 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Q-Barrier Shielding for Safe In-Context Reinforcement Learning
May 24, 2026Safe in-context reinforcement learning (ICRL) adapts online from interaction history without test-time parameter updates while controlling episode cost under a safety budget. Under out-of-distribution (OOD) deployment shifts, pretraining-only safe ICRL can give poor reward-safety tradeoffs because the remaining budget affects behavior only through frozen policy conditioning, not an explicit action-level check against predicted future cost. We propose a latent Q-Barrier shield that learns a context representation, latent dynamics, and an ensemble cost critic before deployment. Without parameter updates, the shield infers context from history and filters or softly reweights candidate actions using the remaining budget and predicted future cost. We prove a conditional, error-decomposed barrier-margin result: a Q-Barrier-satisfying action leaves the next latent-budget state with an approximately budget-safe continuation under the learned critic, up to Bellman and latent-prediction errors. Across five safe ICRL benchmarks, the shield improves deployment-time reward-safety tradeoffs over a strong safe-ICRL baseline: after a short context window, it achieves higher return in four of five benchmarks while matching or lowering average episode cost in all five.
AutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration
May 19, 2026Automating scientific discovery requires more than generating papers from ideas. Real research is iterative: hypotheses are challenged from multiple perspectives, experiments fail and inform the next attempt, and lessons accumulate across cycles. Existing autonomous research systems often model this process as a linear pipeline: they rely on single-agent reasoning, stop when execution fails, and do not carry experience across runs. We present AutoResearchClaw, a multi-agent autonomous research pipeline built on five mechanisms: structured multi-agent debate for hypothesis generation and result analysis, a self-healing executor with a \textsc{Pivot}/\textsc{Refine} decision loop that transforms failures into information, verifiable result reporting that prevents fabricated numbers and hallucinated citations, human-in-the-loop collaboration with seven intervention modes spanning full autonomy to step-by-step oversight, and cross-run evolution that converts past mistakes into future safeguards. On ARC-Bench, a 25-topic experiment-stage benchmark, AutoResearchClaw outperforms AI Scientist v2 by 54.7%. A human-in-the-loop ablation across seven intervention modes reveals that precise, targeted collaboration at high-leverage decision points consistently outperforms both full autonomy and exhaustive step-by-step oversight. We position AutoResearchClaw as a research amplifier that augments rather than replaces human scientific judgment. Code is available at https://github.com/aiming-lab/AutoResearchClaw.
SafeManip: A Property-Driven Benchmark for Temporal Safety Evaluation in Robotic Manipulation
May 12, 2026Robotic manipulation is typically evaluated by task success, but successful completion does not guarantee safe execution. Many safety failures are temporal: a robot may touch a clean surface after contamination or release an object before it is fully inside an enclosure. We introduce SafeManip, a property-driven benchmark to explicitly evaluate temporal safety properties in robotic manipulation, moving beyond prior evaluations that largely focus on task completion or per-state constraint violations. SafeManip defines reusable safety templates over finite executions using Linear Temporal Logic over finite traces (LTLf). It maps observed rollouts to symbolic predicate traces and evaluates them with LTLf-based monitors. Its property suite covers eight manipulation safety categories: collision and contact safety, grasp stability, release stability, cross-contamination, action onset, mechanism recovery, object containment, and enclosure access. Templates can be instantiated with task-specific objects, fixtures, regions, or skills, allowing the same safety specifications to generalize across tasks and environments. We evaluate SafeManip on six vision-language-action policies, including $π_0$, $π_{0.5}$, GR00T, and their training variants, across 50 RoboCasa365 household tasks. Results show that even strong models often behave unsafely. Task-success gains do not reliably translate into safer execution: many successful rollouts remain unsafe, while longer-horizon or more complex tasks expose more violations. SafeManip provides a reusable evaluation layer for diagnosing temporal safety failures and measuring safe success beyond task completion.
Safety Generalization Under Distribution Shift in Safe Reinforcement Learning: A Diabetes Testbed
Jan 28, 2026Safe Reinforcement Learning (RL) algorithms are typically evaluated under fixed training conditions. We investigate whether training-time safety guarantees transfer to deployment under distribution shift, using diabetes management as a safety-critical testbed. We benchmark safe RL algorithms on a unified clinical simulator and reveal a safety generalization gap: policies satisfying constraints during training frequently violate safety requirements on unseen patients. We demonstrate that test-time shielding, which filters unsafe actions using learned dynamics models, effectively restores safety across algorithms and patient populations. Across eight safe RL algorithms, three diabetes types, and three age groups, shielding achieves Time-in-Range gains of 13--14\% for strong baselines such as PPO-Lag and CPO while reducing clinical risk index and glucose variability. Our simulator and benchmark provide a platform for studying safety under distribution shift in safety-critical control domains. Code is available at https://github.com/safe-autonomy-lab/GlucoSim and https://github.com/safe-autonomy-lab/GlucoAlg.
Explaining Decentralized Multi-Agent Reinforcement Learning Policies
Nov 13, 2025Multi-Agent Reinforcement Learning (MARL) has gained significant interest in recent years, enabling sequential decision-making across multiple agents in various domains. However, most existing explanation methods focus on centralized MARL, failing to address the uncertainty and nondeterminism inherent in decentralized settings. We propose methods to generate policy summarizations that capture task ordering and agent cooperation in decentralized MARL policies, along with query-based explanations for When, Why Not, and What types of user queries about specific agent behaviors. We evaluate our approach across four MARL domains and two decentralized MARL algorithms, demonstrating its generalizability and computational efficiency. User studies show that our summarizations and explanations significantly improve user question-answering performance and enhance subjective ratings on metrics such as understanding and satisfaction.
Counterfactual Explanations for Continuous Action Reinforcement Learning
May 19, 2025Reinforcement Learning (RL) has shown great promise in domains like healthcare and robotics but often struggles with adoption due to its lack of interpretability. Counterfactual explanations, which address "what if" scenarios, provide a promising avenue for understanding RL decisions but remain underexplored for continuous action spaces. We propose a novel approach for generating counterfactual explanations in continuous action RL by computing alternative action sequences that improve outcomes while minimizing deviations from the original sequence. Our approach leverages a distance metric for continuous actions and accounts for constraints such as adhering to predefined policies in specific states. Evaluations in two RL domains, Diabetes Control and Lunar Lander, demonstrate the effectiveness, efficiency, and generalization of our approach, enabling more interpretable and trustworthy RL applications.
IrrMap: A Large-Scale Comprehensive Dataset for Irrigation Method Mapping
May 13, 2025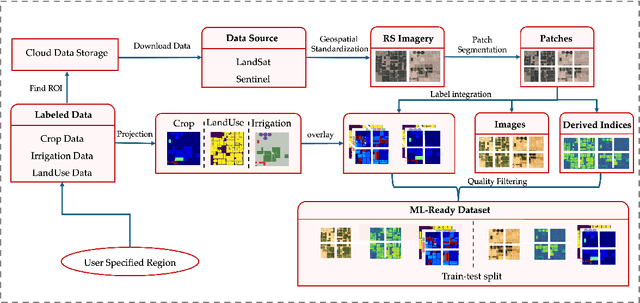
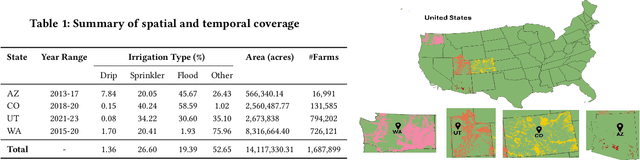

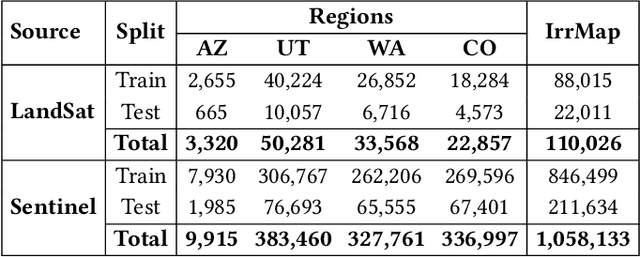
We introduce IrrMap, the first large-scale dataset (1.1 million patches) for irrigation method mapping across regions. IrrMap consists of multi-resolution satellite imagery from LandSat and Sentinel, along with key auxiliary data such as crop type, land use, and vegetation indices. The dataset spans 1,687,899 farms and 14,117,330 acres across multiple western U.S. states from 2013 to 2023, providing a rich and diverse foundation for irrigation analysis and ensuring geospatial alignment and quality control. The dataset is ML-ready, with standardized 224x224 GeoTIFF patches, the multiple input modalities, carefully chosen train-test-split data, and accompanying dataloaders for seamless deep learning model training andbenchmarking in irrigation mapping. The dataset is also accompanied by a complete pipeline for dataset generation, enabling researchers to extend IrrMap to new regions for irrigation data collection or adapt it with minimal effort for other similar applications in agricultural and geospatial analysis. We also analyze the irrigation method distribution across crop groups, spatial irrigation patterns (using Shannon diversity indices), and irrigated area variations for both LandSat and Sentinel, providing insights into regional and resolution-based differences. To promote further exploration, we openly release IrrMap, along with the derived datasets, benchmark models, and pipeline code, through a GitHub repository: https://github.com/Nibir088/IrrMap and Data repository: https://huggingface.co/Nibir/IrrMap, providing comprehensive documentation and implementation details.
Evaluating Human Trust in LLM-Based Planners: A Preliminary Study
Feb 27, 2025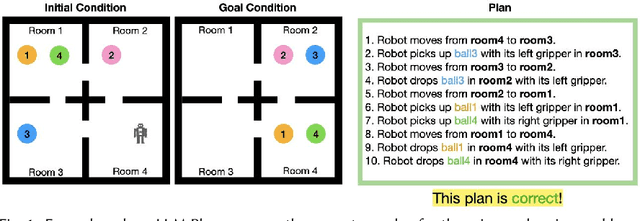

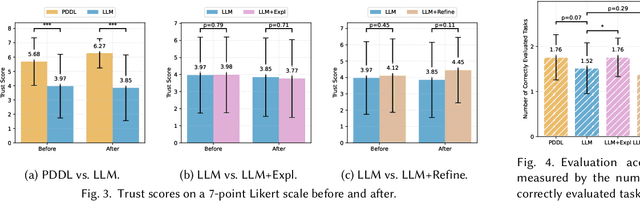
Large Language Models (LLMs) are increasingly used for planning tasks, offering unique capabilities not found in classical planners such as generating explanations and iterative refinement. However, trust--a critical factor in the adoption of planning systems--remains underexplored in the context of LLM-based planning tasks. This study bridges this gap by comparing human trust in LLM-based planners with classical planners through a user study in a Planning Domain Definition Language (PDDL) domain. Combining subjective measures, such as trust questionnaires, with objective metrics like evaluation accuracy, our findings reveal that correctness is the primary driver of trust and performance. Explanations provided by the LLM improved evaluation accuracy but had limited impact on trust, while plan refinement showed potential for increasing trust without significantly enhancing evaluation accuracy.
Quantitative Predictive Monitoring and Control for Safe Human-Machine Interaction
Dec 17, 2024



There is a growing trend toward AI systems interacting with humans to revolutionize a range of application domains such as healthcare and transportation. However, unsafe human-machine interaction can lead to catastrophic failures. We propose a novel approach that predicts future states by accounting for the uncertainty of human interaction, monitors whether predictions satisfy or violate safety requirements, and adapts control actions based on the predictive monitoring results. Specifically, we develop a new quantitative predictive monitor based on Signal Temporal Logic with Uncertainty (STL-U) to compute a robustness degree interval, which indicates the extent to which a sequence of uncertain predictions satisfies or violates an STL-U requirement. We also develop a new loss function to guide the uncertainty calibration of Bayesian deep learning and a new adaptive control method, both of which leverage STL-U quantitative predictive monitoring results. We apply the proposed approach to two case studies: Type 1 Diabetes management and semi-autonomous driving. Experiments show that the proposed approach improves safety and effectiveness in both case studies.
Adaptive Reward Design for Reinforcement Learning in Complex Robotic Tasks
Dec 14, 2024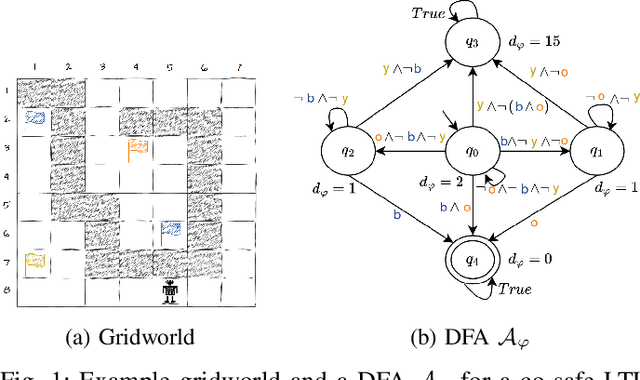
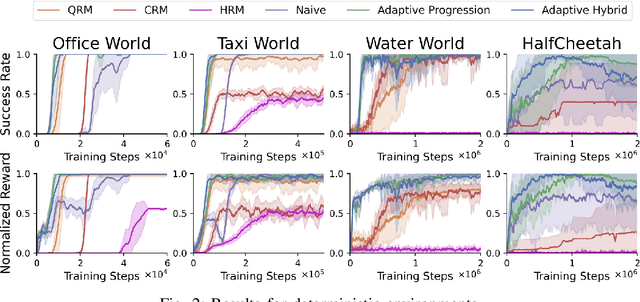
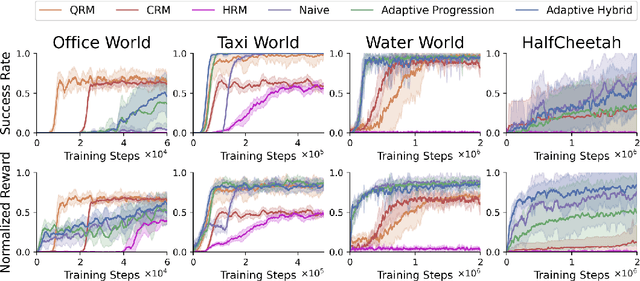
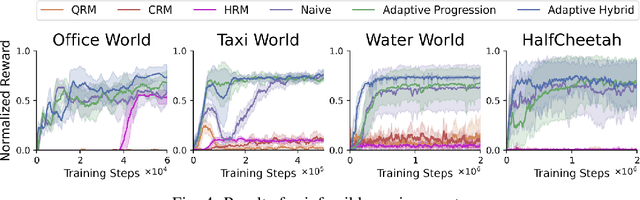
There is a surge of interest in using formal languages such as Linear Temporal Logic (LTL) and finite automata to precisely and succinctly specify complex tasks and derive reward functions for reinforcement learning (RL) in robotic applications. However, existing methods often assign sparse rewards (e.g., giving a reward of 1 only if a task is completed and 0 otherwise), necessitating extensive exploration to converge to a high-quality policy. To address this limitation, we propose a suite of reward functions that incentivize an RL agent to make measurable progress on tasks specified by LTL formulas and develop an adaptive reward shaping approach that dynamically updates these reward functions during the learning process. Experimental results on a range of RL-based robotic tasks demonstrate that the proposed approach is compatible with various RL algorithms and consistently outperforms baselines, achieving earlier convergence to better policies with higher task success rates and returns.