 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Non-Local Spatial-Angular Correlations with a Hybrid Mamba-Transformer Framework for Light Field Super-Resolution
Sep 05, 2025Recently, Mamba-based methods, with its advantage in long-range information modeling and linear complexity, have shown great potential in optimizing both computational cost and performance of light field image super-resolution (LFSR). However, current multi-directional scanning strategies lead to inefficient and redundant feature extraction when applied to complex LF data. To overcome this challenge, we propose a Subspace Simple Scanning (Sub-SS) strategy, based on which we design the Subspace Simple Mamba Block (SSMB) to achieve more efficient and precise feature extraction. Furthermore, we propose a dual-stage modeling strategy to address the limitation of state space in preserving spatial-angular and disparity information, thereby enabling a more comprehensive exploration of non-local spatial-angular correlations. Specifically, in stage I, we introduce the Spatial-Angular Residual Subspace Mamba Block (SA-RSMB) for shallow spatial-angular feature extraction; in stage II, we use a dual-branch parallel structure combining the Epipolar Plane Mamba Block (EPMB) and Epipolar Plane Transformer Block (EPTB) for deep epipolar feature refinement. Building upon meticulously designed modules and strategies, we introduce a hybrid Mamba-Transformer framework, termed LFMT. LFMT integrates the strengths of Mamba and Transformer models for LFSR, enabling comprehensive information exploration across spatial, angular, and epipolar-plane domains. Experimental results demonstrate that LFMT significantly outperforms current state-of-the-art methods in LFSR, achieving substantial improvements in performance while maintaining low computational complexity on both real-word and synthetic LF datasets.
FD-LSCIC: Frequency Decomposition-based Learned Screen Content Image Compression
Feb 21, 2025



The learned image compression (LIC) methods have already surpassed traditional techniques in compressing natural scene (NS) images. However, directly applying these methods to screen content (SC) images, which possess distinct characteristics such as sharp edges, repetitive patterns, embedded text and graphics, yields suboptimal results. This paper addresses three key challenges in SC image compression: learning compact latent features, adapting quantization step sizes, and the lack of large SC datasets. To overcome these challenges, we propose a novel compression method that employs a multi-frequency two-stage octave residual block (MToRB) for feature extraction, a cascaded triple-scale feature fusion residual block (CTSFRB) for multi-scale feature integration and a multi-frequency context interaction module (MFCIM) to reduce inter-frequency correlations. Additionally, we introduce an adaptive quantization module that learns scaled uniform noise for each frequency component, enabling flexible control over quantization granularity. Furthermore, we construct a large SC image compression dataset (SDU-SCICD10K), which includes over 10,000 images spanning basic SC images, computer-rendered images, and mixed NS and SC images from both PC and mobile platforms. Experimental results demonstrate that our approach significantly improves SC image compression performance, outperforming traditional standards and state-of-the-art learning-based methods in terms of peak signal-to-noise ratio (PSNR) and multi-scale structural similarity (MS-SSIM).
PrefPaint: Aligning Image Inpainting Diffusion Model with Human Preference
Oct 29, 2024
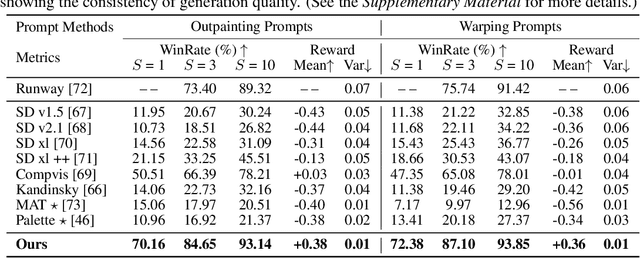
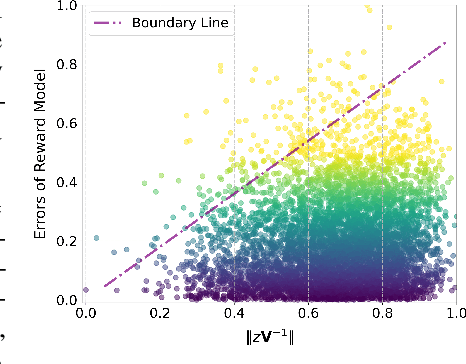
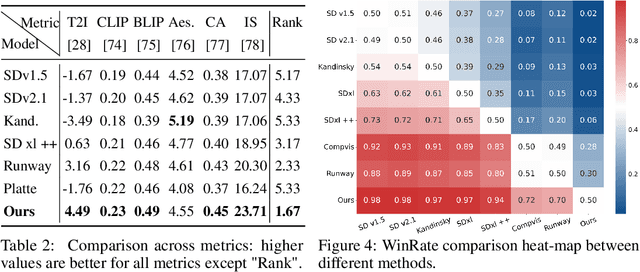
In this paper, we make the first attempt to align diffusion models for image inpainting with human aesthetic standards via a reinforcement learning framework, significantly improving the quality and visual appeal of inpainted images. Specifically, instead of directly measuring the divergence with paired images, we train a reward model with the dataset we construct, consisting of nearly 51,000 images annotated with human preferences. Then, we adopt a reinforcement learning process to fine-tune the distribution of a pre-trained diffusion model for image inpainting in the direction of higher reward. Moreover, we theoretically deduce the upper bound on the error of the reward model, which illustrates the potential confidence of reward estimation throughout the reinforcement alignment process, thereby facilitating accurate regularization. Extensive experiments on inpainting comparison and downstream tasks, such as image extension and 3D reconstruction, demonstrate the effectiveness of our approach, showing significant improvements in the alignment of inpainted images with human preference compared with state-of-the-art methods. This research not only advances the field of image inpainting but also provides a framework for incorporating human preference into the iterative refinement of generative models based on modeling reward accuracy, with broad implications for the design of visually driven AI applications. Our code and dataset are publicly available at https://prefpaint.github.io.
Learning Efficient and Effective Trajectories for Differential Equation-based Image Restoration
Oct 07, 2024



The differential equation-based image restoration approach aims to establish learnable trajectories connecting high-quality images to a tractable distribution, e.g., low-quality images or a Gaussian distribution. In this paper, we reformulate the trajectory optimization of this kind of method, focusing on enhancing both reconstruction quality and efficiency. Initially, we navigate effective restoration paths through a reinforcement learning process, gradually steering potential trajectories toward the most precise options. Additionally, to mitigate the considerable computational burden associated with iterative sampling, we propose cost-aware trajectory distillation to streamline complex paths into several manageable steps with adaptable sizes. Moreover, we fine-tune a foundational diffusion model (FLUX) with 12B parameters by using our algorithms, producing a unified framework for handling 7 kinds of image restoration tasks. Extensive experiments showcase the significant superiority of the proposed method, achieving a maximum PSNR improvement of 2.1 dB over state-of-the-art methods, while also greatly enhancing visual perceptual quality. Project page: \url{https://zhu-zhiyu.github.io/FLUX-IR/}.
Image Re-Identification: Where Self-supervision Meets Vision-Language Learning
Jul 30, 2024



Recently, large-scale vision-language pre-trained models like CLIP have shown impressive performance in image re-identification (ReID). In this work, we explore whether self-supervision can aid in the use of CLIP for image ReID tasks. Specifically, we propose SVLL-ReID, the first attempt to integrate self-supervision and pre-trained CLIP via two training stages to facilitate the image ReID. We observe that: 1) incorporating language self-supervision in the first training stage can make the learnable text prompts more distinguishable, and 2) incorporating vision self-supervision in the second training stage can make the image features learned by the image encoder more discriminative. These observations imply that: 1) the text prompt learning in the first stage can benefit from the language self-supervision, and 2) the image feature learning in the second stage can benefit from the vision self-supervision. These benefits jointly facilitate the performance gain of the proposed SVLL-ReID. By conducting experiments on six image ReID benchmark datasets without any concrete text labels, we find that the proposed SVLL-ReID achieves the overall best performances compared with state-of-the-arts. Codes will be publicly available at https://github.com/BinWangGzhu/SVLL-ReID.
Self-supervised 3D Point Cloud Completion via Multi-view Adversarial Learning
Jul 13, 2024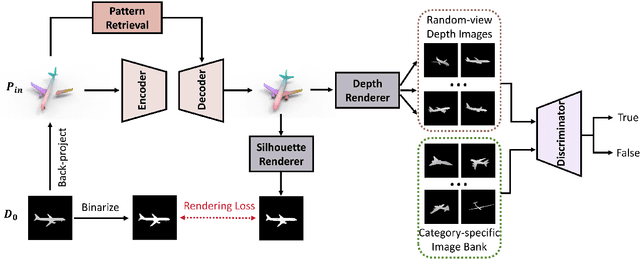
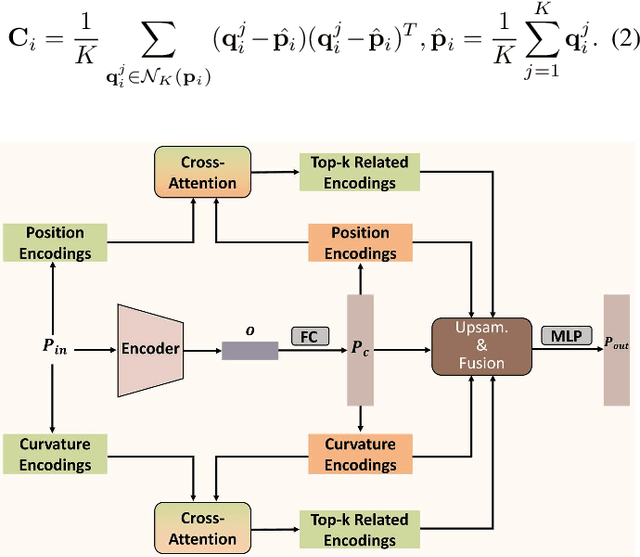

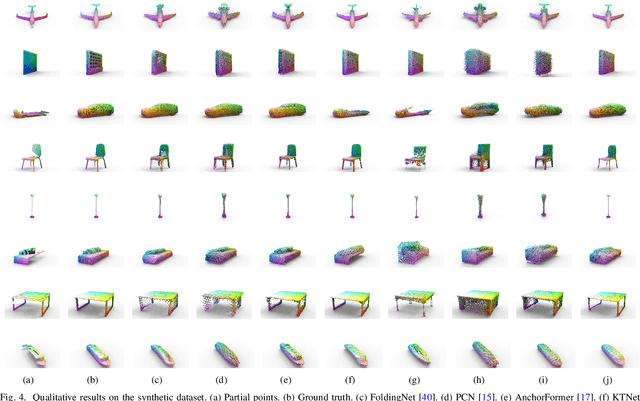
In real-world scenarios, scanned point clouds are often incomplete due to occlusion issues. The task of self-supervised point cloud completion involves reconstructing missing regions of these incomplete objects without the supervision of complete ground truth. Current self-supervised methods either rely on multiple views of partial observations for supervision or overlook the intrinsic geometric similarity that can be identified and utilized from the given partial point clouds. In this paper, we propose MAL-SPC, a framework that effectively leverages both object-level and category-specific geometric similarities to complete missing structures. Our MAL-SPC does not require any 3D complete supervision and only necessitates a single partial point cloud for each object. Specifically, we first introduce a Pattern Retrieval Network to retrieve similar position and curvature patterns between the partial input and the predicted shape, then leverage these similarities to densify and refine the reconstructed results. Additionally, we render the reconstructed complete shape into multi-view depth maps and design an adversarial learning module to learn the geometry of the target shape from category-specific single-view depth images. To achieve anisotropic rendering, we design a density-aware radius estimation algorithm to improve the quality of the rendered images. Our MAL-SPC yields the best results compared to current state-of-the-art methods.We will make the source code publicly available at \url{https://github.com/ltwu6/malspc
Global Structure-Aware Diffusion Process for Low-Light Image Enhancement
Oct 27, 2023This paper studies a diffusion-based framework to address the low-light image enhancement problem. To harness the capabilities of diffusion models, we delve into this intricate process and advocate for the regularization of its inherent ODE-trajectory. To be specific, inspired by the recent research that low curvature ODE-trajectory results in a stable and effective diffusion process, we formulate a curvature regularization term anchored in the intrinsic non-local structures of image data, i.e., global structure-aware regularization, which gradually facilitates the preservation of complicated details and the augmentation of contrast during the diffusion process. This incorporation mitigates the adverse effects of noise and artifacts resulting from the diffusion process, leading to a more precise and flexible enhancement. To additionally promote learning in challenging regions, we introduce an uncertainty-guided regularization technique, which wisely relaxes constraints on the most extreme regions of the image. Experimental evaluations reveal that the proposed diffusion-based framework, complemented by rank-informed regularization, attains distinguished performance in low-light enhancement. The outcomes indicate substantial advancements in image quality, noise suppression, and contrast amplification in comparison with state-of-the-art methods. We believe this innovative approach will stimulate further exploration and advancement in low-light image processing, with potential implications for other applications of diffusion models. The code is publicly available at https://github.com/jinnh/GSAD.
Deep Diversity-Enhanced Feature Representation of Hyperspectral Images
Jan 15, 2023
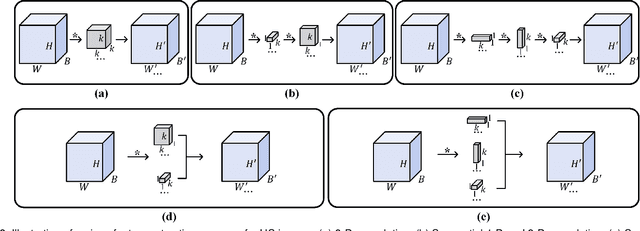
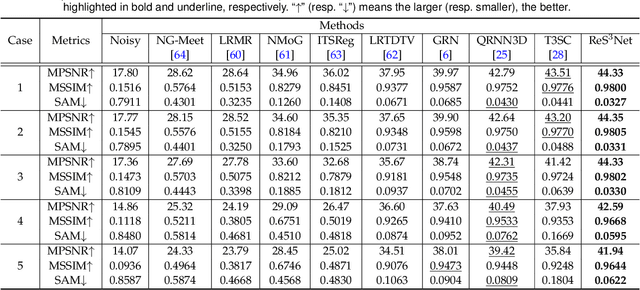
In this paper, we study the problem of embedding the high-dimensional spatio-spectral information of hyperspectral (HS) images efficiently and effectively, oriented by feature diversity. To be specific, based on the theoretical formulation that feature diversity is correlated with the rank of the unfolded kernel matrix, we rectify 3D convolution by modifying its topology to boost the rank upper-bound, yielding a rank-enhanced spatial-spectral symmetrical convolution set (ReS$^3$-ConvSet), which is able to not only learn diverse and powerful feature representations but also save network parameters. In addition, we also propose a novel diversity-aware regularization (DA-Reg) term, which acts directly on the feature maps to maximize the independence among elements. To demonstrate the superiority of the proposed ReS$^3$-ConvSet and DA-Reg, we apply them to various HS image processing and analysis tasks, including denoising, spatial super-resolution, and classification. Extensive experiments demonstrate that the proposed approaches outperform state-of-the-art methods to a significant extent both quantitatively and qualitatively. The code is publicly available at \url{https://github.com/jinnh/ReSSS-ConvSet}.
Improved CNN Prediction Based Reversible Data Hiding
Jan 04, 2023



This letter proposes an improved CNN predictor (ICNNP) for reversible data hiding (RDH) in images, which consists of a feature extraction module, a pixel prediction module, and a complexity prediction module. Due to predicting the complexity of each pixel with the ICNNP during the embedding process, the proposed method can achieve superior performance than the CNN predictor-based method. Specifically, an input image does be first split into two different sub-images, i.e., the "Dot" image and the "Cross" image. Meanwhile, each sub-image is applied to predict another one. Then, the prediction errors of pixels are sorted with the predicted pixel complexities. In light of this, some sorted prediction errors with less complexity are selected to be efficiently used for low-distortion data embedding with a traditional histogram shift scheme. Experimental results demonstrate that the proposed method can achieve better embedding performance than that of the CNN predictor with the same histogram shifting strategy.
Multi-scale Attentive Image De-raining Networks via Neural Architecture Search
Jul 02, 2022



Multi-scale architectures and attention modules have shown effectiveness in many deep learning-based image de-raining methods. However, manually designing and integrating these two components into a neural network requires a bulk of labor and extensive expertise. In this article, a high-performance multi-scale attentive neural architecture search (MANAS) framework is technically developed for image deraining. The proposed method formulates a new multi-scale attention search space with multiple flexible modules that are favorite to the image de-raining task. Under the search space, multi-scale attentive cells are built, which are further used to construct a powerful image de-raining network. The internal multiscale attentive architecture of the de-raining network is searched automatically through a gradient-based search algorithm, which avoids the daunting procedure of the manual design to some extent. Moreover, in order to obtain a robust image de-raining model, a practical and effective multi-to-one training strategy is also presented to allow the de-raining network to get sufficient background information from multiple rainy images with the same background scene, and meanwhile, multiple loss functions including external loss, internal loss, architecture regularization loss, and model complexity loss are jointly optimized to achieve robust de-raining performance and controllable model complexity. Extensive experimental results on both synthetic and realistic rainy images, as well as the down-stream vision applications (i.e., objection detection and segmentation) consistently demonstrate the superiority of our proposed method.