 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Human Trust in LLM-Based Planners: A Preliminary Study
Paper and Code
Feb 27, 2025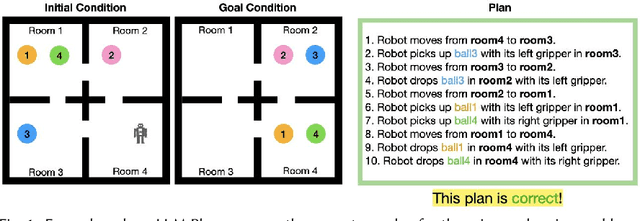

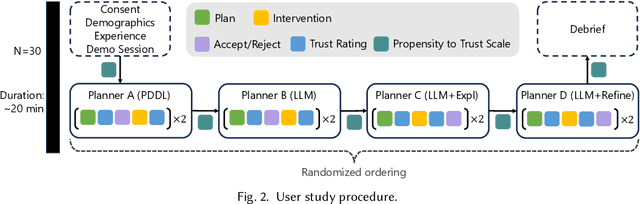
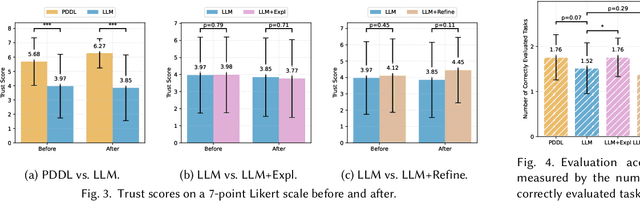
Large Language Models (LLMs) are increasingly used for planning tasks, offering unique capabilities not found in classical planners such as generating explanations and iterative refinement. However, trust--a critical factor in the adoption of planning systems--remains underexplored in the context of LLM-based planning tasks. This study bridges this gap by comparing human trust in LLM-based planners with classical planners through a user study in a Planning Domain Definition Language (PDDL) domain. Combining subjective measures, such as trust questionnaires, with objective metrics like evaluation accuracy, our findings reveal that correctness is the primary driver of trust and performance. Explanations provided by the LLM improved evaluation accuracy but had limited impact on trust, while plan refinement showed potential for increasing trust without significantly enhancing evaluation accuracy.