 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Objects Enable, Not What They Are: Functional Latent Spaces for Affordance Reasoning
Jun 04, 2026Existing robot planning systems rely on appearance-based reasoning, where visual observations are encoded into latent spaces organized around object appearances (e.g., recognizing a "cart" based on how it looks). However, planning requires reasoning about task-relevant functionalities of objects (e.g., whether an object is "movable"), which appearance-based latent spaces do not capture. As a result, existing approaches struggle to generalize to novel robot-object interactions. We address this limited generalizability through affordance reasoning, enabling planning based on task-relevant object functionalities instead of appearance alone. We introduce A4D, which maps visual observations into a shared latent space structured around affordances (e.g., "movable"). By projecting visual observations into this functional latent space and measuring their proximity to affordances, A4D infers functionalities relevant to the observed object. Furthermore, we introduce an affordance discovery mechanism that expands the latent space to handle unseen scenarios where existing affordances are insufficient. A4D uses proximity in the functional latent space to quantify uncertainty in affordance inference and selectively triggers affordance discovery. We evaluate A4D across several planning tasks involving diverse and unseen affordances. A4D achieves 94% inference accuracy on existing affordances outperforming state-of-the-art approaches by over 15% points, improves new-affordance inference accuracy from 70% to over 90% with fewer than 10% of the original training data, and enables 100x faster inference. Code, videos, and data available at: https://A4Dance-reasoning.github.io.
VASO: Formally Verifiable Self-Evolving Skills for Physical AI Agents
Jun 03, 2026Reusable robot skills are becoming the basic units through which embodied agents turn open-ended instructions into long-horizon physical behavior. We argue that, while foundation models have collapsed the cost of creating these skills, the cost of trusting them has not. Existing skill-evolution loops refine skills through execution feedback, unit tests, environment reward, or LLM self-critique, but these signals provide only trace-level evidence: they show that a skill worked on sampled executions, not that skill-induced plans satisfy temporal safety contracts under untested conditions. We introduce VASO, a framework for verification-guided self-evolution of LLM-generated robot skill contracts. In VASO, each skill is represented as a semantic contract with two coupled interfaces: a formal interface that aligns robot states, observations, and control commands with logical propositions for model checking, and a planner-facing interface that guides executable behavior generation. A model checker first filters logically inconsistent skill contracts, then verifies plans induced by the skill against global and local temporal specifications. When verification fails, VASO translates the counterexample trace into a textual gradient that updates the reusable skill contract while keeping foundation-model weights frozen. On Clearpath Jackal and PX4 quadcopter tasks, VASO reaches 97.2% formal-specification compliance using fewer than 100 optimization samples, outperforming execution-feedback, prompt-optimization, and fine-tuning baselines. To our knowledge, VASO is the first framework that closes the loop between formal verification and self-evolving LLM-generated skills for physical AI agents: formal counterexamples become optimization feedback for reusable robot skill contracts, rather than merely verifying one-off plans, tuning planner prompts, or fine-tuning model weights.
DataEvolver: Let Your Data Build and Improve Itself via Goal-Driven Loop Agents
May 03, 2026Constructing controllable visual data is a major bottleneck for image editing and multimodal understanding. Useful supervision is rarely produced by a single rendering pass; instead it emerges through iterative generation, inspection, correction, filtering, and export. We present DataEvolver, a closed-loop visual data engine that organizes this process around explicit goals, persistent artifacts, bounded corrective actions, and acceptance decisions. DataEvolver supports multiple artifact types, including RGB images, masks, depth maps, normal maps, meshes, poses, trajectories, and review traces. In the current release, the system operates through two coupled loops: generation-time self-correction within each sample and validation-time self-expansion across dataset rounds. We validate the framework on an image-level object-rotation setting. With a fixed Qwen-Edit LoRA probe, our final Ours+DualGate model outperforms both the unadapted base model and a public multi-angle LoRA on SpatialEdit and a held-out evaluation set. Ablations show a consistent improvement path from scene-aware generation to feedback-driven correction and dual-gated validation. Beyond the released rotation data, our main contribution is a reusable framework for building visual datasets through explicit goal tracking, review, correction, and acceptance loops.
Learning Actionable Manipulation Recovery via Counterfactual Failure Synthesis
Mar 13, 2026While recent foundation models have significantly advanced robotic manipulation, these systems still struggle to autonomously recover from execution errors. Current failure-learning paradigms rely on either costly and unsafe real-world data collection or simulator-based perturbations, which introduce a severe sim-to-real gap. Furthermore, existing visual analyzers predominantly output coarse, binary diagnoses rather than the executable, trajectory-level corrections required for actual recovery. To bridge the gap between failure diagnosis and actionable recovery, we introduce Dream2Fix, a framework that synthesizes photorealistic, counterfactual failure rollouts directly from successful real-world demonstrations. By perturbing actions within a generative world model, Dream2Fix creates paired failure-correction data without relying on simulators. To ensure the generated data is physically viable for robot learning, we implement a structured verification mechanism that strictly filters rollouts for task validity, visual coherence, and kinematic safety. This engine produces a high-fidelity dataset of over 120k paired samples. Using this dataset, we fine-tune a vision-language model to jointly predict failure types and precise recovery trajectories, mapping visual anomalies directly to corrective actions. Extensive real-world robotic experiments show our approach achieves state-of-the-art correction accuracy, improving from 19.7% to 81.3% over prior baselines, and successfully enables zero-shot closed-loop failure recovery in physical deployments.
RepV: Safety-Separable Latent Spaces for Scalable Neurosymbolic Plan Verification
Oct 30, 2025As AI systems migrate to safety-critical domains, verifying that their actions comply with well-defined rules remains a challenge. Formal methods provide provable guarantees but demand hand-crafted temporal-logic specifications, offering limited expressiveness and accessibility. Deep learning approaches enable evaluation of plans against natural-language constraints, yet their opaque decision process invites misclassifications with potentially severe consequences. We introduce RepV, a neurosymbolic verifier that unifies both views by learning a latent space where safe and unsafe plans are linearly separable. Starting from a modest seed set of plans labeled by an off-the-shelf model checker, RepV trains a lightweight projector that embeds each plan, together with a language model-generated rationale, into a low-dimensional space; a frozen linear boundary then verifies compliance for unseen natural-language rules in a single forward pass. Beyond binary classification, RepV provides a probabilistic guarantee on the likelihood of correct verification based on its position in the latent space. This guarantee enables a guarantee-driven refinement of the planner, improving rule compliance without human annotations. Empirical evaluations show that RepV improves compliance prediction accuracy by up to 15% compared to baseline methods while adding fewer than 0.2M parameters. Furthermore, our refinement framework outperforms ordinary fine-tuning baselines across various planning domains. These results show that safety-separable latent spaces offer a scalable, plug-and-play primitive for reliable neurosymbolic plan verification. Code and data are available at: https://repv-project.github.io/.
Foundation Models for Logistics: Toward Certifiable, Conversational Planning Interfaces
Jul 15, 2025Logistics operators, from battlefield coordinators rerouting airlifts ahead of a storm to warehouse managers juggling late trucks, often face life-critical decisions that demand both domain expertise and rapid and continuous replanning. While popular methods like integer programming yield logistics plans that satisfy user-defined logical constraints, they are slow and assume an idealized mathematical model of the environment that does not account for uncertainty. On the other hand, large language models (LLMs) can handle uncertainty and promise to accelerate replanning while lowering the barrier to entry by translating free-form utterances into executable plans, yet they remain prone to misinterpretations and hallucinations that jeopardize safety and cost. We introduce a neurosymbolic framework that pairs the accessibility of natural-language dialogue with verifiable guarantees on goal interpretation. It converts user requests into structured planning specifications, quantifies its own uncertainty at the field and token level, and invokes an interactive clarification loop whenever confidence falls below an adaptive threshold. A lightweight model, fine-tuned on just 100 uncertainty-filtered examples, surpasses the zero-shot performance of GPT-4.1 while cutting inference latency by nearly 50%. These preliminary results highlight a practical path toward certifiable, real-time, and user-aligned decision-making for complex logistics.
Real-Time Privacy Preservation for Robot Visual Perception
May 08, 2025



Many robots (e.g., iRobot's Roomba) operate based on visual observations from live video streams, and such observations may inadvertently include privacy-sensitive objects, such as personal identifiers. Existing approaches for preserving privacy rely on deep learning models, differential privacy, or cryptography. They lack guarantees for the complete concealment of all sensitive objects. Guaranteeing concealment requires post-processing techniques and thus is inadequate for real-time video streams. We develop a method for privacy-constrained video streaming, PCVS, that conceals sensitive objects within real-time video streams. PCVS takes a logical specification constraining the existence of privacy-sensitive objects, e.g., never show faces when a person exists. It uses a detection model to evaluate the existence of these objects in each incoming frame. Then, it blurs out a subset of objects such that the existence of the remaining objects satisfies the specification. We then propose a conformal prediction approach to (i) establish a theoretical lower bound on the probability of the existence of these objects in a sequence of frames satisfying the specification and (ii) update the bound with the arrival of each subsequent frame. Quantitative evaluations show that PCVS achieves over 95 percent specification satisfaction rate in multiple datasets, significantly outperforming other methods. The satisfaction rate is consistently above the theoretical bounds across all datasets, indicating that the established bounds hold. Additionally, we deploy PCVS on robots in real-time operation and show that the robots operate normally without being compromised when PCVS conceals objects.
Evaluating Human Trust in LLM-Based Planners: A Preliminary Study
Feb 27, 2025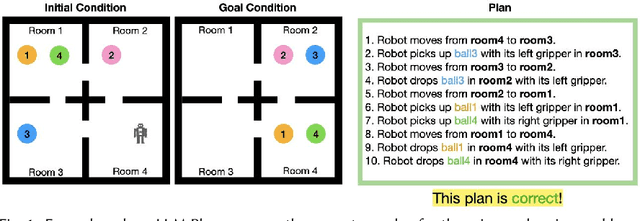

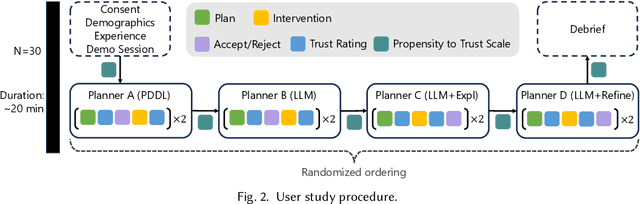
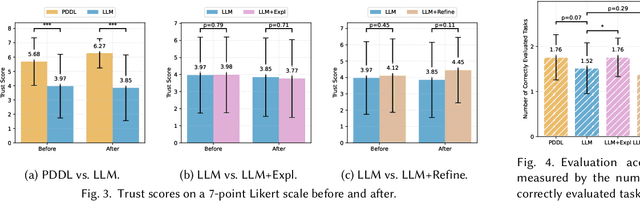
Large Language Models (LLMs) are increasingly used for planning tasks, offering unique capabilities not found in classical planners such as generating explanations and iterative refinement. However, trust--a critical factor in the adoption of planning systems--remains underexplored in the context of LLM-based planning tasks. This study bridges this gap by comparing human trust in LLM-based planners with classical planners through a user study in a Planning Domain Definition Language (PDDL) domain. Combining subjective measures, such as trust questionnaires, with objective metrics like evaluation accuracy, our findings reveal that correctness is the primary driver of trust and performance. Explanations provided by the LLM improved evaluation accuracy but had limited impact on trust, while plan refinement showed potential for increasing trust without significantly enhancing evaluation accuracy.
Any2Any: Incomplete Multimodal Retrieval with Conformal Prediction
Nov 25, 2024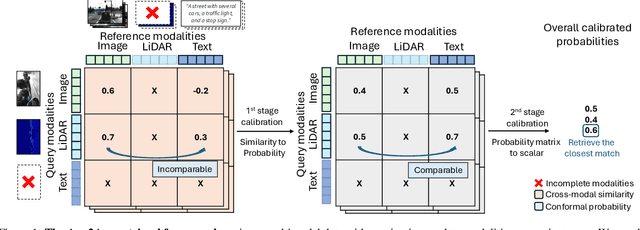
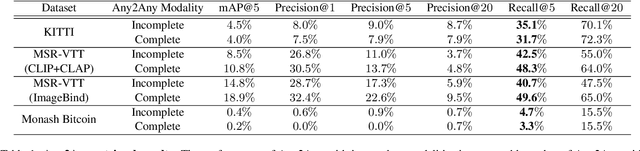
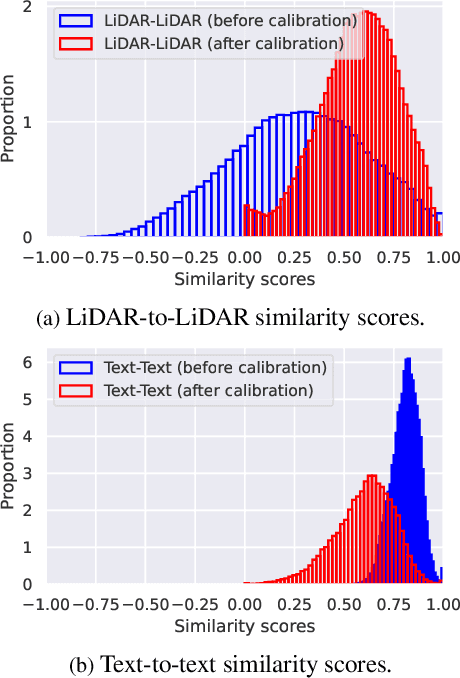
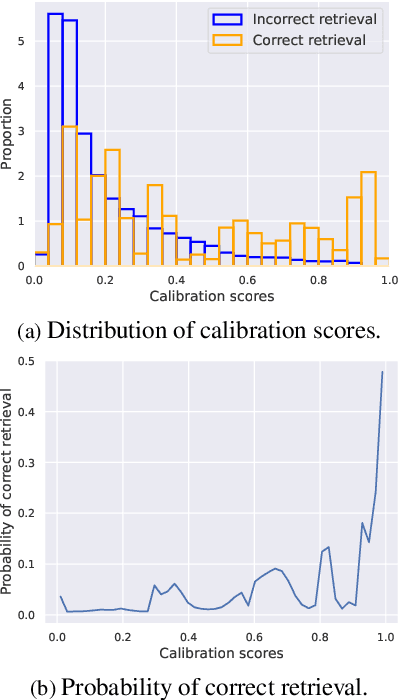
Autonomous agents perceive and interpret their surroundings by integrating multimodal inputs, such as vision, audio, and LiDAR. These perceptual modalities support retrieval tasks, such as place recognition in robotics. However, current multimodal retrieval systems encounter difficulties when parts of the data are missing due to sensor failures or inaccessibility, such as silent videos or LiDAR scans lacking RGB information. We propose Any2Any-a novel retrieval framework that addresses scenarios where both query and reference instances have incomplete modalities. Unlike previous methods limited to the imputation of two modalities, Any2Any handles any number of modalities without training generative models. It calculates pairwise similarities with cross-modal encoders and employs a two-stage calibration process with conformal prediction to align the similarities. Any2Any enables effective retrieval across multimodal datasets, e.g., text-LiDAR and text-time series. It achieves a Recall@5 of 35% on the KITTI dataset, which is on par with baseline models with complete modalities.
Know Where You're Uncertain When Planning with Multimodal Foundation Models: A Formal Framework
Nov 03, 2024Multimodal foundation models offer a promising framework for robotic perception and planning by processing sensory inputs to generate actionable plans. However, addressing uncertainty in both perception (sensory interpretation) and decision-making (plan generation) remains a critical challenge for ensuring task reliability. We present a comprehensive framework to disentangle, quantify, and mitigate these two forms of uncertainty. We first introduce a framework for uncertainty disentanglement, isolating perception uncertainty arising from limitations in visual understanding and decision uncertainty relating to the robustness of generated plans. To quantify each type of uncertainty, we propose methods tailored to the unique properties of perception and decision-making: we use conformal prediction to calibrate perception uncertainty and introduce Formal-Methods-Driven Prediction (FMDP) to quantify decision uncertainty, leveraging formal verification techniques for theoretical guarantees. Building on this quantification, we implement two targeted intervention mechanisms: an active sensing process that dynamically re-observes high-uncertainty scenes to enhance visual input quality and an automated refinement procedure that fine-tunes the model on high-certainty data, improving its capability to meet task specifications. Empirical validation in real-world and simulated robotic tasks demonstrates that our uncertainty disentanglement framework reduces variability by up to 40% and enhances task success rates by 5% compared to baselines. These improvements are attributed to the combined effect of both interventions and highlight the importance of uncertainty disentanglement which facilitates targeted interventions that enhance the robustness and reliability of autonomous systems.