 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo What Extent Do Token-Level Representations from Pathology Foundation Models Improve Dense Prediction?
Feb 03, 2026Pathology foundation models (PFMs) have rapidly advanced and are becoming a common backbone for downstream clinical tasks, offering strong transferability across tissues and institutions. However, for dense prediction (e.g., segmentation), practical deployment still lacks a clear, reproducible understanding of how different PFMs behave across datasets and how adaptation choices affect performance and stability. We present PFM-DenseBench, a large-scale benchmark for dense pathology prediction, evaluating 17 PFMs across 18 public segmentation datasets. Under a unified protocol, we systematically assess PFMs with multiple adaptation and fine-tuning strategies, and derive insightful, practice-oriented findings on when and why different PFMs and tuning choices succeed or fail across heterogeneous datasets. We release containers, configs, and dataset cards to enable reproducible evaluation and informed PFM selection for real-world dense pathology tasks. Project Website: https://m4a1tastegood.github.io/PFM-DenseBench
DentalGPT: Incentivizing Multimodal Complex Reasoning in Dentistry
Dec 12, 2025Reliable interpretation of multimodal data in dentistry is essential for automated oral healthcare, yet current multimodal large language models (MLLMs) struggle to capture fine-grained dental visual details and lack sufficient reasoning ability for precise diagnosis. To address these limitations, we present DentalGPT, a specialized dental MLLM developed through high-quality domain knowledge injection and reinforcement learning. Specifically, the largest annotated multimodal dataset for dentistry to date was constructed by aggregating over 120k dental images paired with detailed descriptions that highlight diagnostically relevant visual features, making it the multimodal dataset with the most extensive collection of dental images to date. Training on this dataset significantly enhances the MLLM's visual understanding of dental conditions, while the subsequent reinforcement learning stage further strengthens its capability for multimodal complex reasoning. Comprehensive evaluations on intraoral and panoramic benchmarks, along with dental subsets of medical VQA benchmarks, show that DentalGPT achieves superior performance in disease classification and dental VQA tasks, outperforming many state-of-the-art MLLMs despite having only 7B parameters. These results demonstrate that high-quality dental data combined with staged adaptation provides an effective pathway for building capable and domain-specialized dental MLLMs.
Can Multimodal LLMs See Materials Clearly? A Multimodal Benchmark on Materials Characterization
Sep 11, 2025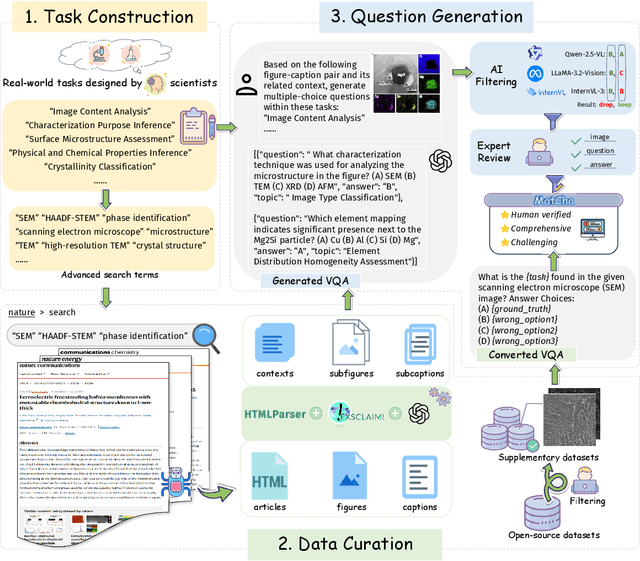
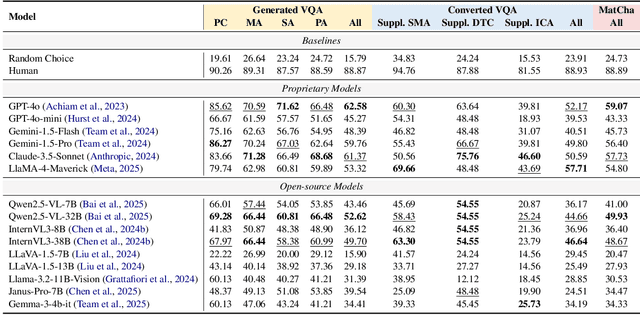
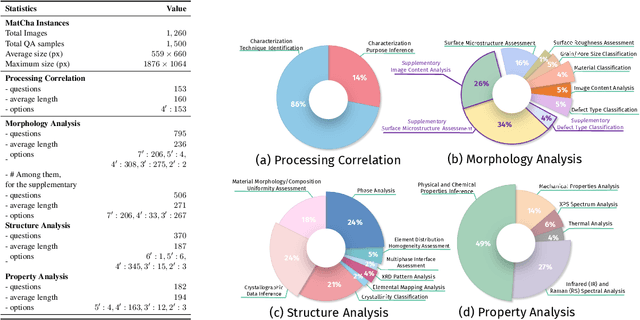
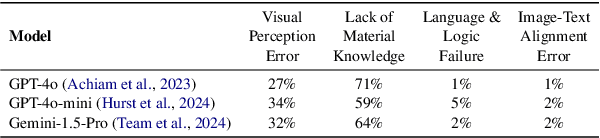
Materials characterization is fundamental to acquiring materials information, revealing the processing-microstructure-property relationships that guide material design and optimization. While multimodal large language models (MLLMs) have recently shown promise in generative and predictive tasks within materials science, their capacity to understand real-world characterization imaging data remains underexplored. To bridge this gap, we present MatCha, the first benchmark for materials characterization image understanding, comprising 1,500 questions that demand expert-level domain expertise. MatCha encompasses four key stages of materials research comprising 21 distinct tasks, each designed to reflect authentic challenges faced by materials scientists. Our evaluation of state-of-the-art MLLMs on MatCha reveals a significant performance gap compared to human experts. These models exhibit degradation when addressing questions requiring higher-level expertise and sophisticated visual perception. Simple few-shot and chain-of-thought prompting struggle to alleviate these limitations. These findings highlight that existing MLLMs still exhibit limited adaptability to real-world materials characterization scenarios. We hope MatCha will facilitate future research in areas such as new material discovery and autonomous scientific agents. MatCha is available at https://github.com/FreedomIntelligence/MatCha.
ShizhenGPT: Towards Multimodal LLMs for Traditional Chinese Medicine
Aug 20, 2025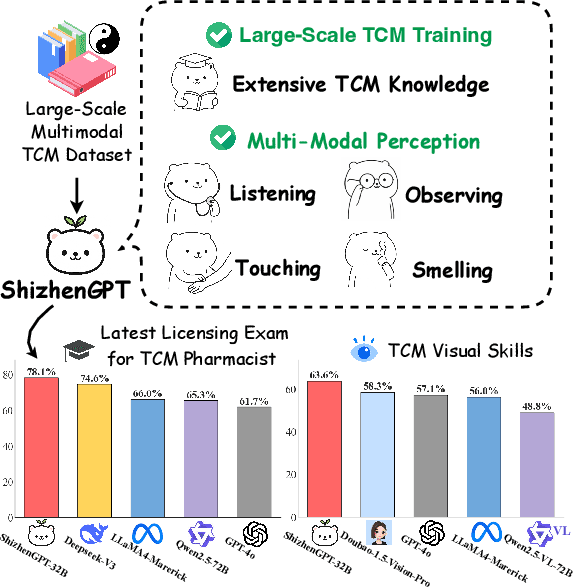
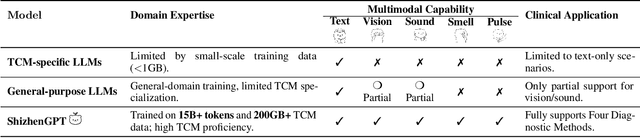
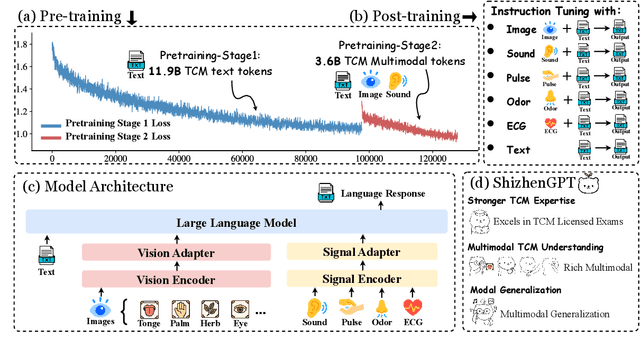
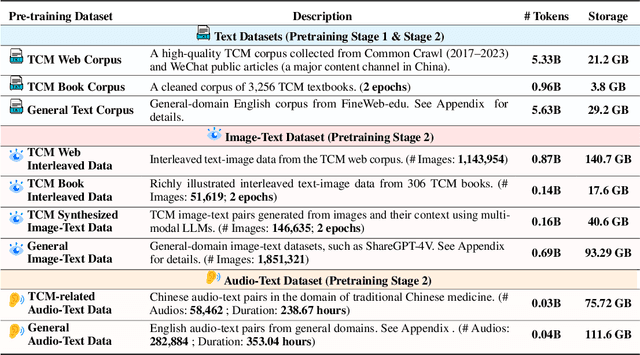
Despite the success of large language models (LLMs) in various domains, their potential in Traditional Chinese Medicine (TCM) remains largely underexplored due to two critical barriers: (1) the scarcity of high-quality TCM data and (2) the inherently multimodal nature of TCM diagnostics, which involve looking, listening, smelling, and pulse-taking. These sensory-rich modalities are beyond the scope of conventional LLMs. To address these challenges, we present ShizhenGPT, the first multimodal LLM tailored for TCM. To overcome data scarcity, we curate the largest TCM dataset to date, comprising 100GB+ of text and 200GB+ of multimodal data, including 1.2M images, 200 hours of audio, and physiological signals. ShizhenGPT is pretrained and instruction-tuned to achieve deep TCM knowledge and multimodal reasoning. For evaluation, we collect recent national TCM qualification exams and build a visual benchmark for Medicinal Recognition and Visual Diagnosis. Experiments demonstrate that ShizhenGPT outperforms comparable-scale LLMs and competes with larger proprietary models. Moreover, it leads in TCM visual understanding among existing multimodal LLMs and demonstrates unified perception across modalities like sound, pulse, smell, and vision, paving the way toward holistic multimodal perception and diagnosis in TCM. Datasets, models, and code are publicly available. We hope this work will inspire further exploration in this field.
On the Compositional Generalization of Multimodal LLMs for Medical Imaging
Dec 28, 2024



Multimodal large language models (MLLMs) hold significant potential in the medical field, but their capabilities are often limited by insufficient data in certain medical domains, highlighting the need for understanding what kinds of images can be used by MLLMs for generalization. Current research suggests that multi-task training outperforms single-task as different tasks can benefit each other, but they often overlook the internal relationships within these tasks, providing limited guidance on selecting datasets to enhance specific tasks. To analyze this phenomenon, we attempted to employ compositional generalization (CG)-the ability of models to understand novel combinations by recombining learned elements-as a guiding framework. Since medical images can be precisely defined by Modality, Anatomical area, and Task, naturally providing an environment for exploring CG. Therefore, we assembled 106 medical datasets to create Med-MAT for comprehensive experiments. The experiments confirmed that MLLMs can use CG to understand unseen medical images and identified CG as one of the main drivers of the generalization observed in multi-task training. Additionally, further studies demonstrated that CG effectively supports datasets with limited data and delivers consistent performance across different backbones, highlighting its versatility and broad applicability. Med-MAT is publicly available at https://github.com/FreedomIntelligence/Med-MAT.
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs
Dec 25, 2024



The breakthrough of OpenAI o1 highlights the potential of enhancing reasoning to improve LLM. Yet, most research in reasoning has focused on mathematical tasks, leaving domains like medicine underexplored. The medical domain, though distinct from mathematics, also demands robust reasoning to provide reliable answers, given the high standards of healthcare. However, verifying medical reasoning is challenging, unlike those in mathematics. To address this, we propose verifiable medical problems with a medical verifier to check the correctness of model outputs. This verifiable nature enables advancements in medical reasoning through a two-stage approach: (1) using the verifier to guide the search for a complex reasoning trajectory for fine-tuning LLMs, (2) applying reinforcement learning (RL) with verifier-based rewards to enhance complex reasoning further. Finally, we introduce HuatuoGPT-o1, a medical LLM capable of complex reasoning, which outperforms general and medical-specific baselines using only 40K verifiable problems. Experiments show complex reasoning improves medical problem-solving and benefits more from RL. We hope our approach inspires advancements in reasoning across medical and other specialized domains.
Alignment at Pre-training! Towards Native Alignment for Arabic LLMs
Dec 04, 2024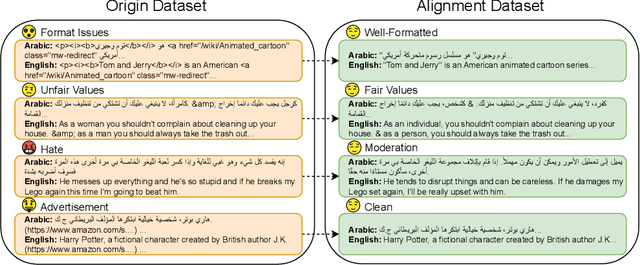
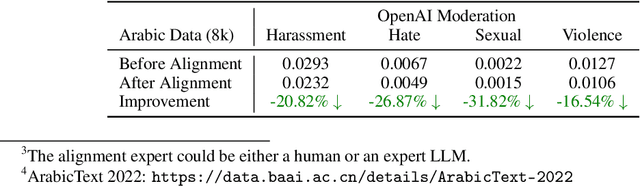
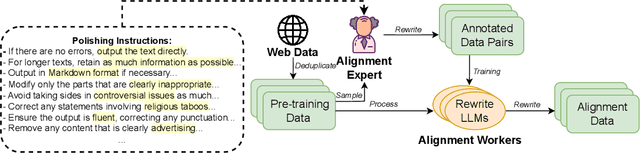
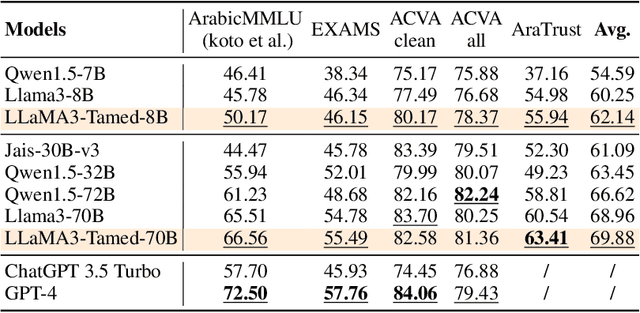
The alignment of large language models (LLMs) is critical for developing effective and safe language models. Traditional approaches focus on aligning models during the instruction tuning or reinforcement learning stages, referred to in this paper as `post alignment'. We argue that alignment during the pre-training phase, which we term `native alignment', warrants investigation. Native alignment aims to prevent unaligned content from the beginning, rather than relying on post-hoc processing. This approach leverages extensively aligned pre-training data to enhance the effectiveness and usability of pre-trained models. Our study specifically explores the application of native alignment in the context of Arabic LLMs. We conduct comprehensive experiments and ablation studies to evaluate the impact of native alignment on model performance and alignment stability. Additionally, we release open-source Arabic LLMs that demonstrate state-of-the-art performance on various benchmarks, providing significant benefits to the Arabic LLM community.
HuatuoGPT-Vision, Towards Injecting Medical Visual Knowledge into Multimodal LLMs at Scale
Jun 27, 2024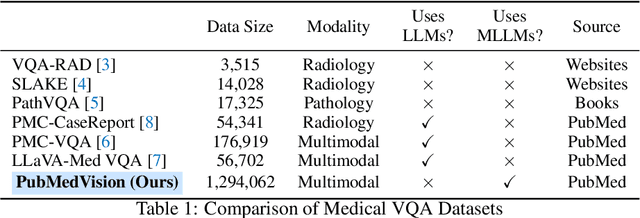
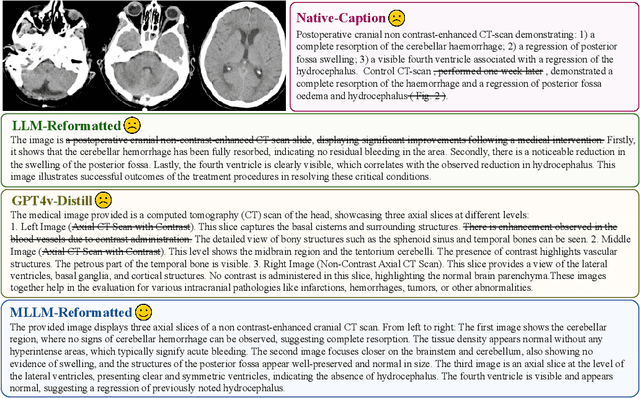
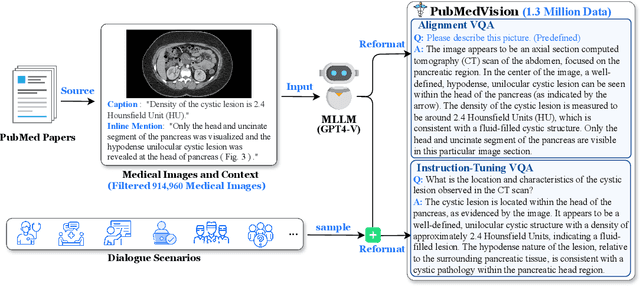
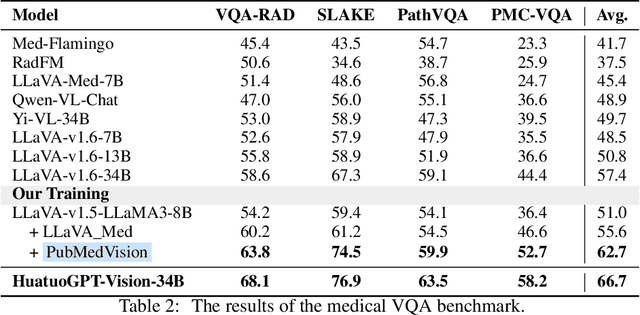
The rapid development of multimodal large language models (MLLMs), such as GPT-4V, has led to significant advancements. However, these models still face challenges in medical multimodal capabilities due to limitations in the quantity and quality of medical vision-text data, stemming from data privacy concerns and high annotation costs. While pioneering approaches utilize PubMed's large-scale, de-identified medical image-text pairs to address these limitations, they still fall short due to inherent data noise. To tackle this, we refined medical image-text pairs from PubMed and employed MLLMs (GPT-4V) in an 'unblinded' capacity to denoise and reformat the data, resulting in the creation of the PubMedVision dataset with 1.3 million medical VQA samples. Our validation demonstrates that: (1) PubMedVision can significantly enhance the medical multimodal capabilities of current MLLMs, showing significant improvement in benchmarks including the MMMU Health & Medicine track; (2) manual checks by medical experts and empirical results validate the superior data quality of our dataset compared to other data construction methods. Using PubMedVision, we train a 34B medical MLLM HuatuoGPT-Vision, which shows superior performance in medical multimodal scenarios among open-source MLLMs.