 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Explanations for Continuous Action Reinforcement Learning
May 19, 2025Reinforcement Learning (RL) has shown great promise in domains like healthcare and robotics but often struggles with adoption due to its lack of interpretability. Counterfactual explanations, which address "what if" scenarios, provide a promising avenue for understanding RL decisions but remain underexplored for continuous action spaces. We propose a novel approach for generating counterfactual explanations in continuous action RL by computing alternative action sequences that improve outcomes while minimizing deviations from the original sequence. Our approach leverages a distance metric for continuous actions and accounts for constraints such as adhering to predefined policies in specific states. Evaluations in two RL domains, Diabetes Control and Lunar Lander, demonstrate the effectiveness, efficiency, and generalization of our approach, enabling more interpretable and trustworthy RL applications.
Quantitative Predictive Monitoring and Control for Safe Human-Machine Interaction
Dec 17, 2024



There is a growing trend toward AI systems interacting with humans to revolutionize a range of application domains such as healthcare and transportation. However, unsafe human-machine interaction can lead to catastrophic failures. We propose a novel approach that predicts future states by accounting for the uncertainty of human interaction, monitors whether predictions satisfy or violate safety requirements, and adapts control actions based on the predictive monitoring results. Specifically, we develop a new quantitative predictive monitor based on Signal Temporal Logic with Uncertainty (STL-U) to compute a robustness degree interval, which indicates the extent to which a sequence of uncertain predictions satisfies or violates an STL-U requirement. We also develop a new loss function to guide the uncertainty calibration of Bayesian deep learning and a new adaptive control method, both of which leverage STL-U quantitative predictive monitoring results. We apply the proposed approach to two case studies: Type 1 Diabetes management and semi-autonomous driving. Experiments show that the proposed approach improves safety and effectiveness in both case studies.
Trust-Aware Motion Planning for Human-Robot Collaboration under Distribution Temporal Logic Specifications
Oct 02, 2023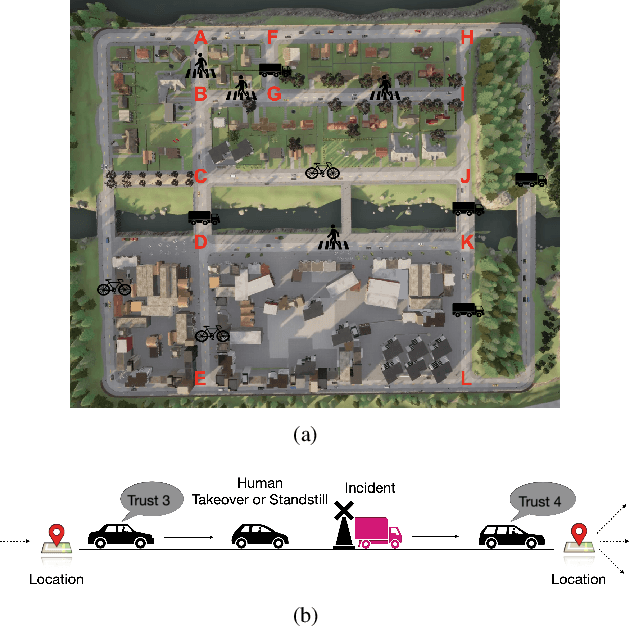
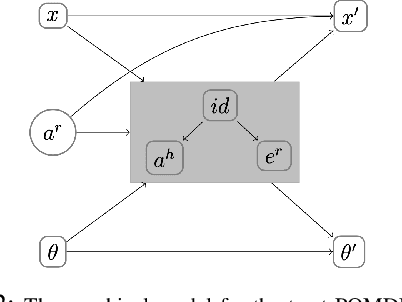

Recent work has considered trust-aware decision making for human-robot collaboration (HRC) with a focus on model learning. In this paper, we are interested in enabling the HRC system to complete complex tasks specified using temporal logic that involve human trust. Since human trust in robots is not observable, we adopt the widely used partially observable Markov decision process (POMDP) framework for modelling the interactions between humans and robots. To specify the desired behaviour, we propose to use syntactically co-safe linear distribution temporal logic (scLDTL), a logic that is defined over predicates of states as well as belief states of partially observable systems. The incorporation of belief predicates in scLDTL enhances its expressiveness while simultaneously introducing added complexity. This also presents a new challenge as the belief predicates must be evaluated over the continuous (infinite) belief space. To address this challenge, we present an algorithm for solving the optimal policy synthesis problem. First, we enhance the belief MDP (derived by reformulating the POMDP) with a probabilistic labelling function. Then a product belief MDP is constructed between the probabilistically labelled belief MDP and the automaton translation of the scLDTL formula. Finally, we show that the optimal policy can be obtained by leveraging existing point-based value iteration algorithms with essential modifications. Human subject experiments with 21 participants on a driving simulator demonstrate the effectiveness of the proposed approach.