 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTake the essence and discard the dross: A Rethinking on Data Selection for Fine-Tuning Large Language Models
Jun 20, 2024Data selection for fine-tuning Large Language Models (LLMs) aims to select a high-quality subset from a given candidate dataset to train a Pending Fine-tune Model (PFM) into a Selective-Enhanced Model (SEM). It can improve the model performance and accelerate the training process. Although a few surveys have investigated related works of data selection, there is a lack of comprehensive comparison between existing methods due to their various experimental settings. To address this issue, we first propose a three-stage scheme for data selection and comprehensively review existing works according to this scheme. Then, we design a unified comparing method with ratio-based efficiency indicators and ranking-based feasibility indicators to overcome the difficulty of comparing various models with diverse experimental settings. After an in-depth comparative analysis, we find that the more targeted method with data-specific and model-specific quality labels has higher efficiency, but the introduction of additional noise information should be avoided when designing selection algorithms. Finally, we summarize the trends in data selection and highlight the short-term and long-term challenges to guide future research.
Humans or LLMs as the Judge? A Study on Judgement Biases
Feb 20, 2024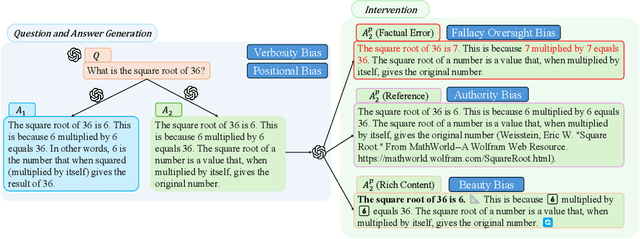
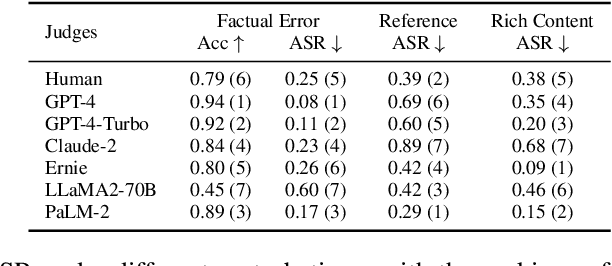
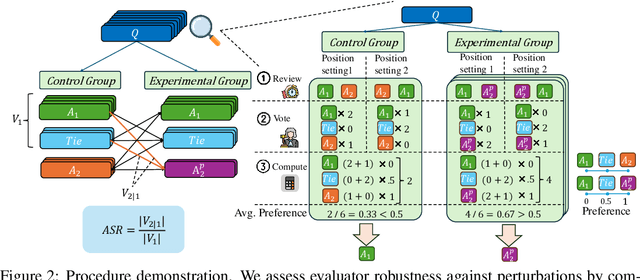
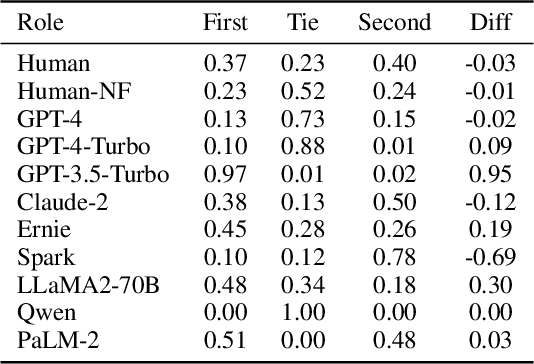
Adopting human and large language models (LLM) as judges (\textit{a.k.a} human- and LLM-as-a-judge) for evaluating the performance of existing LLMs has recently gained attention. Nonetheless, this approach concurrently introduces potential biases from human and LLM judges, questioning the reliability of the evaluation results. In this paper, we propose a novel framework for investigating 5 types of biases for LLM and human judges. We curate a dataset with 142 samples referring to the revised Bloom's Taxonomy and conduct thousands of human and LLM evaluations. Results show that human and LLM judges are vulnerable to perturbations to various degrees, and that even the most cutting-edge judges possess considerable biases. We further exploit their weakness and conduct attacks on LLM judges. We hope that our work can notify the community of the vulnerability of human- and LLM-as-a-judge against perturbations, as well as the urgency of developing robust evaluation systems.
AceGPT, Localizing Large Language Models in Arabic
Sep 22, 2023



This paper explores the imperative need and methodology for developing a localized Large Language Model (LLM) tailored for Arabic, a language with unique cultural characteristics that are not adequately addressed by current mainstream models like ChatGPT. Key concerns additionally arise when considering cultural sensitivity and local values. To this end, the paper outlines a packaged solution, including further pre-training with Arabic texts, supervised fine-tuning (SFT) using native Arabic instructions and GPT-4 responses in Arabic, and reinforcement learning with AI feedback (RLAIF) using a reward model that is sensitive to local culture and values. The objective is to train culturally aware and value-aligned Arabic LLMs that can serve the diverse application-specific needs of Arabic-speaking communities. Extensive evaluations demonstrated that the resulting LLM called `AceGPT' is the SOTA open Arabic LLM in various benchmarks, including instruction-following benchmark (i.e., Arabic Vicuna-80 and Arabic AlpacaEval), knowledge benchmark (i.e., Arabic MMLU and EXAMs), as well as the newly-proposed Arabic cultural \& value alignment benchmark. Notably, AceGPT outperforms ChatGPT in the popular Vicuna-80 benchmark when evaluated with GPT-4, despite the benchmark's limited scale. % Natural Language Understanding (NLU) benchmark (i.e., ALUE) Codes, data, and models are in https://github.com/FreedomIntelligence/AceGPT.