 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoPro-Net: Learning Interpretable Spatiotemporal Prediction Models through Statistically-Guided Geo-Prototyping
Dec 19, 2024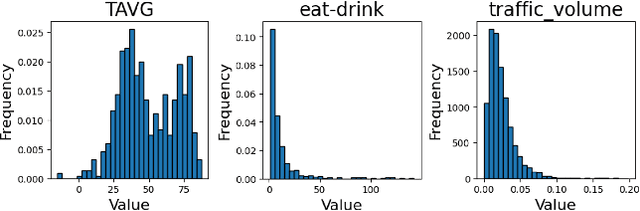
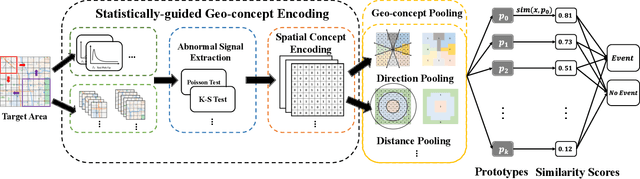
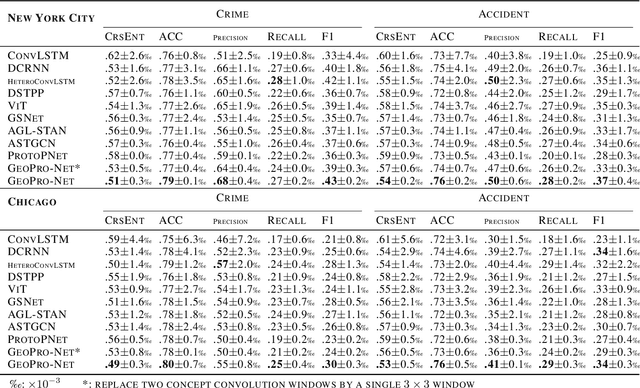
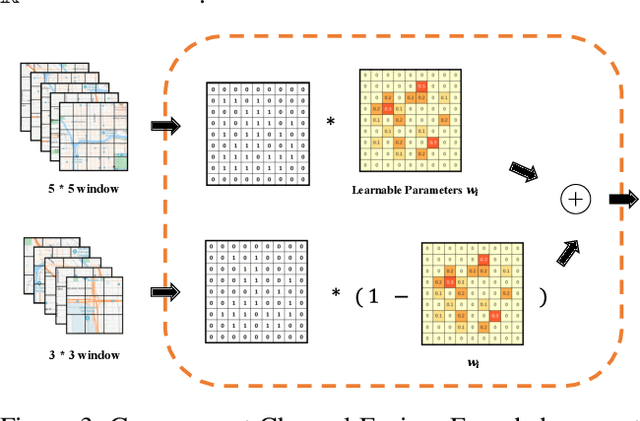
The problem of forecasting spatiotemporal events such as crimes and accidents is crucial to public safety and city management. Besides accuracy, interpretability is also a key requirement for spatiotemporal forecasting models to justify the decisions. Interpretation of the spatiotemporal forecasting mechanism is, however, challenging due to the complexity of multi-source spatiotemporal features, the non-intuitive nature of spatiotemporal patterns for non-expert users, and the presence of spatial heterogeneity in the data. Currently, no existing deep learning model intrinsically interprets the complex predictive process learned from multi-source spatiotemporal features. To bridge the gap, we propose GeoPro-Net, an intrinsically interpretable spatiotemporal model for spatiotemporal event forecasting problems. GeoPro-Net introduces a novel Geo-concept convolution operation, which employs statistical tests to extract predictive patterns in the input as Geo-concepts, and condenses the Geo-concept-encoded input through interpretable channel fusion and geographic-based pooling. In addition, GeoPro-Net learns different sets of prototypes of concepts inherently, and projects them to real-world cases for interpretation. Comprehensive experiments and case studies on four real-world datasets demonstrate that GeoPro-Net provides better interpretability while still achieving competitive prediction performance compared with state-of-the-art baselines.
From Model Explanation to Data Misinterpretation: Uncovering the Pitfalls of Post Hoc Explainers in Business Research
Aug 30, 2024



Machine learning models have been increasingly used in business research. However, most state-of-the-art machine learning models, such as deep neural networks and XGBoost, are black boxes in nature. Therefore, post hoc explainers that provide explanations for machine learning models by, for example, estimating numerical importance of the input features, have been gaining wide usage. Despite the intended use of post hoc explainers being explaining machine learning models, we found a growing trend in business research where post hoc explanations are used to draw inferences about the data. In this work, we investigate the validity of such use. Specifically, we investigate with extensive experiments whether the explanations obtained by the two most popular post hoc explainers, SHAP and LIME, provide correct information about the true marginal effects of X on Y in the data, which we call data-alignment. We then identify what factors influence the alignment of explanations. Finally, we propose a set of mitigation strategies to improve the data-alignment of explanations and demonstrate their effectiveness with real-world data in an econometric context. In spite of this effort, we nevertheless conclude that it is often not appropriate to infer data insights from post hoc explanations. We articulate appropriate alternative uses, the most important of which is to facilitate the proposition and subsequent empirical investigation of hypotheses. The ultimate goal of this paper is to caution business researchers against translating post hoc explanations of machine learning models into potentially false insights and understanding of data.