 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiTok: Variable-Length Tokenization for Efficient LLMs Adapted from LZW Compression
Oct 28, 2024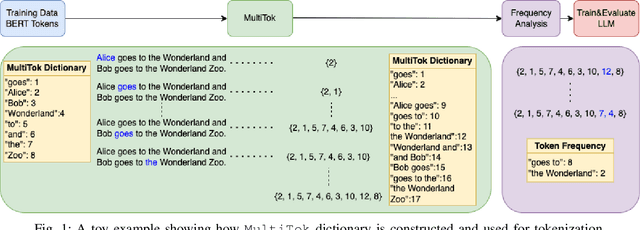
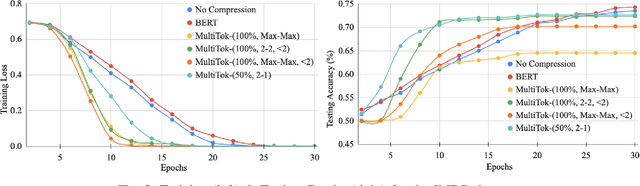
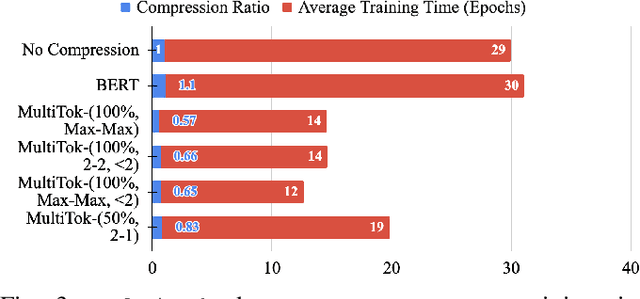

Large language models have drastically changed the prospects of AI by introducing technologies for more complex natural language processing. However, current methodologies to train such LLMs require extensive resources including but not limited to large amounts of data, expensive machinery, and lengthy training. To solve this problem, this paper proposes a new tokenization method inspired by universal Lempel-Ziv-Welch data compression that compresses repetitive phrases into multi-word tokens. With MultiTok as a new tokenizing tool, we show that language models are able to be trained notably more efficiently while offering a similar accuracy on more succinct and compressed training data. In fact, our results demonstrate that MultiTok achieves a comparable performance to the BERT standard as a tokenizer while also providing close to 2.5x faster training with more than 30% less training data.
Audio Classification of Low Feature Spectrograms Utilizing Convolutional Neural Networks
Oct 28, 2024
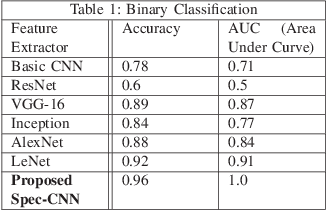

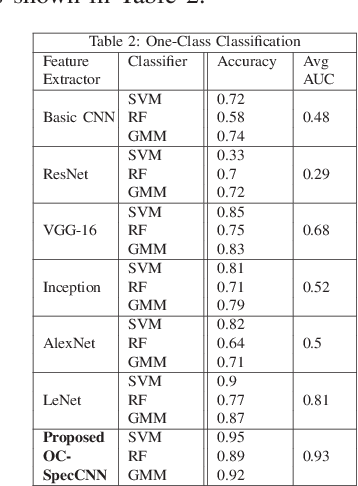
Modern day audio signal classification techniques lack the ability to classify low feature audio signals in the form of spectrographic temporal frequency data representations. Additionally, currently utilized techniques rely on full diverse data sets that are often not representative of real-world distributions. This paper derives several first-of-its-kind machine learning methodologies to analyze these low feature audio spectrograms given data distributions that may have normalized, skewed, or even limited training sets. In particular, this paper proposes several novel customized convolutional architectures to extract identifying features using binary, one-class, and siamese approaches to identify the spectrographic signature of a given audio signal. Utilizing these novel convolutional architectures as well as the proposed classification methods, these experiments demonstrate state-of-the-art classification accuracy and improved efficiency than traditional audio classification methods.
A Novel Score-CAM based Denoiser for Spectrographic Signature Extraction without Ground Truth
Oct 28, 2024



Sonar based audio classification techniques are a growing area of research in the field of underwater acoustics. Usually, underwater noise picked up by passive sonar transducers contains all types of signals that travel through the ocean and is transformed into spectrographic images. As a result, the corresponding spectrograms intended to display the temporal-frequency data of a certain object often include the tonal regions of abundant extraneous noise that can effectively interfere with a 'contact'. So, a majority of spectrographic samples extracted from underwater audio signals are rendered unusable due to their clutter and lack the required indistinguishability between different objects. With limited clean true data for supervised training, creating classification models for these audio signals is severely bottlenecked. This paper derives several new techniques to combat this problem by developing a novel Score-CAM based denoiser to extract an object's signature from noisy spectrographic data without being given any ground truth data. In particular, this paper proposes a novel generative adversarial network architecture for learning and producing spectrographic training data in similar distributions to low-feature spectrogram inputs. In addition, this paper also a generalizable class activation mapping based denoiser for different distributions of acoustic data, even real-world data distributions. Utilizing these novel architectures and proposed denoising techniques, these experiments demonstrate state-of-the-art noise reduction accuracy and improved classification accuracy than current audio classification standards. As such, this approach has applications not only to audio data but for countless data distributions used all around the world for machine learning.
TexShape: Information Theoretic Sentence Embedding for Language Models
Feb 05, 2024



With the exponential growth in data volume and the emergence of data-intensive applications, particularly in the field of machine learning, concerns related to resource utilization, privacy, and fairness have become paramount. This paper focuses on the textual domain of data and addresses challenges regarding encoding sentences to their optimized representations through the lens of information-theory. In particular, we use empirical estimates of mutual information, using the Donsker-Varadhan definition of Kullback-Leibler divergence. Our approach leverages this estimation to train an information-theoretic sentence embedding, called TexShape, for (task-based) data compression or for filtering out sensitive information, enhancing privacy and fairness. In this study, we employ a benchmark language model for initial text representation, complemented by neural networks for information-theoretic compression and mutual information estimations. Our experiments demonstrate significant advancements in preserving maximal targeted information and minimal sensitive information over adverse compression ratios, in terms of predictive accuracy of downstream models that are trained using the compressed data.