 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Obfuscations Of LLM Embedding Sequences: Stained Glass Transform
Jun 11, 2025The high cost of ownership of AI compute infrastructure and challenges of robust serving of large language models (LLMs) has led to a surge in managed Model-as-a-service deployments. Even when enterprises choose on-premises deployments, the compute infrastructure is typically shared across many teams in order to maximize the return on investment. In both scenarios the deployed models operate only on plaintext data, and so enterprise data owners must allow their data to appear in plaintext on a shared or multi-tenant compute infrastructure. This results in data owners with private or sensitive data being hesitant or restricted in what data they use with these types of deployments. In this work we introduce the Stained Glass Transform, a learned, stochastic, and sequence dependent transformation of the word embeddings of an LLM which information theoretically provides privacy to the input of the LLM while preserving the utility of model. We theoretically connect a particular class of Stained Glass Transforms to the theory of mutual information of Gaussian Mixture Models. We then calculate a-postiori privacy estimates, based on mutual information, and verify the privacy and utility of instances of transformed embeddings through token level metrics of privacy and standard LLM performance benchmarks.
MultiTok: Variable-Length Tokenization for Efficient LLMs Adapted from LZW Compression
Oct 28, 2024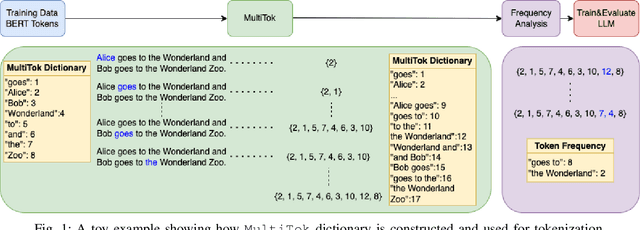
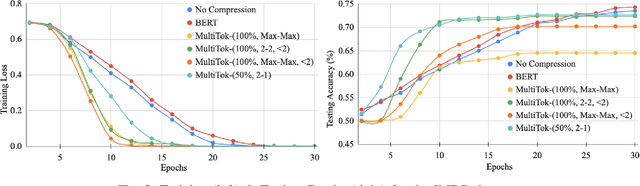
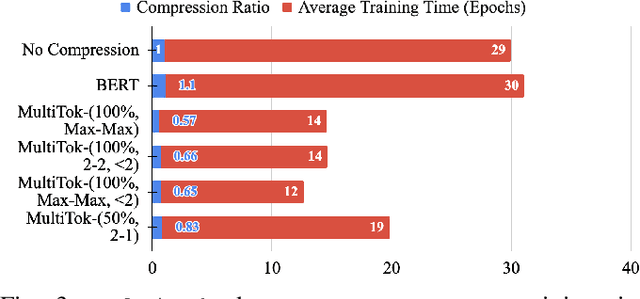

Large language models have drastically changed the prospects of AI by introducing technologies for more complex natural language processing. However, current methodologies to train such LLMs require extensive resources including but not limited to large amounts of data, expensive machinery, and lengthy training. To solve this problem, this paper proposes a new tokenization method inspired by universal Lempel-Ziv-Welch data compression that compresses repetitive phrases into multi-word tokens. With MultiTok as a new tokenizing tool, we show that language models are able to be trained notably more efficiently while offering a similar accuracy on more succinct and compressed training data. In fact, our results demonstrate that MultiTok achieves a comparable performance to the BERT standard as a tokenizer while also providing close to 2.5x faster training with more than 30% less training data.
SecureSpectra: Safeguarding Digital Identity from Deep Fake Threats via Intelligent Signatures
Jul 01, 2024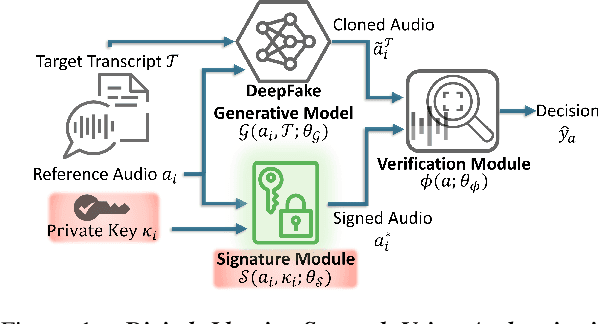
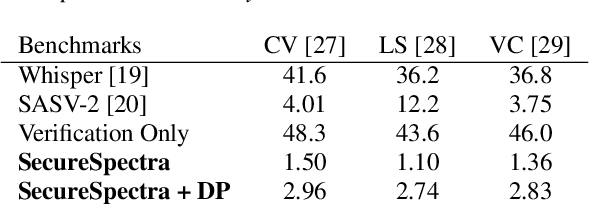
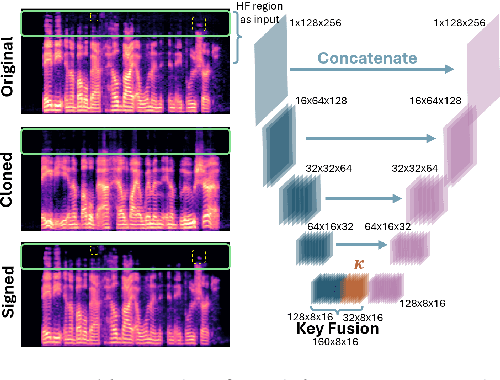
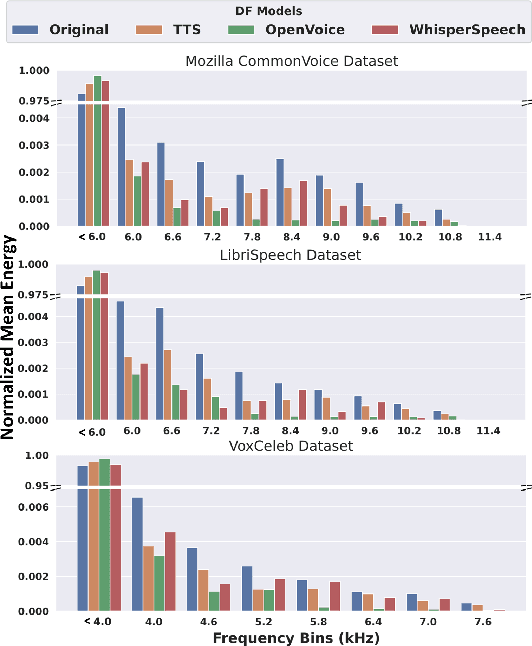
Advancements in DeepFake (DF) audio models pose a significant threat to voice authentication systems, leading to unauthorized access and the spread of misinformation. We introduce a defense mechanism, SecureSpectra, addressing DF threats by embedding orthogonal, irreversible signatures within audio. SecureSpectra leverages the inability of DF models to replicate high-frequency content, which we empirically identify across diverse datasets and DF models. Integrating differential privacy into the pipeline protects signatures from reverse engineering and strikes a delicate balance between enhanced security and minimal performance compromises. Our evaluations on Mozilla Common Voice, LibriSpeech, and VoxCeleb datasets showcase SecureSpectra's superior performance, outperforming recent works by up to 71% in detection accuracy. We open-source SecureSpectra to benefit the research community.