 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Analysis for Visual Object Hallucination in Large Vision-Language Models
May 04, 2025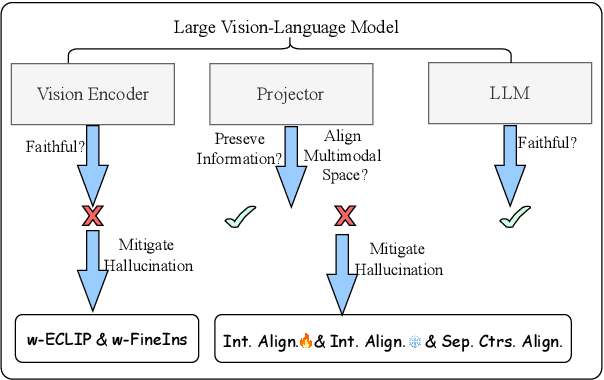
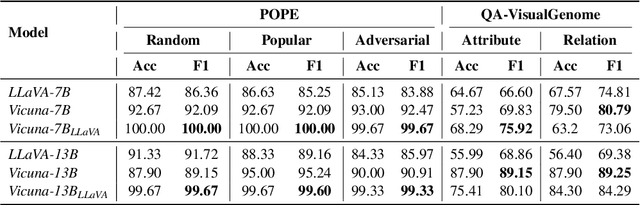

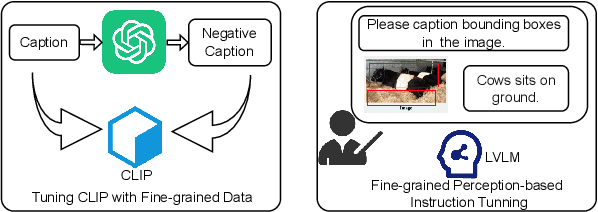
Large Vision-Language Models (LVLMs) demonstrate remarkable capabilities in multimodal tasks, but visual object hallucination remains a persistent issue. It refers to scenarios where models generate inaccurate visual object-related information based on the query input, potentially leading to misinformation and concerns about safety and reliability. Previous works focus on the evaluation and mitigation of visual hallucinations, but the underlying causes have not been comprehensively investigated. In this paper, we analyze each component of LLaVA-like LVLMs -- the large language model, the vision backbone, and the projector -- to identify potential sources of error and their impact. Based on our observations, we propose methods to mitigate hallucination for each problematic component. Additionally, we developed two hallucination benchmarks: QA-VisualGenome, which emphasizes attribute and relation hallucinations, and QA-FB15k, which focuses on cognition-based hallucinations.
HuatuoGPT-Vision, Towards Injecting Medical Visual Knowledge into Multimodal LLMs at Scale
Jun 27, 2024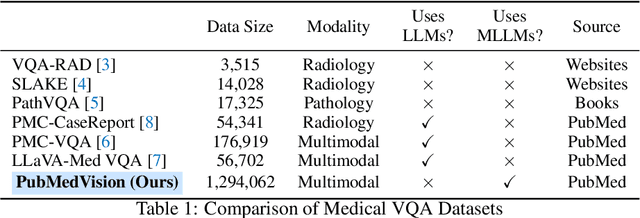
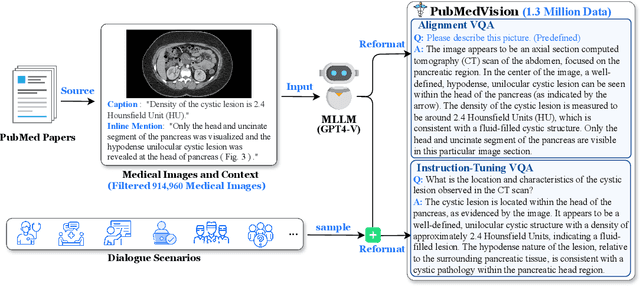
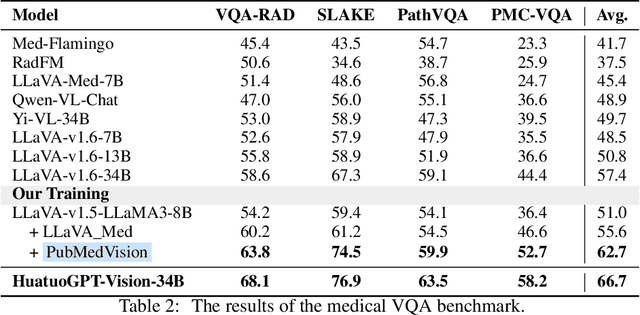
The rapid development of multimodal large language models (MLLMs), such as GPT-4V, has led to significant advancements. However, these models still face challenges in medical multimodal capabilities due to limitations in the quantity and quality of medical vision-text data, stemming from data privacy concerns and high annotation costs. While pioneering approaches utilize PubMed's large-scale, de-identified medical image-text pairs to address these limitations, they still fall short due to inherent data noise. To tackle this, we refined medical image-text pairs from PubMed and employed MLLMs (GPT-4V) in an 'unblinded' capacity to denoise and reformat the data, resulting in the creation of the PubMedVision dataset with 1.3 million medical VQA samples. Our validation demonstrates that: (1) PubMedVision can significantly enhance the medical multimodal capabilities of current MLLMs, showing significant improvement in benchmarks including the MMMU Health & Medicine track; (2) manual checks by medical experts and empirical results validate the superior data quality of our dataset compared to other data construction methods. Using PubMedVision, we train a 34B medical MLLM HuatuoGPT-Vision, which shows superior performance in medical multimodal scenarios among open-source MLLMs.
MileBench: Benchmarking MLLMs in Long Context
Apr 29, 2024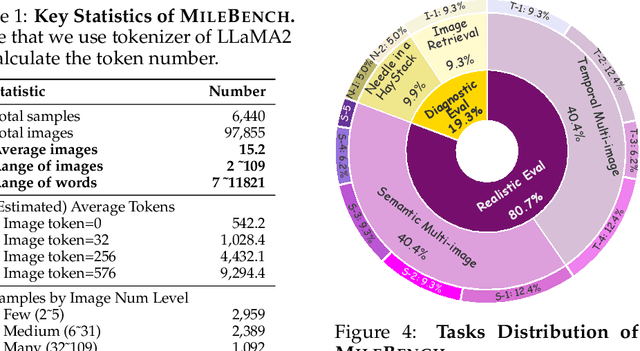
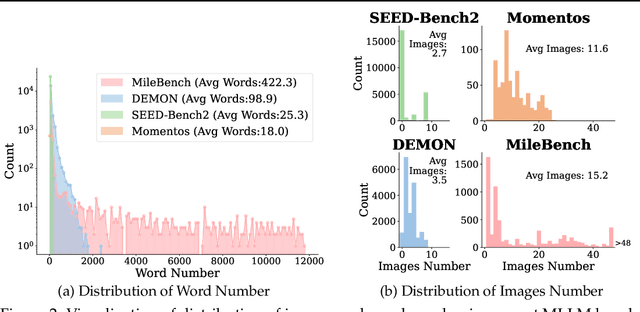
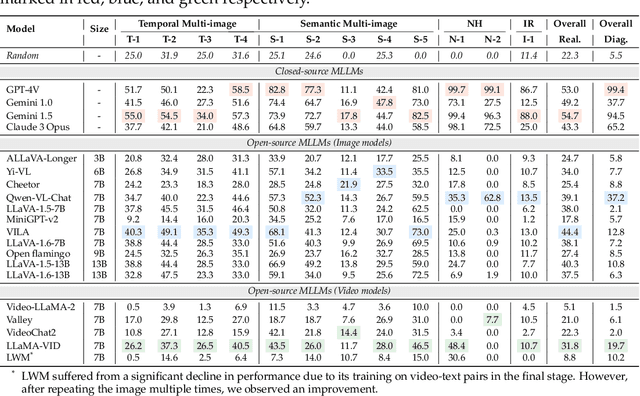
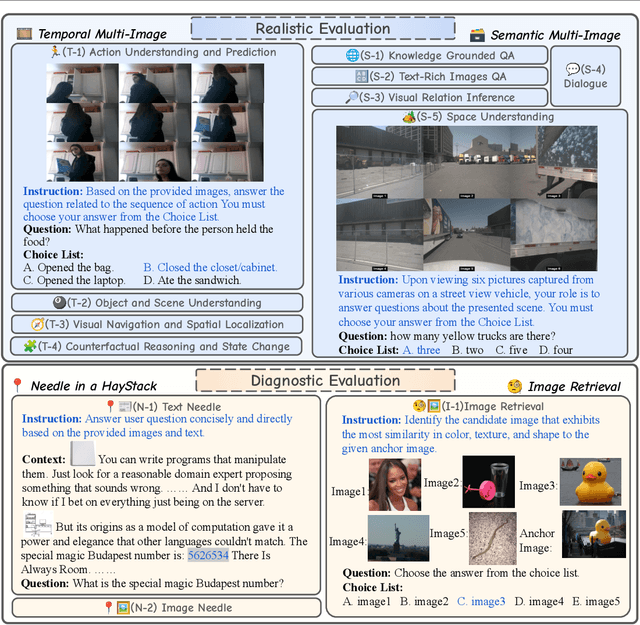
Despite the advancements and impressive performance of Multimodal Large Language Models (MLLMs) on benchmarks, their effectiveness in real-world, long-context, and multi-image tasks is unclear due to the benchmarks' limited scope. Existing benchmarks often focus on single-image and short-text samples, and when assessing multi-image tasks, they either limit the image count or focus on specific task (e.g time-series captioning), potentially obscuring the performance challenges of MLLMs. To address these limitations, we introduce MileBench, a pioneering benchmark designed to test the MultImodal Long-contExt capabilities of MLLMs. This benchmark comprises not only multimodal long contexts, but also multiple tasks requiring both comprehension and generation. We establish two distinct evaluation sets, diagnostic and realistic, to systematically assess MLLMs' long-context adaptation capacity and their ability to complete tasks in long-context scenarios. Our experimental results, obtained from testing 20 models, revealed that while the closed-source GPT-4(Vision) and Gemini 1.5 outperform others, most open-source MLLMs struggle in long-context situations. Interestingly, the performance gap tends to widen with an increase in the number of images. We strongly encourage an intensification of research efforts towards enhancing MLLMs' long-context capabilities, especially in scenarios involving multiple images.
Humans or LLMs as the Judge? A Study on Judgement Biases
Feb 20, 2024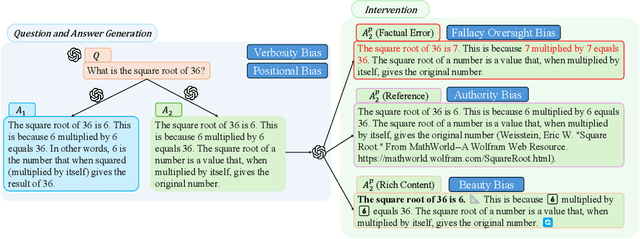
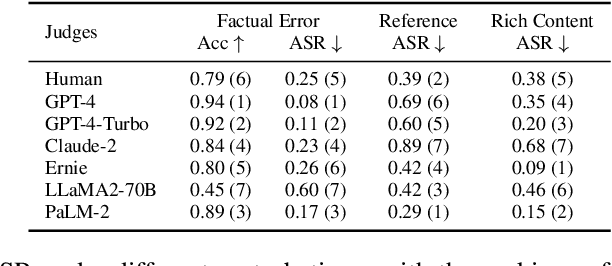
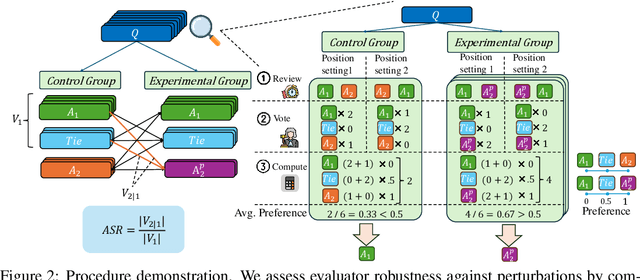
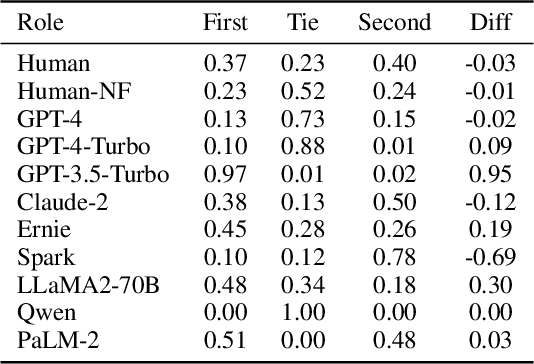
Adopting human and large language models (LLM) as judges (\textit{a.k.a} human- and LLM-as-a-judge) for evaluating the performance of existing LLMs has recently gained attention. Nonetheless, this approach concurrently introduces potential biases from human and LLM judges, questioning the reliability of the evaluation results. In this paper, we propose a novel framework for investigating 5 types of biases for LLM and human judges. We curate a dataset with 142 samples referring to the revised Bloom's Taxonomy and conduct thousands of human and LLM evaluations. Results show that human and LLM judges are vulnerable to perturbations to various degrees, and that even the most cutting-edge judges possess considerable biases. We further exploit their weakness and conduct attacks on LLM judges. We hope that our work can notify the community of the vulnerability of human- and LLM-as-a-judge against perturbations, as well as the urgency of developing robust evaluation systems.
ALLaVA: Harnessing GPT4V-synthesized Data for A Lite Vision-Language Model
Feb 18, 2024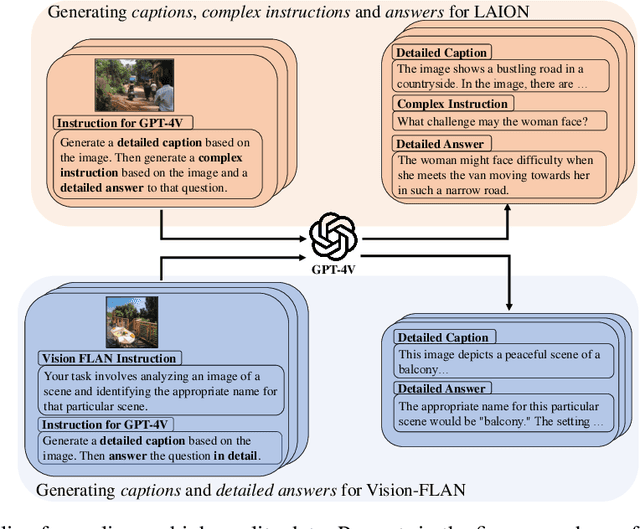
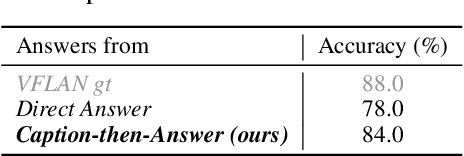

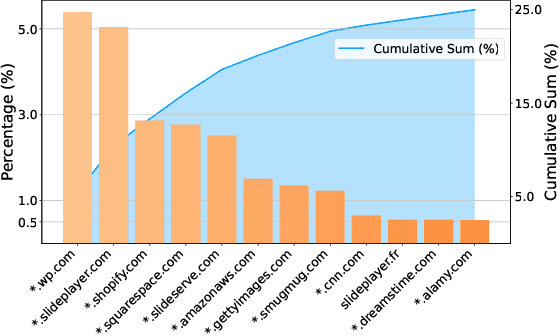
Recent advancements in Large Vision-Language Models (LVLMs) have enabled processing of multimodal inputs in language models but require significant computational resources for deployment, especially in edge devices. This study aims to bridge the performance gap between traditional-scale LVLMs and resource-friendly lite versions by adopting high-quality training data. To do this, a synthetic dataset is created by leveraging GPT-4V's ability to generate detailed captions, complex reasoning instructions and detailed answers from images. The resulted model trained with our data, ALLaVA, achieves competitive performance on 12 benchmarks up to 3B LVLMs. This work highlights the feasibility of adopting high-quality data in crafting more efficient LVLMs. Our online demo is available at \url{https://allava.freedomai.cn}.
CMB: A Comprehensive Medical Benchmark in Chinese
Aug 17, 2023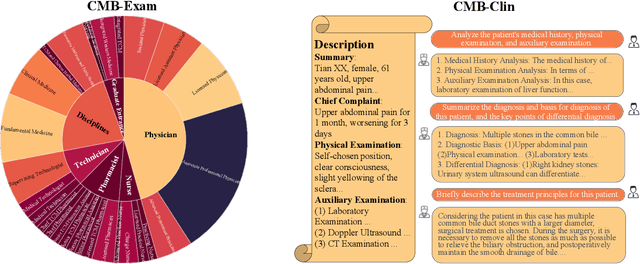
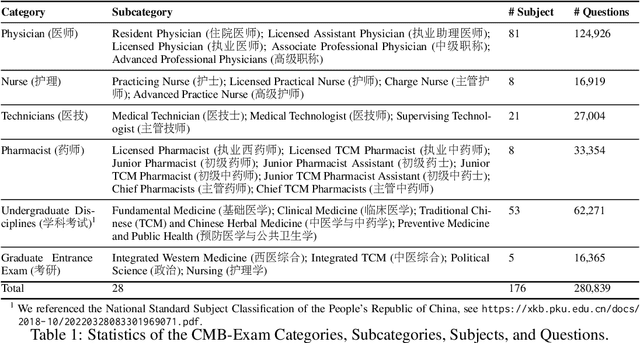

Large Language Models (LLMs) provide a possibility to make a great breakthrough in medicine. The establishment of a standardized medical benchmark becomes a fundamental cornerstone to measure progression. However, medical environments in different regions have their local characteristics, e.g., the ubiquity and significance of traditional Chinese medicine within China. Therefore, merely translating English-based medical evaluation may result in \textit{contextual incongruities} to a local region. To solve the issue, we propose a localized medical benchmark called CMB, a Comprehensive Medical Benchmark in Chinese, designed and rooted entirely within the native Chinese linguistic and cultural framework. While traditional Chinese medicine is integral to this evaluation, it does not constitute its entirety. Using this benchmark, we have evaluated several prominent large-scale LLMs, including ChatGPT, GPT-4, dedicated Chinese LLMs, and LLMs specialized in the medical domain. It is worth noting that our benchmark is not devised as a leaderboard competition but as an instrument for self-assessment of model advancements. We hope this benchmark could facilitate the widespread adoption and enhancement of medical LLMs within China. Check details in \url{https://cmedbenchmark.llmzoo.com/}.
On the Difference of BERT-style and CLIP-style Text Encoders
Jun 06, 2023



Masked language modeling (MLM) has been one of the most popular pretraining recipes in natural language processing, e.g., BERT, one of the representative models. Recently, contrastive language-image pretraining (CLIP) has also attracted attention, especially its vision models that achieve excellent performance on a broad range of vision tasks. However, few studies are dedicated to studying the text encoders learned by CLIP. In this paper, we analyze the difference between BERT-style and CLIP-style text encoders from three experiments: (i) general text understanding, (ii) vision-centric text understanding, and (iii) text-to-image generation. Experimental analyses show that although CLIP-style text encoders underperform BERT-style ones for general text understanding tasks, they are equipped with a unique ability, i.e., synesthesia, for the cross-modal association, which is more similar to the senses of humans.