 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimuFreeMark: A Noise-Simulation-Free Robust Watermarking Against Image Editing
Nov 14, 2025



The advancement of artificial intelligence generated content (AIGC) has created a pressing need for robust image watermarking that can withstand both conventional signal processing and novel semantic editing attacks. Current deep learning-based methods rely on training with hand-crafted noise simulation layers, which inherently limit their generalization to unforeseen distortions. In this work, we propose $\textbf{SimuFreeMark}$, a noise-$\underline{\text{simu}}$lation-$\underline{\text{free}}$ water$\underline{\text{mark}}$ing framework that circumvents this limitation by exploiting the inherent stability of image low-frequency components. We first systematically establish that low-frequency components exhibit significant robustness against a wide range of attacks. Building on this foundation, SimuFreeMark embeds watermarks directly into the deep feature space of the low-frequency components, leveraging a pre-trained variational autoencoder (VAE) to bind the watermark with structurally stable image representations. This design completely eliminates the need for noise simulation during training. Extensive experiments demonstrate that SimuFreeMark outperforms state-of-the-art methods across a wide range of conventional and semantic attacks, while maintaining superior visual quality.
CoTSRF: Utilize Chain of Thought as Stealthy and Robust Fingerprint of Large Language Models
May 22, 2025



Despite providing superior performance, open-source large language models (LLMs) are vulnerable to abusive usage. To address this issue, recent works propose LLM fingerprinting methods to identify the specific source LLMs behind suspect applications. However, these methods fail to provide stealthy and robust fingerprint verification. In this paper, we propose a novel LLM fingerprinting scheme, namely CoTSRF, which utilizes the Chain of Thought (CoT) as the fingerprint of an LLM. CoTSRF first collects the responses from the source LLM by querying it with crafted CoT queries. Then, it applies contrastive learning to train a CoT extractor that extracts the CoT feature (i.e., fingerprint) from the responses. Finally, CoTSRF conducts fingerprint verification by comparing the Kullback-Leibler divergence between the CoT features of the source and suspect LLMs against an empirical threshold. Various experiments have been conducted to demonstrate the advantage of our proposed CoTSRF for fingerprinting LLMs, particularly in stealthy and robust fingerprint verification.
Adversarial Shallow Watermarking
Apr 28, 2025



Recent advances in digital watermarking make use of deep neural networks for message embedding and extraction. They typically follow the ``encoder-noise layer-decoder''-based architecture. By deliberately establishing a differentiable noise layer to simulate the distortion of the watermarked signal, they jointly train the deep encoder and decoder to fit the noise layer to guarantee robustness. As a result, they are usually weak against unknown distortions that are not used in their training pipeline. In this paper, we propose a novel watermarking framework to resist unknown distortions, namely Adversarial Shallow Watermarking (ASW). ASW utilizes only a shallow decoder that is randomly parameterized and designed to be insensitive to distortions for watermarking extraction. During the watermark embedding, ASW freezes the shallow decoder and adversarially optimizes a host image until its updated version (i.e., the watermarked image) stably triggers the shallow decoder to output the watermark message. During the watermark extraction, it accurately recovers the message from the watermarked image by leveraging the insensitive nature of the shallow decoder against arbitrary distortions. Our ASW is training-free, encoder-free, and noise layer-free. Experiments indicate that the watermarked images created by ASW have strong robustness against various unknown distortions. Compared to the existing ``encoder-noise layer-decoder'' approaches, ASW achieves comparable results on known distortions and better robustness on unknown distortions.
An Exceptional Dataset For Rare Pancreatic Tumor Segmentation
Jan 29, 2025Pancreatic NEuroendocrine Tumors (pNETs) are very rare endocrine neoplasms that account for less than 5% of all pancreatic malignancies, with an incidence of only 1-1.5 cases per 100,000. Early detection of pNETs is critical for improving patient survival, but the rarity of pNETs makes segmenting them from CT a very challenging problem. So far, there has not been a dataset specifically for pNETs available to researchers. To address this issue, we propose a pNETs dataset, a well-annotated Contrast-Enhanced Computed Tomography (CECT) dataset focused exclusively on Pancreatic Neuroendocrine Tumors, containing data from 469 patients. This is the first dataset solely dedicated to pNETs, distinguishing it from previous collections. Additionally, we provide the baseline detection networks with a new slice-wise weight loss function designed for the UNet-based model, improving the overall pNET segmentation performance. We hope that our dataset can enhance the understanding and diagnosis of pNET Tumors within the medical community, facilitate the development of more accurate diagnostic tools, and ultimately improve patient outcomes and advance the field of oncology.
Exploring Depth Information for Detecting Manipulated Face Videos
Nov 27, 2024
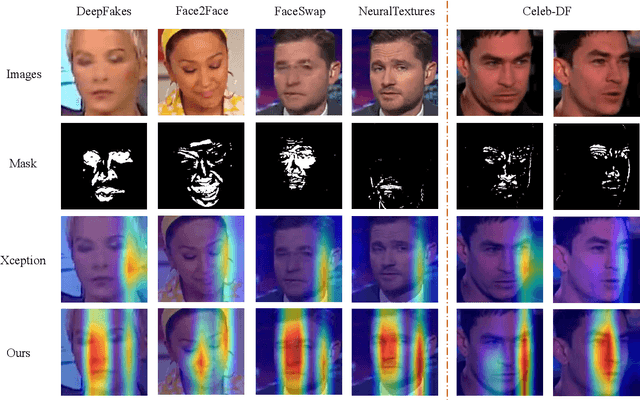


Face manipulation detection has been receiving a lot of attention for the reliability and security of the face images/videos. Recent studies focus on using auxiliary information or prior knowledge to capture robust manipulation traces, which are shown to be promising. As one of the important face features, the face depth map, which has shown to be effective in other areas such as face recognition or face detection, is unfortunately paid little attention to in literature for face manipulation detection. In this paper, we explore the possibility of incorporating the face depth map as auxiliary information for robust face manipulation detection. To this end, we first propose a Face Depth Map Transformer (FDMT) to estimate the face depth map patch by patch from an RGB face image, which is able to capture the local depth anomaly created due to manipulation. The estimated face depth map is then considered as auxiliary information to be integrated with the backbone features using a Multi-head Depth Attention (MDA) mechanism that is newly designed. We also propose an RGB-Depth Inconsistency Attention (RDIA) module to effectively capture the inter-frame inconsistency for multi-frame input. Various experiments demonstrate the advantage of our proposed method for face manipulation detection.
ScreenMark: Watermarking Arbitrary Visual Content on Screen
Sep 05, 2024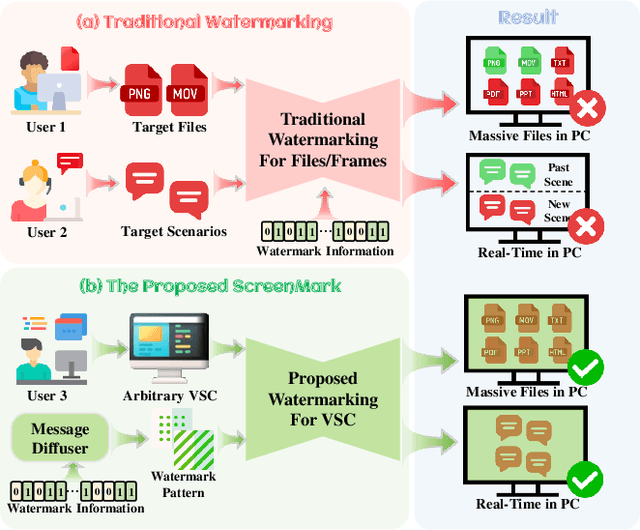
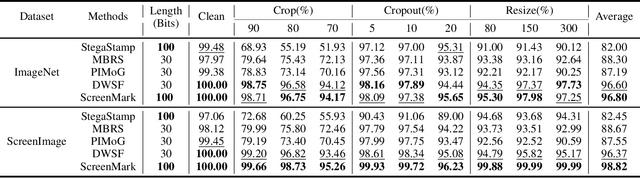
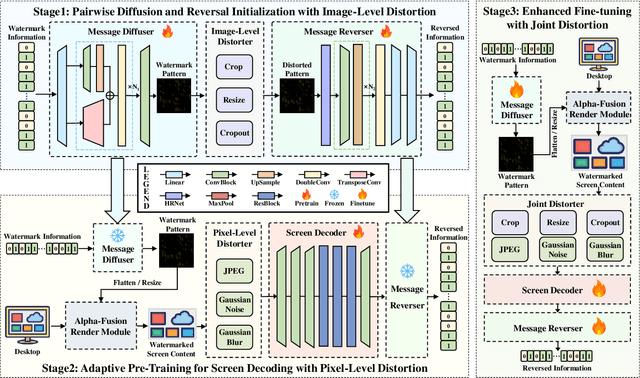
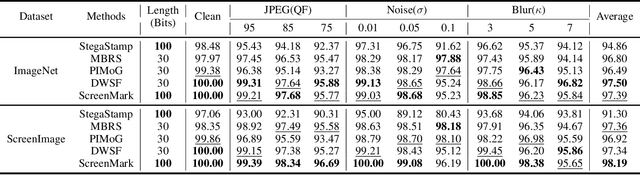
Digital watermarking has demonstrated its effectiveness in protecting multimedia content. However, existing watermarking are predominantly tailored for specific media types, rendering them less effective for the protection of content displayed on computer screens, which is often multimodal and dynamic. Visual Screen Content (VSC), is particularly susceptible to theft and leakage via screenshots, a vulnerability that current watermarking methods fail to adequately address.To tackle these challenges, we propose ScreenMark, a robust and practical watermarking method designed specifically for arbitrary VSC protection. ScreenMark utilizes a three-stage progressive watermarking framework. Initially, inspired by diffusion principles, we initialize the mutual transformation between regular watermark information and irregular watermark patterns. Subsequently, these patterns are integrated with screen content using a pre-multiplication alpha blending technique, supported by a pre-trained screen decoder for accurate watermark retrieval. The progressively complex distorter enhances the robustness of the watermark in real-world screenshot scenarios. Finally, the model undergoes fine-tuning guided by a joint-level distorter to ensure optimal performance.To validate the effectiveness of ScreenMark, we compiled a dataset comprising 100,000 screenshots from various devices and resolutions. Extensive experiments across different datasets confirm the method's superior robustness, imperceptibility, and practical applicability.
Revocable Backdoor for Deep Model Trading
Aug 01, 2024



Deep models are being applied in numerous fields and have become a new important digital product. Meanwhile, previous studies have shown that deep models are vulnerable to backdoor attacks, in which compromised models return attacker-desired results when a trigger appears. Backdoor attacks severely break the trust-worthiness of deep models. In this paper, we turn this weakness of deep models into a strength, and propose a novel revocable backdoor and deep model trading scenario. Specifically, we aim to compromise deep models without degrading their performance, meanwhile, we can easily detoxify poisoned models without re-training the models. We design specific mask matrices to manage the internal feature maps of the models. These mask matrices can be used to deactivate the backdoors. The revocable backdoor can be adopted in the deep model trading scenario. Sellers train models with revocable backdoors as a trial version. Buyers pay a deposit to sellers and obtain a trial version of the deep model. If buyers are satisfied with the trial version, they pay a final payment to sellers and sellers send mask matrices to buyers to withdraw revocable backdoors. We demonstrate the feasibility and robustness of our revocable backdoor by various datasets and network architectures.
Are handcrafted filters helpful for attributing AI-generated images?
Jul 23, 2024Recently, a vast number of image generation models have been proposed, which raises concerns regarding the misuse of these artificial intelligence (AI) techniques for generating fake images. To attribute the AI-generated images, existing schemes usually design and train deep neural networks (DNNs) to learn the model fingerprints, which usually requires a large amount of data for effective learning. In this paper, we aim to answer the following two questions for AI-generated image attribution, 1) is it possible to design useful handcrafted filters to facilitate the fingerprint learning? and 2) how we could reduce the amount of training data after we incorporate the handcrafted filters? We first propose a set of Multi-Directional High-Pass Filters (MHFs) which are capable to extract the subtle fingerprints from various directions. Then, we propose a Directional Enhanced Feature Learning network (DEFL) to take both the MHFs and randomly-initialized filters into consideration. The output of the DEFL is fused with the semantic features to produce a compact fingerprint. To make the compact fingerprint discriminative among different models, we propose a Dual-Margin Contrastive (DMC) loss to tune our DEFL. Finally, we propose a reference based fingerprint classification scheme for image attribution. Experimental results demonstrate that it is indeed helpful to use our MHFs for attributing the AI-generated images. The performance of our proposed method is significantly better than the state-of-the-art for both the closed-set and open-set image attribution, where only a small amount of images are required for training.
Cover-separable Fixed Neural Network Steganography via Deep Generative Models
Jul 16, 2024



Image steganography is the process of hiding secret data in a cover image by subtle perturbation. Recent studies show that it is feasible to use a fixed neural network for data embedding and extraction. Such Fixed Neural Network Steganography (FNNS) demonstrates favorable performance without the need for training networks, making it more practical for real-world applications. However, the stego-images generated by the existing FNNS methods exhibit high distortion, which is prone to be detected by steganalysis tools. To deal with this issue, we propose a Cover-separable Fixed Neural Network Steganography, namely Cs-FNNS. In Cs-FNNS, we propose a Steganographic Perturbation Search (SPS) algorithm to directly encode the secret data into an imperceptible perturbation, which is combined with an AI-generated cover image for transmission. Through accessing the same deep generative models, the receiver could reproduce the cover image using a pre-agreed key, to separate the perturbation in the stego-image for data decoding. such an encoding/decoding strategy focuses on the secret data and eliminates the disturbance of the cover images, hence achieving a better performance. We apply our Cs-FNNS to the steganographic field that hiding secret images within cover images. Through comprehensive experiments, we demonstrate the superior performance of the proposed method in terms of visual quality and undetectability. Moreover, we show the flexibility of our Cs-FNNS in terms of hiding multiple secret images for different receivers.
Search, Examine and Early-Termination: Fake News Detection with Annotation-Free Evidences
Jul 10, 2024Pioneer researches recognize evidences as crucial elements in fake news detection apart from patterns. Existing evidence-aware methods either require laborious pre-processing procedures to assure relevant and high-quality evidence data, or incorporate the entire spectrum of available evidences in all news cases, regardless of the quality and quantity of the retrieved data. In this paper, we propose an approach named \textbf{SEE} that retrieves useful information from web-searched annotation-free evidences with an early-termination mechanism. The proposed SEE is constructed by three main phases: \textbf{S}earching online materials using the news as a query and directly using their titles as evidences without any annotating or filtering procedure, sequentially \textbf{E}xamining the news alongside with each piece of evidence via attention mechanisms to produce new hidden states with retrieved information, and allowing \textbf{E}arly-termination within the examining loop by assessing whether there is adequate confidence for producing a correct prediction. We have conducted extensive experiments on datasets with unprocessed evidences, i.e., Weibo21, GossipCop, and pre-processed evidences, namely Snopes and PolitiFact. The experimental results demonstrate that the proposed method outperforms state-of-the-art approaches.