the emergence of data-intensive applications, particularly in the field of machine learning, concerns related to resource utilization, privacy, and fairness have become paramount. This paper focuses on the textual domain of data and addresses challenges regarding encoding sentences to their optimized representations through the lens of information-theory. In particular, we use empirical estimates of mutual information, using the Donsker-Varadhan definition of Kullback-Leibler divergence. Our approach leverages this estimation to train an information-theoretic sentence embedding, called TexShape, for (task-based) data compression or for filtering out sensitive information, enhancing privacy and fairness. In this study, we employ a benchmark language model for initial text representation, complemented by neural networks for information-theoretic compression and mutual information estimations. Our experiments demonstrate significant advancements in preserving maximal targeted information and minimal sensitive information over adverse compression ratios, in terms of predictive accuracy of downstream models that are trained using the compressed data.