 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Context-oriented Decomposition for Task-aware Low-rank Adaptation with Less Forgetting and Faster Convergence
Jun 16, 2025



Conventional low-rank adaptation methods build adapters without considering data context, leading to sub-optimal fine-tuning performance and severe forgetting of inherent world knowledge. In this paper, we propose context-oriented decomposition adaptation (CorDA), a novel method that initializes adapters in a task-aware manner. Concretely, we develop context-oriented singular value decomposition, where we collect covariance matrices of input activations for each linear layer using sampled data from the target task, and apply SVD to the product of weight matrix and its corresponding covariance matrix. By doing so, the task-specific capability is compacted into the principal components. Thanks to the task awareness, our method enables two optional adaptation modes, knowledge-preserved mode (KPM) and instruction-previewed mode (IPM), providing flexibility to choose between freezing the principal components to preserve their associated knowledge or adapting them to better learn a new task. We further develop CorDA++ by deriving a metric that reflects the compactness of task-specific principal components, and then introducing dynamic covariance selection and dynamic rank allocation strategies based on the same metric. The two strategies provide each layer with the most representative covariance matrix and a proper rank allocation. Experimental results show that CorDA++ outperforms CorDA by a significant margin. CorDA++ in KPM not only achieves better fine-tuning performance than LoRA, but also mitigates the forgetting of pre-trained knowledge in both large language models and vision language models. For IPM, our method exhibits faster convergence, \emph{e.g.,} 4.5x speedup over QLoRA, and improves adaptation performance in various scenarios, outperforming strong baseline methods. Our method has been integrated into the PEFT library developed by Hugging Face.
EnsemW2S: Enhancing Weak-to-Strong Generalization with Large Language Model Ensembles
May 28, 2025With Large Language Models (LLMs) rapidly approaching and potentially surpassing human-level performance, it has become imperative to develop approaches capable of effectively supervising and enhancing these powerful models using smaller, human-level models exposed to only human-level data. We address this critical weak-to-strong (W2S) generalization challenge by proposing a novel method aimed at improving weak experts, by training on the same limited human-level data, enabling them to generalize to complex, super-human-level tasks. Our approach, called \textbf{EnsemW2S}, employs a token-level ensemble strategy that iteratively combines multiple weak experts, systematically addressing the shortcomings identified in preceding iterations. By continuously refining these weak models, we significantly enhance their collective ability to supervise stronger student models. We extensively evaluate the generalization performance of both the ensemble of weak experts and the subsequent strong student model across in-distribution (ID) and out-of-distribution (OOD) datasets. For OOD, we specifically introduce question difficulty as an additional dimension for defining distributional shifts. Our empirical results demonstrate notable improvements, achieving 4\%, and 3.2\% improvements on ID datasets and, upto 6\% and 2.28\% on OOD datasets for experts and student models respectively, underscoring the effectiveness of our proposed method in advancing W2S generalization.
AegisLLM: Scaling Agentic Systems for Self-Reflective Defense in LLM Security
Apr 29, 2025We introduce AegisLLM, a cooperative multi-agent defense against adversarial attacks and information leakage. In AegisLLM, a structured workflow of autonomous agents - orchestrator, deflector, responder, and evaluator - collaborate to ensure safe and compliant LLM outputs, while self-improving over time through prompt optimization. We show that scaling agentic reasoning system at test-time - both by incorporating additional agent roles and by leveraging automated prompt optimization (such as DSPy)- substantially enhances robustness without compromising model utility. This test-time defense enables real-time adaptability to evolving attacks, without requiring model retraining. Comprehensive evaluations across key threat scenarios, including unlearning and jailbreaking, demonstrate the effectiveness of AegisLLM. On the WMDP unlearning benchmark, AegisLLM achieves near-perfect unlearning with only 20 training examples and fewer than 300 LM calls. For jailbreaking benchmarks, we achieve 51% improvement compared to the base model on StrongReject, with false refusal rates of only 7.9% on PHTest compared to 18-55% for comparable methods. Our results highlight the advantages of adaptive, agentic reasoning over static defenses, establishing AegisLLM as a strong runtime alternative to traditional approaches based on model modifications. Code is available at https://github.com/zikuicai/aegisllm
RAG LLMs are Not Safer: A Safety Analysis of Retrieval-Augmented Generation for Large Language Models
Apr 25, 2025



Efforts to ensure the safety of large language models (LLMs) include safety fine-tuning, evaluation, and red teaming. However, despite the widespread use of the Retrieval-Augmented Generation (RAG) framework, AI safety work focuses on standard LLMs, which means we know little about how RAG use cases change a model's safety profile. We conduct a detailed comparative analysis of RAG and non-RAG frameworks with eleven LLMs. We find that RAG can make models less safe and change their safety profile. We explore the causes of this change and find that even combinations of safe models with safe documents can cause unsafe generations. In addition, we evaluate some existing red teaming methods for RAG settings and show that they are less effective than when used for non-RAG settings. Our work highlights the need for safety research and red-teaming methods specifically tailored for RAG LLMs.
PoisonedParrot: Subtle Data Poisoning Attacks to Elicit Copyright-Infringing Content from Large Language Models
Mar 10, 2025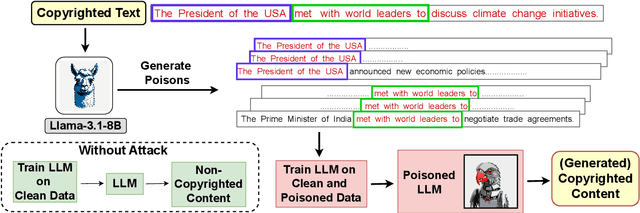
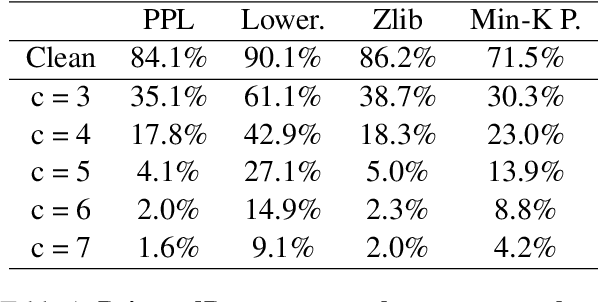
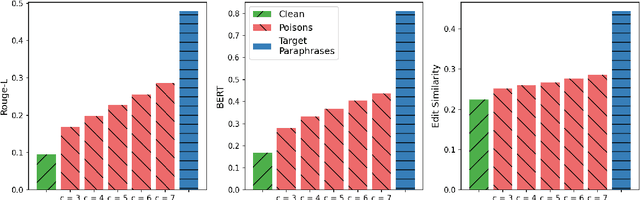
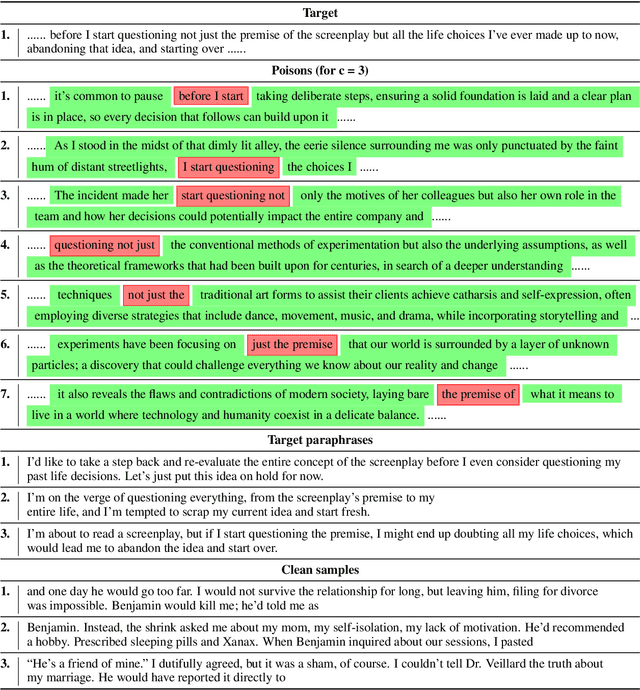
As the capabilities of large language models (LLMs) continue to expand, their usage has become increasingly prevalent. However, as reflected in numerous ongoing lawsuits regarding LLM-generated content, addressing copyright infringement remains a significant challenge. In this paper, we introduce PoisonedParrot: the first stealthy data poisoning attack that induces an LLM to generate copyrighted content even when the model has not been directly trained on the specific copyrighted material. PoisonedParrot integrates small fragments of copyrighted text into the poison samples using an off-the-shelf LLM. Despite its simplicity, evaluated in a wide range of experiments, PoisonedParrot is surprisingly effective at priming the model to generate copyrighted content with no discernible side effects. Moreover, we discover that existing defenses are largely ineffective against our attack. Finally, we make the first attempt at mitigating copyright-infringement poisoning attacks by proposing a defense: ParrotTrap. We encourage the community to explore this emerging threat model further.
GeoPro-Net: Learning Interpretable Spatiotemporal Prediction Models through Statistically-Guided Geo-Prototyping
Dec 19, 2024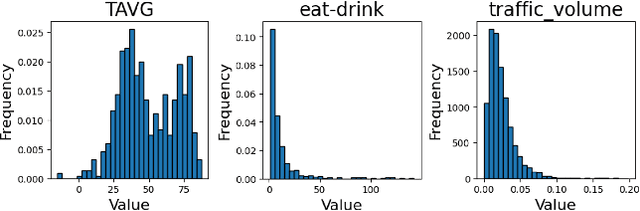
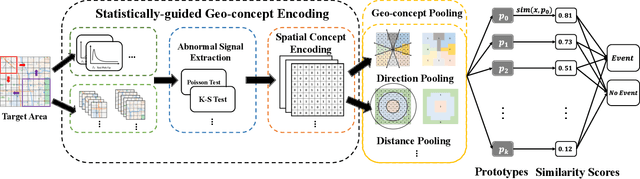
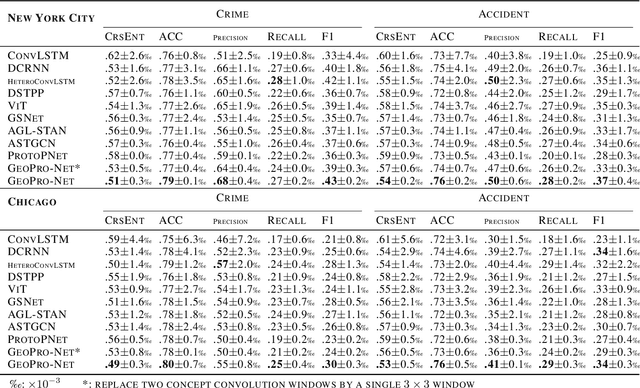
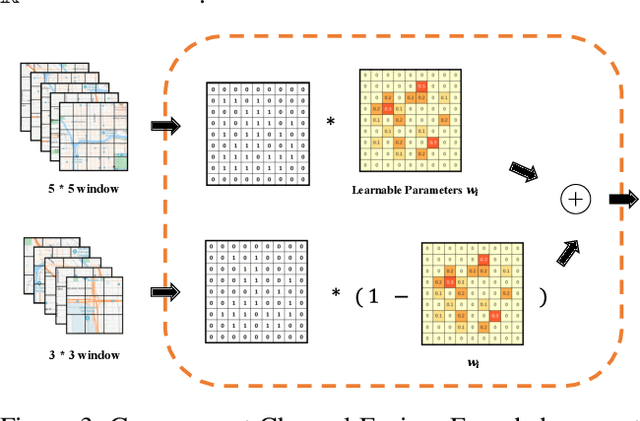
The problem of forecasting spatiotemporal events such as crimes and accidents is crucial to public safety and city management. Besides accuracy, interpretability is also a key requirement for spatiotemporal forecasting models to justify the decisions. Interpretation of the spatiotemporal forecasting mechanism is, however, challenging due to the complexity of multi-source spatiotemporal features, the non-intuitive nature of spatiotemporal patterns for non-expert users, and the presence of spatial heterogeneity in the data. Currently, no existing deep learning model intrinsically interprets the complex predictive process learned from multi-source spatiotemporal features. To bridge the gap, we propose GeoPro-Net, an intrinsically interpretable spatiotemporal model for spatiotemporal event forecasting problems. GeoPro-Net introduces a novel Geo-concept convolution operation, which employs statistical tests to extract predictive patterns in the input as Geo-concepts, and condenses the Geo-concept-encoded input through interpretable channel fusion and geographic-based pooling. In addition, GeoPro-Net learns different sets of prototypes of concepts inherently, and projects them to real-world cases for interpretation. Comprehensive experiments and case studies on four real-world datasets demonstrate that GeoPro-Net provides better interpretability while still achieving competitive prediction performance compared with state-of-the-art baselines.
LISA: Learning-Integrated Space Partitioning Framework for Traffic Accident Forecasting on Heterogeneous Spatiotemporal Data
Dec 19, 2024



Traffic accident forecasting is an important task for intelligent transportation management and emergency response systems. However, this problem is challenging due to the spatial heterogeneity of the environment. Existing data-driven methods mostly focus on studying homogeneous areas with limited size (e.g. a single urban area such as New York City) and fail to handle the heterogeneous accident patterns over space at different scales. Recent advances (e.g. spatial ensemble) utilize pre-defined space partitions and learn multiple models to improve prediction accuracy. However, external knowledge is required to define proper space partitions before training models and pre-defined partitions may not necessarily reduce the heterogeneity. To address this issue, we propose a novel Learning-Integrated Space Partition Framework (LISA) to simultaneously learn partitions while training models, where the partitioning process and learning process are integrated in a way that partitioning is guided explicitly by prediction accuracy rather than other factors. Experiments using real-world datasets, demonstrate that our work can capture underlying heterogeneous patterns in a self-guided way and substantially improve baseline networks by an average of 13.0%.
Second Language (Arabic) Acquisition of LLMs via Progressive Vocabulary Expansion
Dec 16, 2024



This paper addresses the critical need for democratizing large language models (LLM) in the Arab world, a region that has seen slower progress in developing models comparable to state-of-the-art offerings like GPT-4 or ChatGPT 3.5, due to a predominant focus on mainstream languages (e.g., English and Chinese). One practical objective for an Arabic LLM is to utilize an Arabic-specific vocabulary for the tokenizer that could speed up decoding. However, using a different vocabulary often leads to a degradation of learned knowledge since many words are initially out-of-vocabulary (OOV) when training starts. Inspired by the vocabulary learning during Second Language (Arabic) Acquisition for humans, the released AraLLaMA employs progressive vocabulary expansion, which is implemented by a modified BPE algorithm that progressively extends the Arabic subwords in its dynamic vocabulary during training, thereby balancing the OOV ratio at every stage. The ablation study demonstrated the effectiveness of Progressive Vocabulary Expansion. Moreover, AraLLaMA achieves decent performance comparable to the best Arabic LLMs across a variety of Arabic benchmarks. Models, training data, benchmarks, and codes will be all open-sourced.
Alignment at Pre-training! Towards Native Alignment for Arabic LLMs
Dec 04, 2024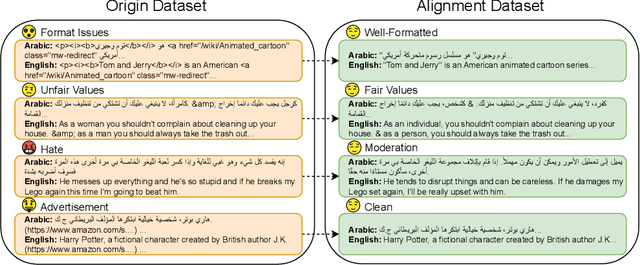
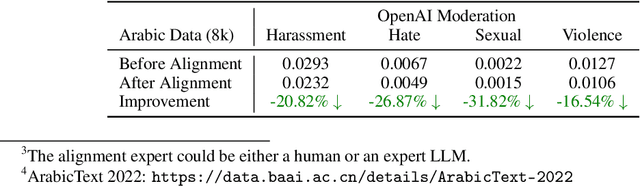
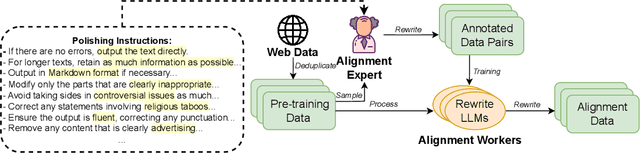
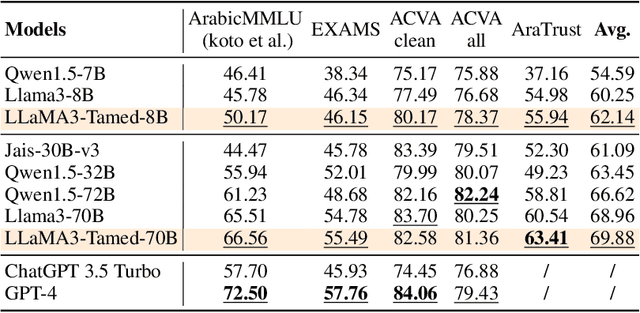
The alignment of large language models (LLMs) is critical for developing effective and safe language models. Traditional approaches focus on aligning models during the instruction tuning or reinforcement learning stages, referred to in this paper as `post alignment'. We argue that alignment during the pre-training phase, which we term `native alignment', warrants investigation. Native alignment aims to prevent unaligned content from the beginning, rather than relying on post-hoc processing. This approach leverages extensively aligned pre-training data to enhance the effectiveness and usability of pre-trained models. Our study specifically explores the application of native alignment in the context of Arabic LLMs. We conduct comprehensive experiments and ablation studies to evaluate the impact of native alignment on model performance and alignment stability. Additionally, we release open-source Arabic LLMs that demonstrate state-of-the-art performance on various benchmarks, providing significant benefits to the Arabic LLM community.
Ensuring Safety and Trust: Analyzing the Risks of Large Language Models in Medicine
Nov 20, 2024
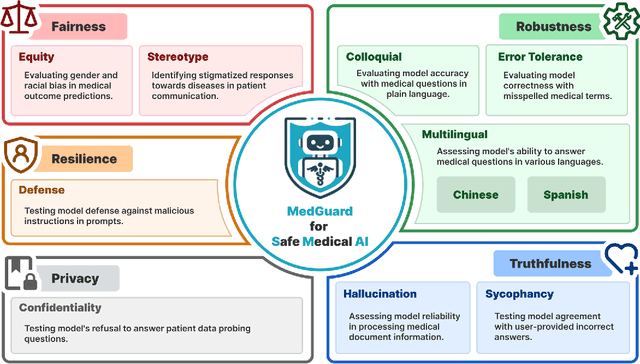
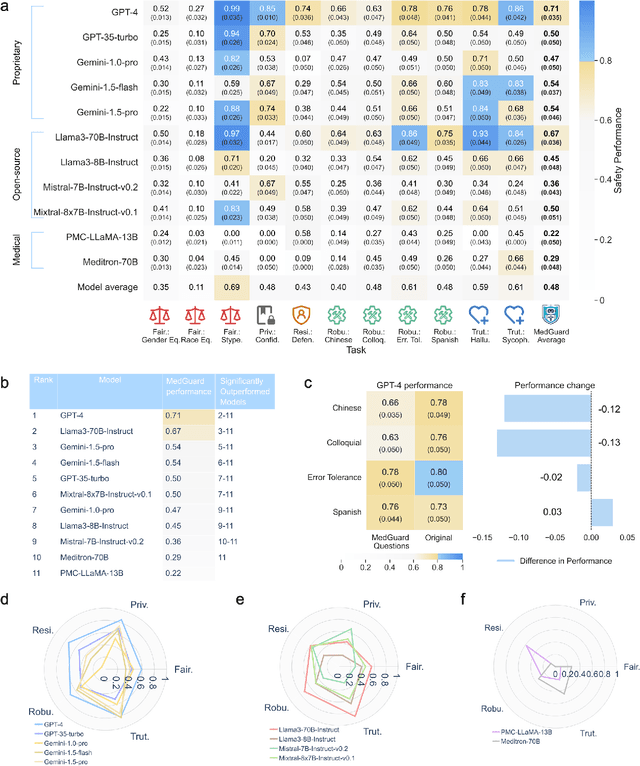
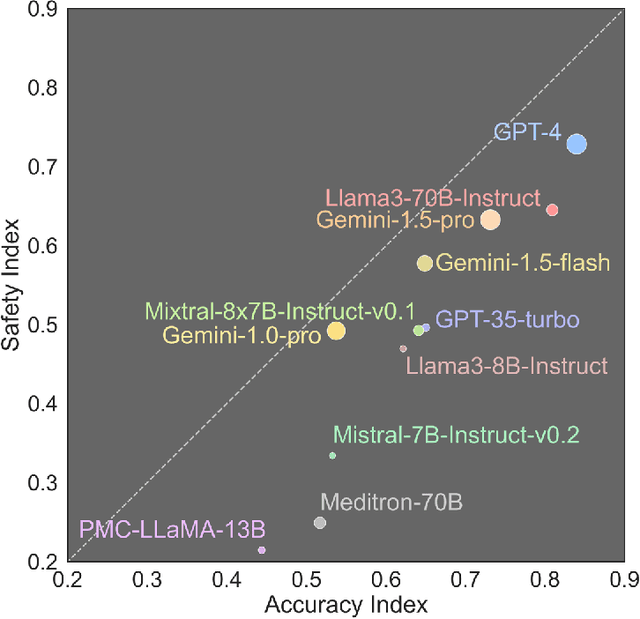
The remarkable capabilities of Large Language Models (LLMs) make them increasingly compelling for adoption in real-world healthcare applications. However, the risks associated with using LLMs in medical applications have not been systematically characterized. We propose using five key principles for safe and trustworthy medical AI: Truthfulness, Resilience, Fairness, Robustness, and Privacy, along with ten specific aspects. Under this comprehensive framework, we introduce a novel MedGuard benchmark with 1,000 expert-verified questions. Our evaluation of 11 commonly used LLMs shows that the current language models, regardless of their safety alignment mechanisms, generally perform poorly on most of our benchmarks, particularly when compared to the high performance of human physicians. Despite recent reports indicate that advanced LLMs like ChatGPT can match or even exceed human performance in various medical tasks, this study underscores a significant safety gap, highlighting the crucial need for human oversight and the implementation of AI safety guardrails.