 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAdaRAG: Task Adaptive Retrieval-Augmented Generation via On-the-Fly Knowledge Graph Construction
Nov 16, 2025Retrieval-Augmented Generation (RAG) improves large language models by retrieving external knowledge, often truncated into smaller chunks due to the input context window, which leads to information loss, resulting in response hallucinations and broken reasoning chains. Moreover, traditional RAG retrieves unstructured knowledge, introducing irrelevant details that hinder accurate reasoning. To address these issues, we propose TAdaRAG, a novel RAG framework for on-the-fly task-adaptive knowledge graph construction from external sources. Specifically, we design an intent-driven routing mechanism to a domain-specific extraction template, followed by supervised fine-tuning and a reinforcement learning-based implicit extraction mechanism, ensuring concise, coherent, and non-redundant knowledge integration. Evaluations on six public benchmarks and a real-world business benchmark (NowNewsQA) across three backbone models demonstrate that TAdaRAG outperforms existing methods across diverse domains and long-text tasks, highlighting its strong generalization and practical effectiveness.
Exploring Non-Local Spatial-Angular Correlations with a Hybrid Mamba-Transformer Framework for Light Field Super-Resolution
Sep 05, 2025Recently, Mamba-based methods, with its advantage in long-range information modeling and linear complexity, have shown great potential in optimizing both computational cost and performance of light field image super-resolution (LFSR). However, current multi-directional scanning strategies lead to inefficient and redundant feature extraction when applied to complex LF data. To overcome this challenge, we propose a Subspace Simple Scanning (Sub-SS) strategy, based on which we design the Subspace Simple Mamba Block (SSMB) to achieve more efficient and precise feature extraction. Furthermore, we propose a dual-stage modeling strategy to address the limitation of state space in preserving spatial-angular and disparity information, thereby enabling a more comprehensive exploration of non-local spatial-angular correlations. Specifically, in stage I, we introduce the Spatial-Angular Residual Subspace Mamba Block (SA-RSMB) for shallow spatial-angular feature extraction; in stage II, we use a dual-branch parallel structure combining the Epipolar Plane Mamba Block (EPMB) and Epipolar Plane Transformer Block (EPTB) for deep epipolar feature refinement. Building upon meticulously designed modules and strategies, we introduce a hybrid Mamba-Transformer framework, termed LFMT. LFMT integrates the strengths of Mamba and Transformer models for LFSR, enabling comprehensive information exploration across spatial, angular, and epipolar-plane domains. Experimental results demonstrate that LFMT significantly outperforms current state-of-the-art methods in LFSR, achieving substantial improvements in performance while maintaining low computational complexity on both real-word and synthetic LF datasets.
Second Language (Arabic) Acquisition of LLMs via Progressive Vocabulary Expansion
Dec 16, 2024



This paper addresses the critical need for democratizing large language models (LLM) in the Arab world, a region that has seen slower progress in developing models comparable to state-of-the-art offerings like GPT-4 or ChatGPT 3.5, due to a predominant focus on mainstream languages (e.g., English and Chinese). One practical objective for an Arabic LLM is to utilize an Arabic-specific vocabulary for the tokenizer that could speed up decoding. However, using a different vocabulary often leads to a degradation of learned knowledge since many words are initially out-of-vocabulary (OOV) when training starts. Inspired by the vocabulary learning during Second Language (Arabic) Acquisition for humans, the released AraLLaMA employs progressive vocabulary expansion, which is implemented by a modified BPE algorithm that progressively extends the Arabic subwords in its dynamic vocabulary during training, thereby balancing the OOV ratio at every stage. The ablation study demonstrated the effectiveness of Progressive Vocabulary Expansion. Moreover, AraLLaMA achieves decent performance comparable to the best Arabic LLMs across a variety of Arabic benchmarks. Models, training data, benchmarks, and codes will be all open-sourced.
Alignment at Pre-training! Towards Native Alignment for Arabic LLMs
Dec 04, 2024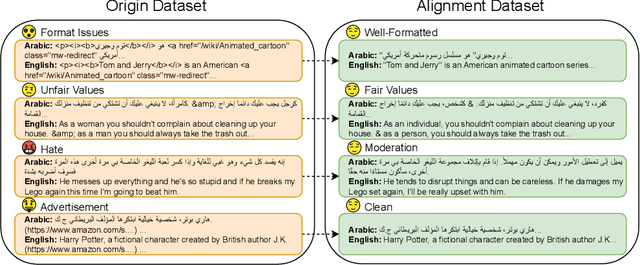
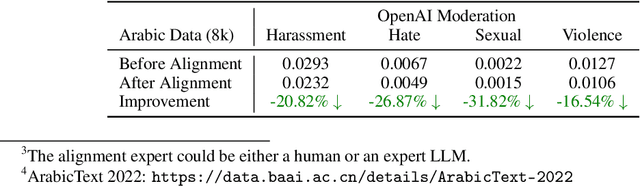
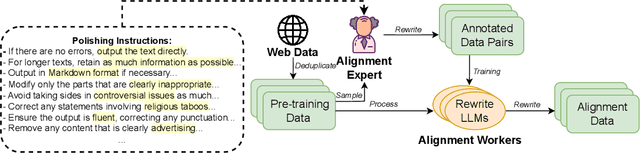
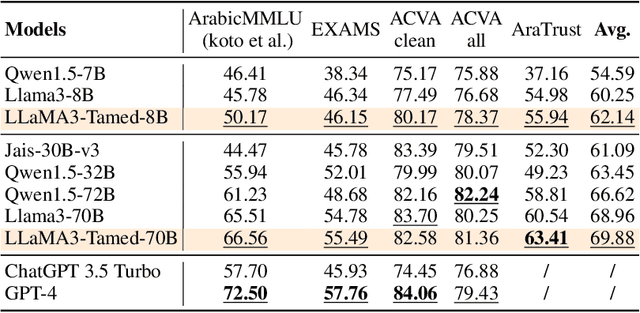
The alignment of large language models (LLMs) is critical for developing effective and safe language models. Traditional approaches focus on aligning models during the instruction tuning or reinforcement learning stages, referred to in this paper as `post alignment'. We argue that alignment during the pre-training phase, which we term `native alignment', warrants investigation. Native alignment aims to prevent unaligned content from the beginning, rather than relying on post-hoc processing. This approach leverages extensively aligned pre-training data to enhance the effectiveness and usability of pre-trained models. Our study specifically explores the application of native alignment in the context of Arabic LLMs. We conduct comprehensive experiments and ablation studies to evaluate the impact of native alignment on model performance and alignment stability. Additionally, we release open-source Arabic LLMs that demonstrate state-of-the-art performance on various benchmarks, providing significant benefits to the Arabic LLM community.
S$^3$Attention: Improving Long Sequence Attention with Smoothed Skeleton Sketching
Aug 16, 2024Attention based models have achieved many remarkable breakthroughs in numerous applications. However, the quadratic complexity of Attention makes the vanilla Attention based models hard to apply to long sequence tasks. Various improved Attention structures are proposed to reduce the computation cost by inducing low rankness and approximating the whole sequence by sub-sequences. The most challenging part of those approaches is maintaining the proper balance between information preservation and computation reduction: the longer sub-sequences used, the better information is preserved, but at the price of introducing more noise and computational costs. In this paper, we propose a smoothed skeleton sketching based Attention structure, coined S$^3$Attention, which significantly improves upon the previous attempts to negotiate this trade-off. S$^3$Attention has two mechanisms to effectively minimize the impact of noise while keeping the linear complexity to the sequence length: a smoothing block to mix information over long sequences and a matrix sketching method that simultaneously selects columns and rows from the input matrix. We verify the effectiveness of S$^3$Attention both theoretically and empirically. Extensive studies over Long Range Arena (LRA) datasets and six time-series forecasting show that S$^3$Attention significantly outperforms both vanilla Attention and other state-of-the-art variants of Attention structures.
AceGPT, Localizing Large Language Models in Arabic
Sep 22, 2023



This paper explores the imperative need and methodology for developing a localized Large Language Model (LLM) tailored for Arabic, a language with unique cultural characteristics that are not adequately addressed by current mainstream models like ChatGPT. Key concerns additionally arise when considering cultural sensitivity and local values. To this end, the paper outlines a packaged solution, including further pre-training with Arabic texts, supervised fine-tuning (SFT) using native Arabic instructions and GPT-4 responses in Arabic, and reinforcement learning with AI feedback (RLAIF) using a reward model that is sensitive to local culture and values. The objective is to train culturally aware and value-aligned Arabic LLMs that can serve the diverse application-specific needs of Arabic-speaking communities. Extensive evaluations demonstrated that the resulting LLM called `AceGPT' is the SOTA open Arabic LLM in various benchmarks, including instruction-following benchmark (i.e., Arabic Vicuna-80 and Arabic AlpacaEval), knowledge benchmark (i.e., Arabic MMLU and EXAMs), as well as the newly-proposed Arabic cultural \& value alignment benchmark. Notably, AceGPT outperforms ChatGPT in the popular Vicuna-80 benchmark when evaluated with GPT-4, despite the benchmark's limited scale. % Natural Language Understanding (NLU) benchmark (i.e., ALUE) Codes, data, and models are in https://github.com/FreedomIntelligence/AceGPT.
Towards a Smaller Student: Capacity Dynamic Distillation for Efficient Image Retrieval
Mar 16, 2023



Previous Knowledge Distillation based efficient image retrieval methods employs a lightweight network as the student model for fast inference. However, the lightweight student model lacks adequate representation capacity for effective knowledge imitation during the most critical early training period, causing final performance degeneration. To tackle this issue, we propose a Capacity Dynamic Distillation framework, which constructs a student model with editable representation capacity. Specifically, the employed student model is initially a heavy model to fruitfully learn distilled knowledge in the early training epochs, and the student model is gradually compressed during the training. To dynamically adjust the model capacity, our dynamic framework inserts a learnable convolutional layer within each residual block in the student model as the channel importance indicator. The indicator is optimized simultaneously by the image retrieval loss and the compression loss, and a retrieval-guided gradient resetting mechanism is proposed to release the gradient conflict. Extensive experiments show that our method has superior inference speed and accuracy, e.g., on the VeRi-776 dataset, given the ResNet101 as a teacher, our method saves 67.13% model parameters and 65.67% FLOPs (around 24.13% and 21.94% higher than state-of-the-arts) without sacrificing accuracy (around 2.11% mAP higher than state-of-the-arts).
FV-MgNet: Fully Connected V-cycle MgNet for Interpretable Time Series Forecasting
Feb 02, 2023By investigating iterative methods for a constrained linear model, we propose a new class of fully connected V-cycle MgNet for long-term time series forecasting, which is one of the most difficult tasks in forecasting. MgNet is a CNN model that was proposed for image classification based on the multigrid (MG) methods for solving discretized partial differential equations (PDEs). We replace the convolutional operations with fully connected operations in the existing MgNet and then apply them to forecasting problems. Motivated by the V-cycle structure in MG, we further propose the FV-MgNet, a V-cycle version of the fully connected MgNet, to extract features hierarchically. By evaluating the performance of FV-MgNet on popular data sets and comparing it with state-of-the-art models, we show that the FV-MgNet achieves better results with less memory usage and faster inference speed. In addition, we develop ablation experiments to demonstrate that the structure of FV-MgNet is the best choice among the many variants.
An Enhanced V-cycle MgNet Model for Operator Learning in Numerical Partial Differential Equations
Feb 02, 2023This study used a multigrid-based convolutional neural network architecture known as MgNet in operator learning to solve numerical partial differential equations (PDEs). Given the property of smoothing iterations in multigrid methods where low-frequency errors decay slowly, we introduced a low-frequency correction structure for residuals to enhance the standard V-cycle MgNet. The enhanced MgNet model can capture the low-frequency features of solutions considerably better than the standard V-cycle MgNet. The numerical results obtained using some standard operator learning tasks are better than those obtained using many state-of-the-art methods, demonstrating the efficiency of our model.Moreover, numerically, our new model is more robust in case of low- and high-resolution data during training and testing, respectively.
TreeDRNet:A Robust Deep Model for Long Term Time Series Forecasting
Jun 24, 2022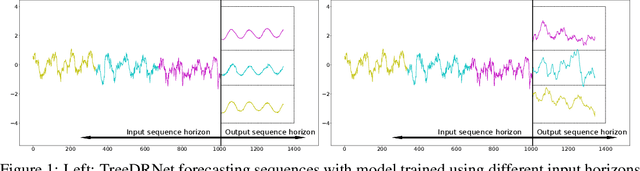
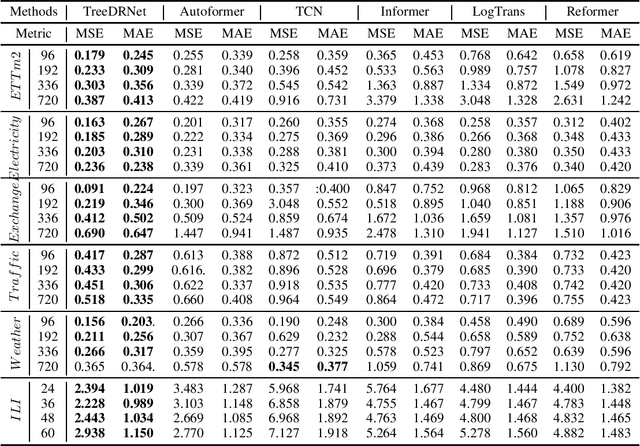
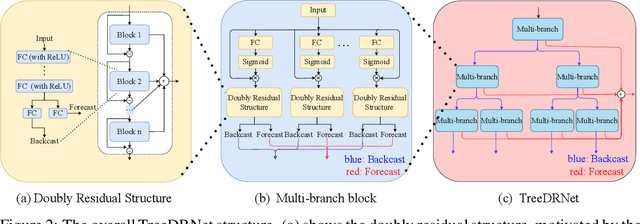

Various deep learning models, especially some latest Transformer-based approaches, have greatly improved the state-of-art performance for long-term time series forecasting.However, those transformer-based models suffer a severe deterioration performance with prolonged input length, which prohibits them from using extended historical info.Moreover, these methods tend to handle complex examples in long-term forecasting with increased model complexity, which often leads to a significant increase in computation and less robustness in performance(e.g., overfitting). We propose a novel neural network architecture, called TreeDRNet, for more effective long-term forecasting. Inspired by robust regression, we introduce doubly residual link structure to make prediction more robust.Built upon Kolmogorov-Arnold representation theorem, we explicitly introduce feature selection, model ensemble, and a tree structure to further utilize the extended input sequence, which improves the robustness and representation power of TreeDRNet. Unlike previous deep models for sequential forecasting work, TreeDRNet is built entirely on multilayer perceptron and thus enjoys high computational efficiency. Our extensive empirical studies show that TreeDRNet is significantly more effective than state-of-the-art methods, reducing prediction errors by 20% to 40% for multivariate time series. In particular, TreeDRNet is over 10 times more efficient than transformer-based methods. The code will be released soon.