 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSR: A Generic Framework for Text-Aided Map Compression for Localization
Mar 04, 2026Mapping is crucial in robotics for localization and downstream decision-making. As robots are deployed in ever-broader settings, the maps they rely on continue to increase in size. However, storing these maps indefinitely (cold storage), transferring them across networks, or sending localization queries to cloud-hosted maps imposes prohibitive memory and bandwidth costs. We propose a text-enhanced compression framework that reduces both memory and bandwidth footprints while retaining high-fidelity localization. The key idea is to treat text as an alternative modality: one that can be losslessly compressed with large language models. We propose leveraging lightweight text descriptions combined with very small image feature vectors, which capture "complementary information" as a compact representation for the mapping task. Building on this, our novel technique, Similarity Space Replication (SSR), learns an adaptive image embedding in one shot that captures only the information "complementary" to the text descriptions. We validate our compression framework on multiple downstream localization tasks, including Visual Place Recognition as well as object-centric Monte Carlo localization in both indoor and outdoor settings. SSR achieves 2 times better compression than competing baselines on state-of-the-art datasets, including TokyoVal, Pittsburgh30k, Replica, and KITTI.
TensorCommitments: A Lightweight Verifiable Inference for Language Models
Feb 13, 2026Most large language models (LLMs) run on external clouds: users send a prompt, pay for inference, and must trust that the remote GPU executes the LLM without any adversarial tampering. We critically ask how to achieve verifiable LLM inference, where a prover (the service) must convince a verifier (the client) that an inference was run correctly without rerunning the LLM. Existing cryptographic works are too slow at the LLM scale, while non-cryptographic ones require a strong verifier GPU. We propose TensorCommitments (TCs), a tensor-native proof-of-inference scheme. TC binds the LLM inference to a commitment, an irreversible tag that breaks under tampering, organized in our multivariate Terkle Trees. For LLaMA2, TC adds only 0.97% prover and 0.12% verifier time over inference while improving robustness to tailored LLM attacks by up to 48% over the best prior work requiring a verifier GPU.
Real-Time Privacy Preservation for Robot Visual Perception
May 08, 2025



Many robots (e.g., iRobot's Roomba) operate based on visual observations from live video streams, and such observations may inadvertently include privacy-sensitive objects, such as personal identifiers. Existing approaches for preserving privacy rely on deep learning models, differential privacy, or cryptography. They lack guarantees for the complete concealment of all sensitive objects. Guaranteeing concealment requires post-processing techniques and thus is inadequate for real-time video streams. We develop a method for privacy-constrained video streaming, PCVS, that conceals sensitive objects within real-time video streams. PCVS takes a logical specification constraining the existence of privacy-sensitive objects, e.g., never show faces when a person exists. It uses a detection model to evaluate the existence of these objects in each incoming frame. Then, it blurs out a subset of objects such that the existence of the remaining objects satisfies the specification. We then propose a conformal prediction approach to (i) establish a theoretical lower bound on the probability of the existence of these objects in a sequence of frames satisfying the specification and (ii) update the bound with the arrival of each subsequent frame. Quantitative evaluations show that PCVS achieves over 95 percent specification satisfaction rate in multiple datasets, significantly outperforming other methods. The satisfaction rate is consistently above the theoretical bounds across all datasets, indicating that the established bounds hold. Additionally, we deploy PCVS on robots in real-time operation and show that the robots operate normally without being compromised when PCVS conceals objects.
EntroLLM: Entropy Encoded Weight Compression for Efficient Large Language Model Inference on Edge Devices
May 05, 2025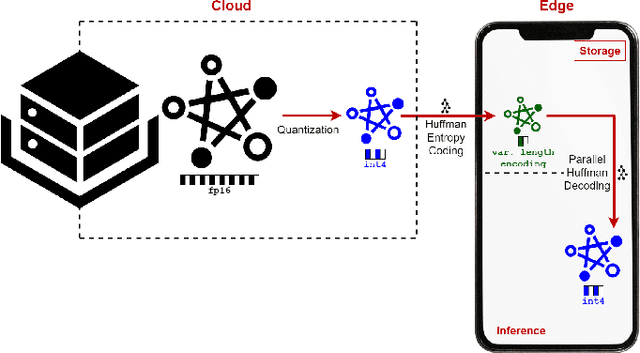

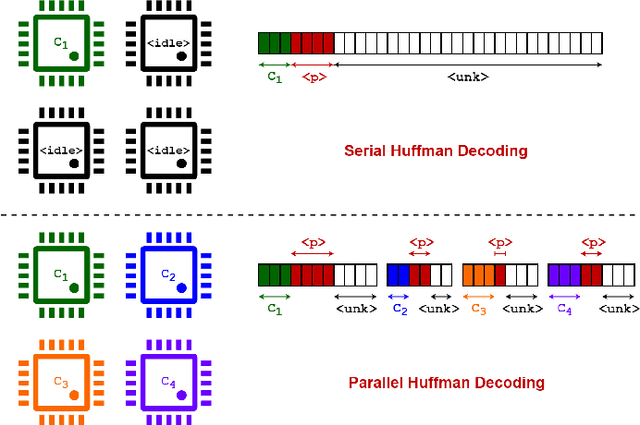
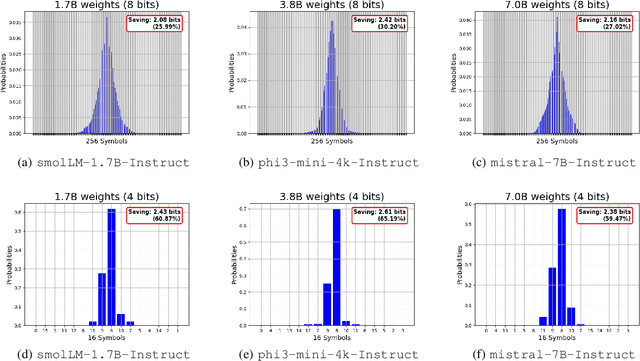
Large Language Models (LLMs) demonstrate exceptional performance across various tasks, but their large storage and computational requirements constrain their deployment on edge devices. To address this, we propose EntroLLM, a novel compression framework that integrates mixed quantization with entropy coding to reduce storage overhead while maintaining model accuracy. Our method applies a layer-wise mixed quantization scheme - choosing between symmetric and asymmetric quantization based on individual layer weight distributions - to optimize compressibility. We then employ Huffman encoding for lossless compression of the quantized weights, significantly reducing memory bandwidth requirements. Furthermore, we introduce parallel Huffman decoding, which enables efficient retrieval of encoded weights during inference, ensuring minimal latency impact. Our experiments on edge-compatible LLMs, including smolLM-1.7B-Instruct, phi3-mini-4k-Instruct, and mistral-7B-Instruct, demonstrate that EntroLLM achieves up to $30%$ storage reduction compared to uint8 models and up to $65%$ storage reduction compared to uint4 models, while preserving perplexity and accuracy, on language benchmark tasks. We further show that our method enables $31.9%$ - $146.6%$ faster inference throughput on memory-bandwidth-limited edge devices, such as NVIDIA Jetson P3450, by reducing the required data movement. The proposed approach requires no additional re-training and is fully compatible with existing post-training quantization methods, making it a practical solution for edge LLMs.
Optimization-Free Image Immunization Against Diffusion-Based Editing
Nov 27, 2024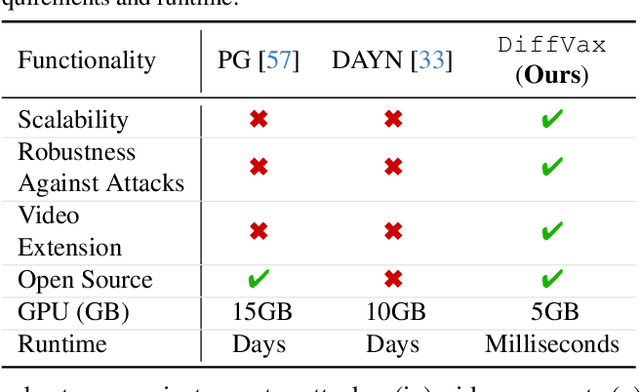
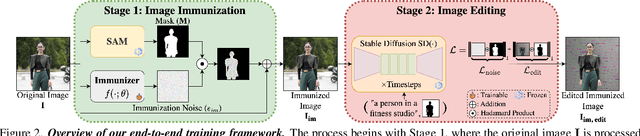


Current image immunization defense techniques against diffusion-based editing embed imperceptible noise in target images to disrupt editing models. However, these methods face scalability challenges, as they require time-consuming re-optimization for each image-taking hours for small batches. To address these challenges, we introduce DiffVax, a scalable, lightweight, and optimization-free framework for image immunization, specifically designed to prevent diffusion-based editing. Our approach enables effective generalization to unseen content, reducing computational costs and cutting immunization time from days to milliseconds-achieving a 250,000x speedup. This is achieved through a loss term that ensures the failure of editing attempts and the imperceptibility of the perturbations. Extensive qualitative and quantitative results demonstrate that our model is scalable, optimization-free, adaptable to various diffusion-based editing tools, robust against counter-attacks, and, for the first time, effectively protects video content from editing. Our code is provided in our project webpage.
Context Matters: Leveraging Contextual Features for Time Series Forecasting
Oct 17, 2024Time series forecasts are often influenced by exogenous contextual features in addition to their corresponding history. For example, in financial settings, it is hard to accurately predict a stock price without considering public sentiments and policy decisions in the form of news articles, tweets, etc. Though this is common knowledge, the current state-of-the-art (SOTA) forecasting models fail to incorporate such contextual information, owing to its heterogeneity and multimodal nature. To address this, we introduce ContextFormer, a novel plug-and-play method to surgically integrate multimodal contextual information into existing pre-trained forecasting models. ContextFormer effectively distills forecast-specific information from rich multimodal contexts, including categorical, continuous, time-varying, and even textual information, to significantly enhance the performance of existing base forecasters. ContextFormer outperforms SOTA forecasting models by up to 30% on a range of real-world datasets spanning energy, traffic, environmental, and financial domains.
Constrained Posterior Sampling: Time Series Generation with Hard Constraints
Oct 16, 2024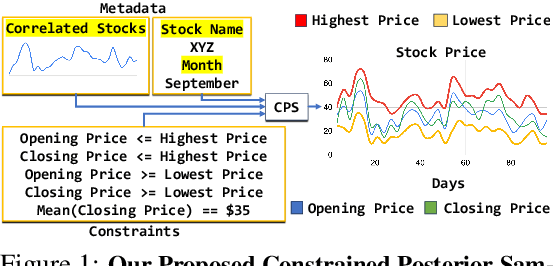
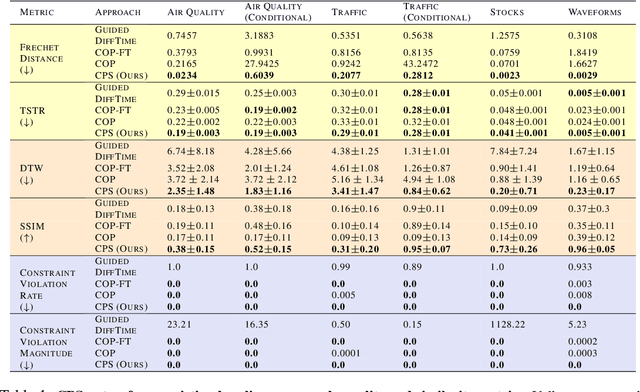
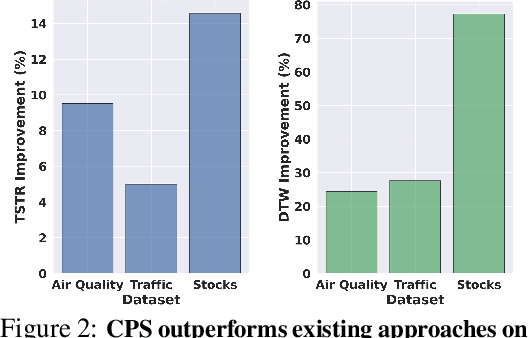

Generating realistic time series samples is crucial for stress-testing models and protecting user privacy by using synthetic data. In engineering and safety-critical applications, these samples must meet certain hard constraints that are domain-specific or naturally imposed by physics or nature. Consider, for example, generating electricity demand patterns with constraints on peak demand times. This can be used to stress-test the functioning of power grids during adverse weather conditions. Existing approaches for generating constrained time series are either not scalable or degrade sample quality. To address these challenges, we introduce Constrained Posterior Sampling (CPS), a diffusion-based sampling algorithm that aims to project the posterior mean estimate into the constraint set after each denoising update. Notably, CPS scales to a large number of constraints (~100) without requiring additional training. We provide theoretical justifications highlighting the impact of our projection step on sampling. Empirically, CPS outperforms state-of-the-art methods in sample quality and similarity to real time series by around 10% and 42%, respectively, on real-world stocks, traffic, and air quality datasets.
CSA: Data-efficient Mapping of Unimodal Features to Multimodal Features
Oct 10, 2024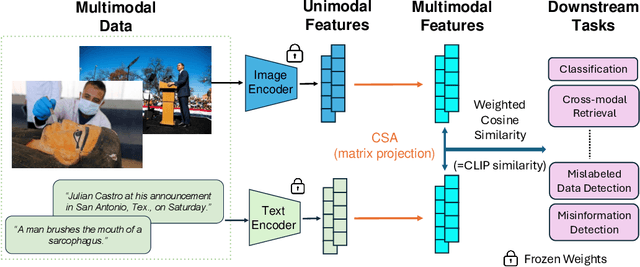
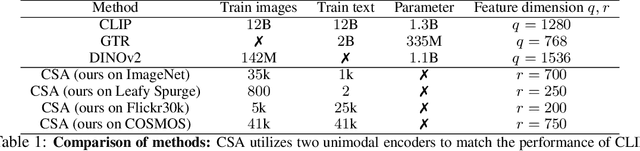
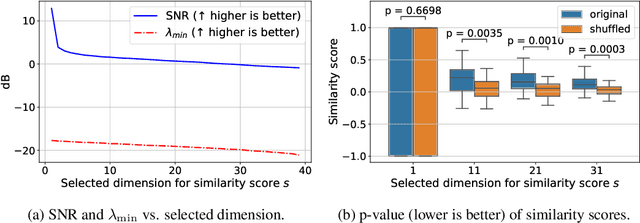
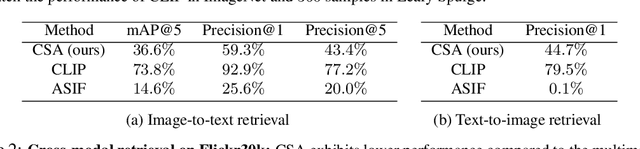
Multimodal encoders like CLIP excel in tasks such as zero-shot image classification and cross-modal retrieval. However, they require excessive training data. We propose canonical similarity analysis (CSA), which uses two unimodal encoders to replicate multimodal encoders using limited data. CSA maps unimodal features into a multimodal space, using a new similarity score to retain only the multimodal information. CSA only involves the inference of unimodal encoders and a cubic-complexity matrix decomposition, eliminating the need for extensive GPU-based model training. Experiments show that CSA outperforms CLIP while requiring $300,000\times$ fewer multimodal data pairs and $6\times$ fewer unimodal data for ImageNet classification and misinformative news captions detection. CSA surpasses the state-of-the-art method to map unimodal features to multimodal features. We also demonstrate the ability of CSA with modalities beyond image and text, paving the way for future modality pairs with limited paired multimodal data but abundant unpaired unimodal data, such as lidar and text.
Exploiting Distribution Constraints for Scalable and Efficient Image Retrieval
Oct 09, 2024



Image retrieval is crucial in robotics and computer vision, with downstream applications in robot place recognition and vision-based product recommendations. Modern retrieval systems face two key challenges: scalability and efficiency. State-of-the-art image retrieval systems train specific neural networks for each dataset, an approach that lacks scalability. Furthermore, since retrieval speed is directly proportional to embedding size, existing systems that use large embeddings lack efficiency. To tackle scalability, recent works propose using off-the-shelf foundation models. However, these models, though applicable across datasets, fall short in achieving performance comparable to that of dataset-specific models. Our key observation is that, while foundation models capture necessary subtleties for effective retrieval, the underlying distribution of their embedding space can negatively impact cosine similarity searches. We introduce Autoencoders with Strong Variance Constraints (AE-SVC), which, when used for projection, significantly improves the performance of foundation models. We provide an in-depth theoretical analysis of AE-SVC. Addressing efficiency, we introduce Single-shot Similarity Space Distillation ((SS)$_2$D), a novel approach to learn embeddings with adaptive sizes that offers a better trade-off between size and performance. We conducted extensive experiments on four retrieval datasets, including Stanford Online Products (SoP) and Pittsburgh30k, using four different off-the-shelf foundation models, including DinoV2 and CLIP. AE-SVC demonstrates up to a $16\%$ improvement in retrieval performance, while (SS)$_2$D shows a further $10\%$ improvement for smaller embedding sizes.
SecureSpectra: Safeguarding Digital Identity from Deep Fake Threats via Intelligent Signatures
Jul 01, 2024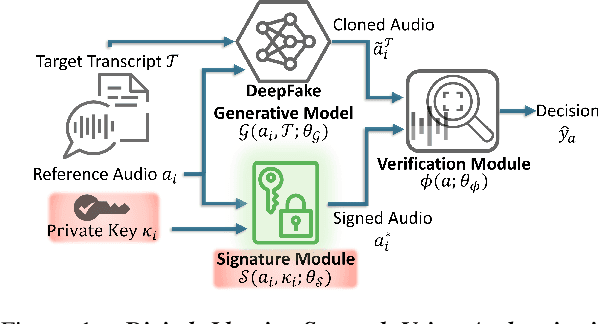
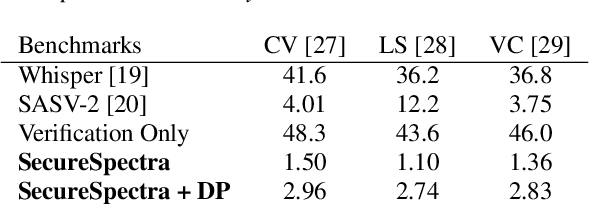
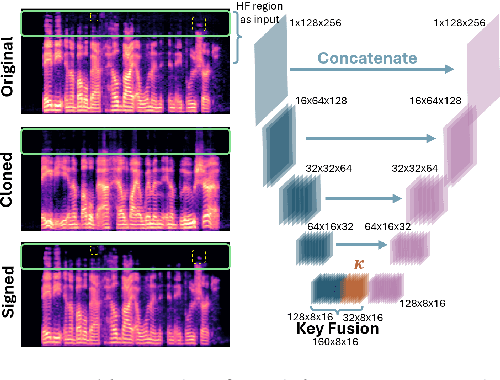
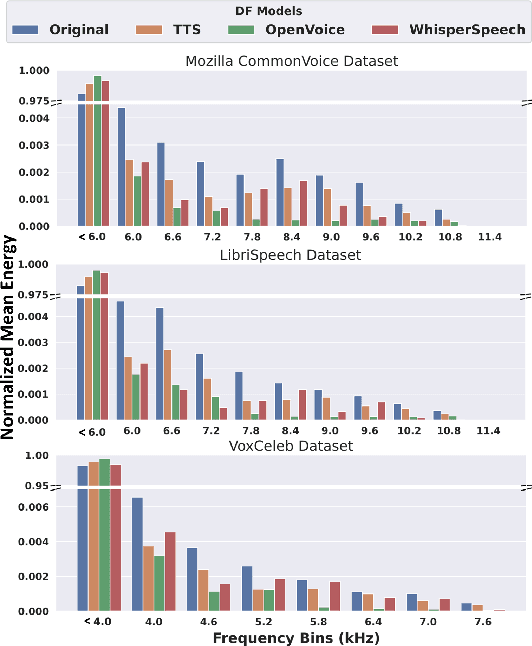
Advancements in DeepFake (DF) audio models pose a significant threat to voice authentication systems, leading to unauthorized access and the spread of misinformation. We introduce a defense mechanism, SecureSpectra, addressing DF threats by embedding orthogonal, irreversible signatures within audio. SecureSpectra leverages the inability of DF models to replicate high-frequency content, which we empirically identify across diverse datasets and DF models. Integrating differential privacy into the pipeline protects signatures from reverse engineering and strikes a delicate balance between enhanced security and minimal performance compromises. Our evaluations on Mozilla Common Voice, LibriSpeech, and VoxCeleb datasets showcase SecureSpectra's superior performance, outperforming recent works by up to 71% in detection accuracy. We open-source SecureSpectra to benefit the research community.