 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Decentralized Multi-Agent Reinforcement Learning Policies
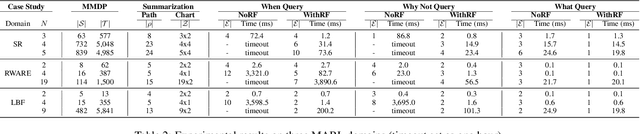
Nov 13, 2025Multi-Agent Reinforcement Learning (MARL) has gained significant interest in recent years, enabling sequential decision-making across multiple agents in various domains. However, most existing explanation methods focus on centralized MARL, failing to address the uncertainty and nondeterminism inherent in decentralized settings. We propose methods to generate policy summarizations that capture task ordering and agent cooperation in decentralized MARL policies, along with query-based explanations for When, Why Not, and What types of user queries about specific agent behaviors. We evaluate our approach across four MARL domains and two decentralized MARL algorithms, demonstrating its generalizability and computational efficiency. User studies show that our summarizations and explanations significantly improve user question-answering performance and enhance subjective ratings on metrics such as understanding and satisfaction.
Evaluating Human Trust in LLM-Based Planners: A Preliminary Study
Feb 27, 2025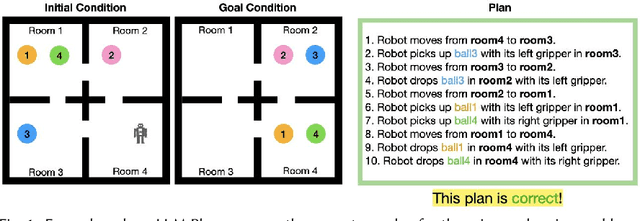

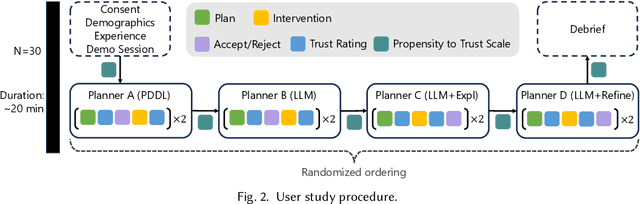
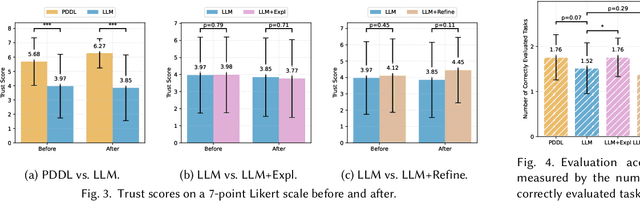
Large Language Models (LLMs) are increasingly used for planning tasks, offering unique capabilities not found in classical planners such as generating explanations and iterative refinement. However, trust--a critical factor in the adoption of planning systems--remains underexplored in the context of LLM-based planning tasks. This study bridges this gap by comparing human trust in LLM-based planners with classical planners through a user study in a Planning Domain Definition Language (PDDL) domain. Combining subjective measures, such as trust questionnaires, with objective metrics like evaluation accuracy, our findings reveal that correctness is the primary driver of trust and performance. Explanations provided by the LLM improved evaluation accuracy but had limited impact on trust, while plan refinement showed potential for increasing trust without significantly enhancing evaluation accuracy.
Explainable Multi-Agent Reinforcement Learning for Temporal Queries
May 17, 2023As multi-agent reinforcement learning (MARL) systems are increasingly deployed throughout society, it is imperative yet challenging for users to understand the emergent behaviors of MARL agents in complex environments. This work presents an approach for generating policy-level contrastive explanations for MARL to answer a temporal user query, which specifies a sequence of tasks completed by agents with possible cooperation. The proposed approach encodes the temporal query as a PCTL logic formula and checks if the query is feasible under a given MARL policy via probabilistic model checking. Such explanations can help reconcile discrepancies between the actual and anticipated multi-agent behaviors. The proposed approach also generates correct and complete explanations to pinpoint reasons that make a user query infeasible. We have successfully applied the proposed approach to four benchmark MARL domains (up to 9 agents in one domain). Moreover, the results of a user study show that the generated explanations significantly improve user performance and satisfaction.
Toward Policy Explanations for Multi-Agent Reinforcement Learning
Apr 29, 2022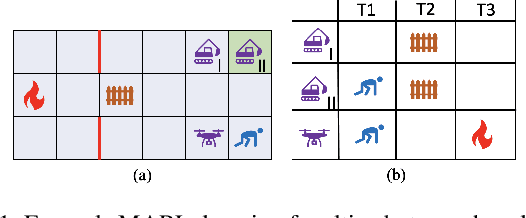

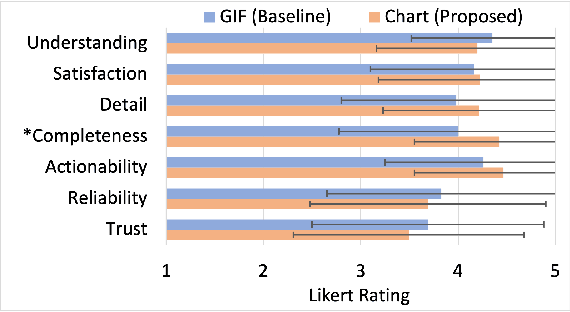
Advances in multi-agent reinforcement learning (MARL) enable sequential decision making for a range of exciting multi-agent applications such as cooperative AI and autonomous driving. Explaining agent decisions is crucial for improving system transparency, increasing user satisfaction, and facilitating human-agent collaboration. However, existing works on explainable reinforcement learning mostly focus on the single-agent setting and are not suitable for addressing challenges posed by multi-agent environments. We present novel methods to generate two types of policy explanations for MARL: (i) policy summarization about the agent cooperation and task sequence, and (ii) language explanations to answer queries about agent behavior. Experimental results on three MARL domains demonstrate the scalability of our methods. A user study shows that the generated explanations significantly improve user performance and increase subjective ratings on metrics such as user satisfaction.
Multi-Objective Controller Synthesis with Uncertain Human Preferences
May 10, 2021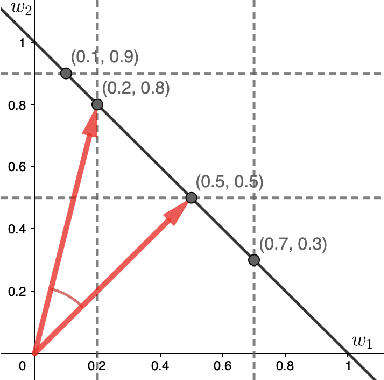
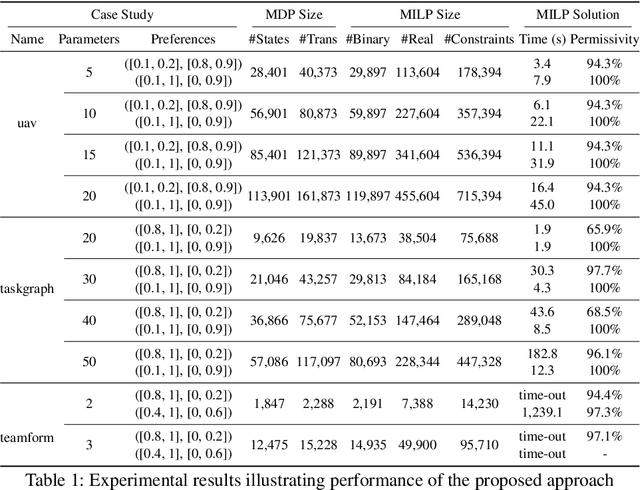


Multi-objective controller synthesis concerns the problem of computing an optimal controller subject to multiple (possibly conflicting) objective properties. The relative importance of objectives is often specified by human decision-makers. However, there is inherent uncertainty in human preferences (e.g., due to different preference elicitation methods). In this paper, we formalize the notion of uncertain human preferences and present a novel approach that accounts for uncertain human preferences in the multi-objective controller synthesis for Markov decision processes (MDPs). Our approach is based on mixed-integer linear programming (MILP) and synthesizes a sound, optimally permissive multi-strategy with respect to a multi-objective property and an uncertain set of human preferences. Experimental results on a range of large case studies show that our MILP-based approach is feasible and scalable to synthesize sound, optimally permissive multi-strategies with varying MDP model sizes and uncertainty levels of human preferences. Evaluation via an online user study also demonstrates the quality and benefits of synthesized (multi-)strategies.
Towards Personalized Explanation of Robotic Planning via User Feedback
Nov 01, 2020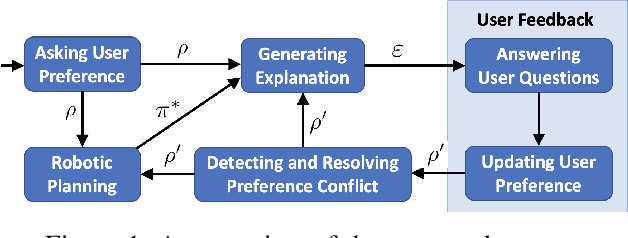

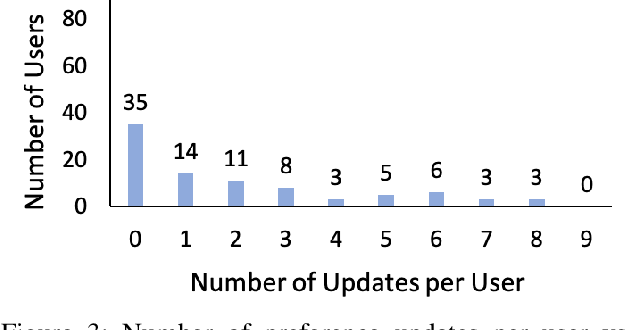
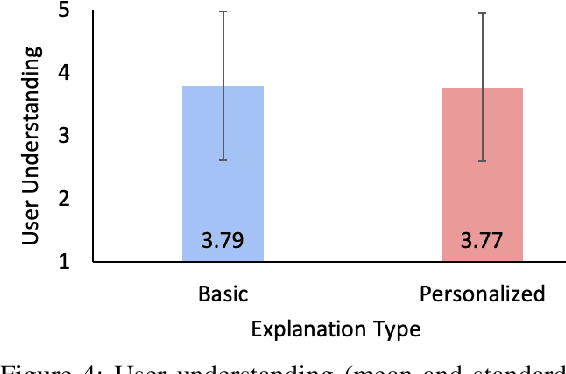
Prior studies have found that providing explanations about robots' decisions and actions help to improve system transparency, increase human users' trust of robots, and enable effective human-robot collaboration. Different users have various preferences about what should be included in explanations. However, little research has been conducted for the generation of personalized explanations. In this paper, we present a system for generating personalized explanations of robotic planning via user feedback. We consider robotic planning using Markov decision processes (MDPs) and develop an algorithm to automatically generate a personalized explanation of an optimal robotic plan (i.e., an optimal MDP policy) based on the user preference regarding four elements (i.e., objective, locality, specificity, and abstraction). In addition, we design the system to interact with users via answering users' further questions about the generated explanations. Users have the option to update their preferences to view different explanations. The system is capable of detecting and resolving any preference conflict via user interaction. Our user study results show that the generated personalized explanations improve user satisfaction, while the majority of users liked the system's capabilities of question-answering, and conflict detection and resolution.
Towards Transparent Robotic Planning via Contrastive Explanations
Mar 16, 2020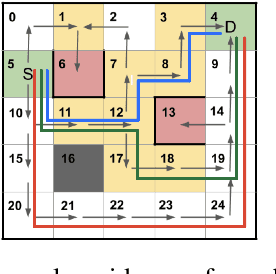
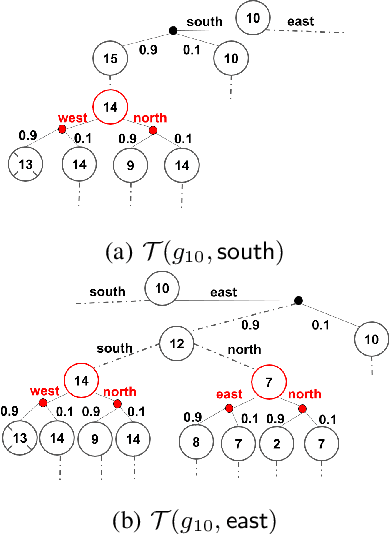
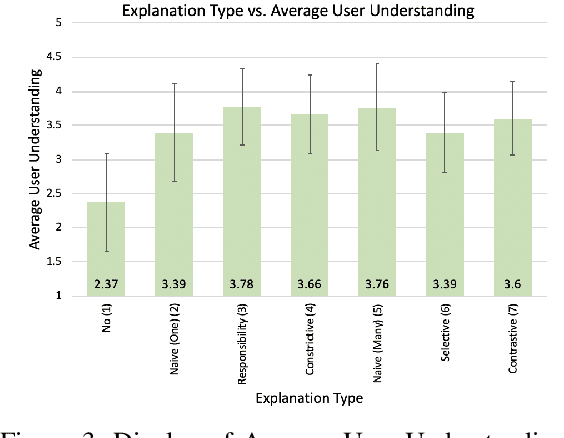
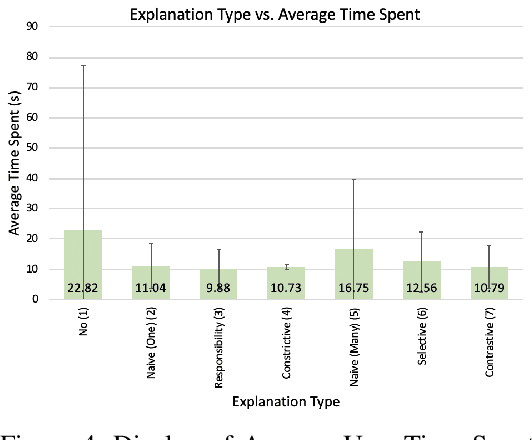
Providing explanations of chosen robotic actions can help to increase the transparency of robotic planning and improve users' trust. Social sciences suggest that the best explanations are contrastive, explaining not just why one action is taken, but why one action is taken instead of another. We formalize the notion of contrastive explanations for robotic planning policies based on Markov decision processes, drawing on insights from the social sciences. We present methods for the automated generation of contrastive explanations with three key factors: selectiveness, constrictiveness, and responsibility. The results of a user study with 100 participants on the Amazon Mechanical Turk platform show that our generated contrastive explanations can help to increase users' understanding and trust of robotic planning policies while reducing users' cognitive burden.