 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe POMDP Online Planning among Dynamic Agents via Adaptive Conformal Prediction
Apr 23, 2024Online planning for partially observable Markov decision processes (POMDPs) provides efficient techniques for robot decision-making under uncertainty. However, existing methods fall short of preventing safety violations in dynamic environments. This work presents a novel safe POMDP online planning approach that offers probabilistic safety guarantees amidst environments populated by multiple dynamic agents. Our approach utilizes data-driven trajectory prediction models of dynamic agents and applies Adaptive Conformal Prediction (ACP) for assessing the uncertainties in these predictions. Leveraging the obtained ACP-based trajectory predictions, our approach constructs safety shields on-the-fly to prevent unsafe actions within POMDP online planning. Through experimental evaluation in various dynamic environments using real-world pedestrian trajectory data, the proposed approach has been shown to effectively maintain probabilistic safety guarantees while accommodating up to hundreds of dynamic agents.
Trust-Aware Motion Planning for Human-Robot Collaboration under Distribution Temporal Logic Specifications
Oct 02, 2023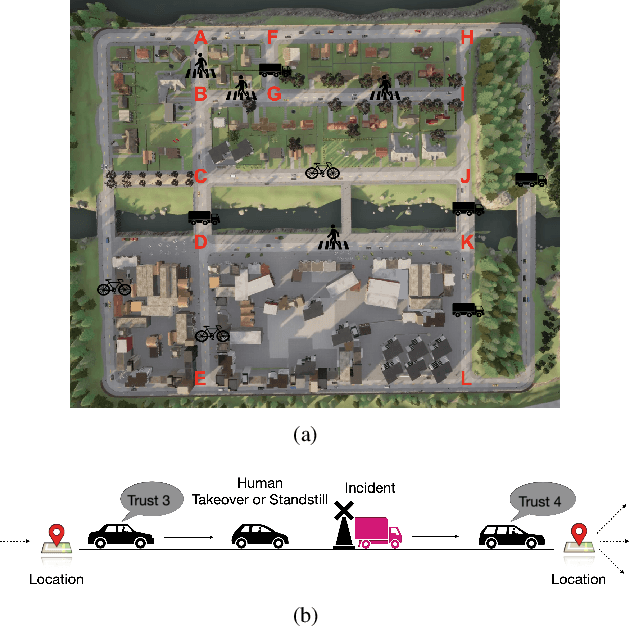
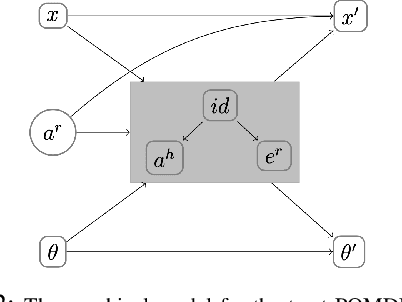

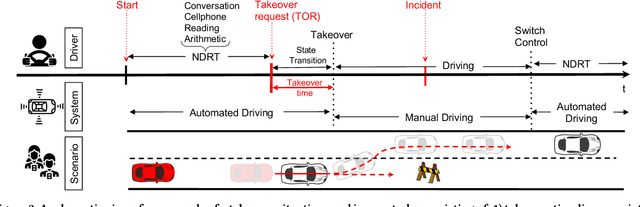
Recent work has considered trust-aware decision making for human-robot collaboration (HRC) with a focus on model learning. In this paper, we are interested in enabling the HRC system to complete complex tasks specified using temporal logic that involve human trust. Since human trust in robots is not observable, we adopt the widely used partially observable Markov decision process (POMDP) framework for modelling the interactions between humans and robots. To specify the desired behaviour, we propose to use syntactically co-safe linear distribution temporal logic (scLDTL), a logic that is defined over predicates of states as well as belief states of partially observable systems. The incorporation of belief predicates in scLDTL enhances its expressiveness while simultaneously introducing added complexity. This also presents a new challenge as the belief predicates must be evaluated over the continuous (infinite) belief space. To address this challenge, we present an algorithm for solving the optimal policy synthesis problem. First, we enhance the belief MDP (derived by reformulating the POMDP) with a probabilistic labelling function. Then a product belief MDP is constructed between the probabilistically labelled belief MDP and the automaton translation of the scLDTL formula. Finally, we show that the optimal policy can be obtained by leveraging existing point-based value iteration algorithms with essential modifications. Human subject experiments with 21 participants on a driving simulator demonstrate the effectiveness of the proposed approach.
Safe POMDP Online Planning via Shielding
Sep 19, 2023Partially observable Markov decision processes (POMDPs) have been widely used in many robotic applications for sequential decision-making under uncertainty. POMDP online planning algorithms such as Partially Observable Monte-Carlo Planning (POMCP) can solve very large POMDPs with the goal of maximizing the expected return. But the resulting policies cannot provide safety guarantees that are imperative for real-world safety-critical tasks (e.g., autonomous driving). In this work, we consider safety requirements represented as almost-sure reach-avoid specifications (i.e., the probability to reach a set of goal states is one and the probability to reach a set of unsafe states is zero). We compute shields that restrict unsafe actions violating almost-sure reach-avoid specifications. We then integrate these shields into the POMCP algorithm for safe POMDP online planning. We propose four distinct shielding methods, differing in how the shields are computed and integrated, including factored variants designed to improve scalability. Experimental results on a set of benchmark domains demonstrate that the proposed shielding methods successfully guarantee safety (unlike the baseline POMCP without shielding) on large POMDPs, with negligible impact on the runtime for online planning.
DeepTake: Prediction of Driver Takeover Behavior using Multimodal Data
Jan 15, 2021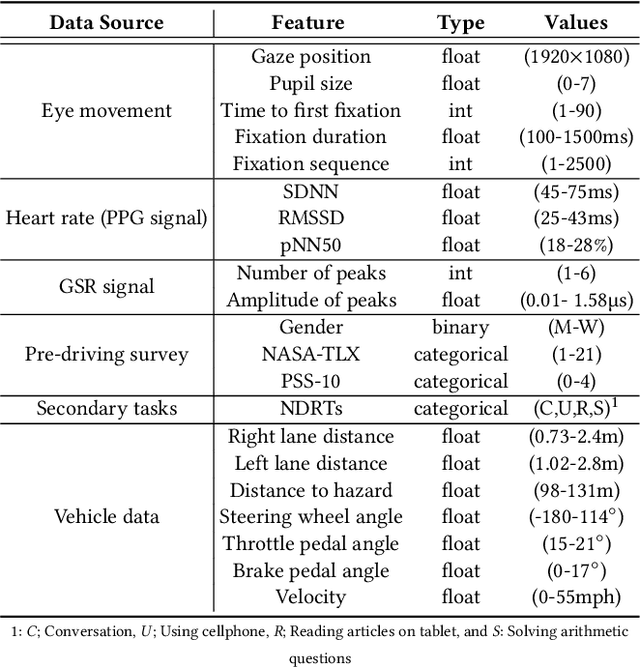
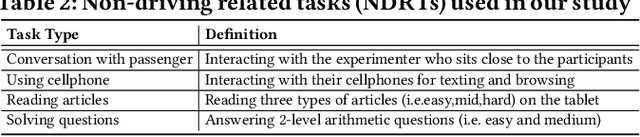
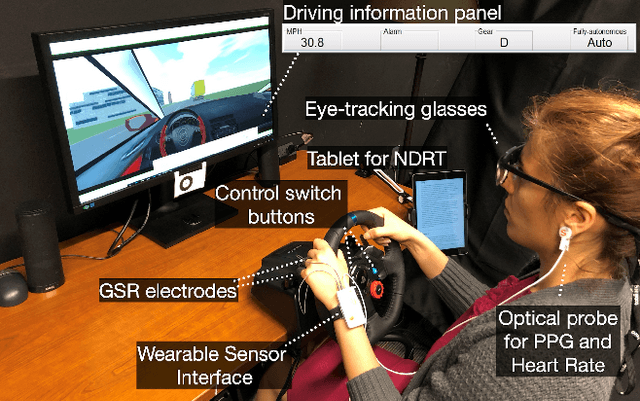
Automated vehicles promise a future where drivers can engage in non-driving tasks without hands on the steering wheels for a prolonged period. Nevertheless, automated vehicles may still need to occasionally hand the control back to drivers due to technology limitations and legal requirements. While some systems determine the need for driver takeover using driver context and road condition to initiate a takeover request, studies show that the driver may not react to it. We present DeepTake, a novel deep neural network-based framework that predicts multiple aspects of takeover behavior to ensure that the driver is able to safely take over the control when engaged in non-driving tasks. Using features from vehicle data, driver biometrics, and subjective measurements, DeepTake predicts the driver's intention, time, and quality of takeover. We evaluate DeepTake performance using multiple evaluation metrics. Results show that DeepTake reliably predicts the takeover intention, time, and quality, with an accuracy of 96%, 93%, and 83%, respectively. Results also indicate that DeepTake outperforms previous state-of-the-art methods on predicting driver takeover time and quality. Our findings have implications for the algorithm development of driver monitoring and state detection.
Probabilistic Conditional System Invariant Generation with Bayesian Inference
Dec 11, 2020
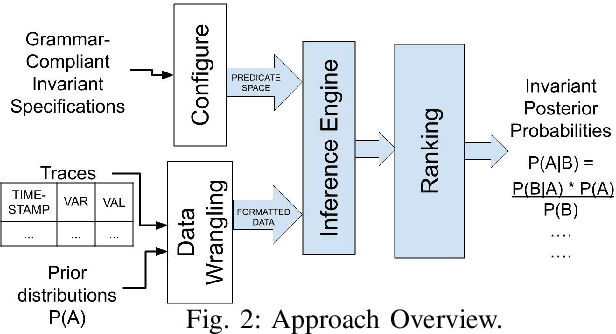

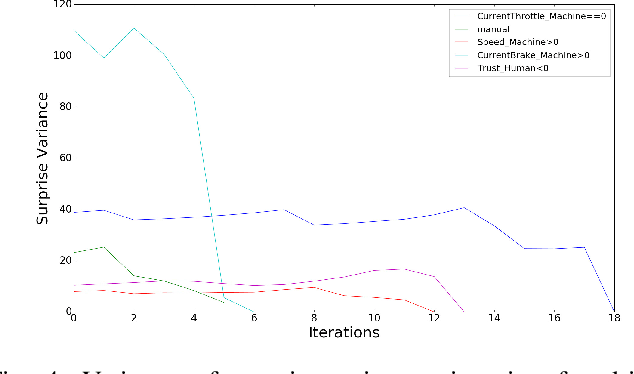
Invariants are a set of properties over program attributes that are expected to be true during the execution of a program. Since developing those invariants manually can be costly and challenging, there are a myriad of approaches that support automated mining of likely invariants from sources such as program traces. Existing approaches, however, are not equipped to capture the rich states that condition the behavior of autonomous mobile robots, or to manage the uncertainty associated with many variables in these systems. This means that valuable invariants that appear only under specific states remain uncovered. In this work we introduce an approach to infer conditional probabilistic invariants to assist in the characterization of the behavior of such rich stateful, stochastic systems. These probabilistic invariants can encode a family of conditional patterns, are generated using Bayesian inference to leverage observed trace data against priors gleaned from previous experience and expert knowledge, and are ranked based on their surprise value and information content. Our studies on two semi-autonomous mobile robotic systems show how the proposed approach is able to generate valuable and previously hidden stateful invariants.