 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Anatomy of Vision-Language-Action Models: From Modules to Milestones and Challenges
Dec 19, 2025Vision-Language-Action (VLA) models are driving a revolution in robotics, enabling machines to understand instructions and interact with the physical world. This field is exploding with new models and datasets, making it both exciting and challenging to keep pace with. This survey offers a clear and structured guide to the VLA landscape. We design it to follow the natural learning path of a researcher: we start with the basic Modules of any VLA model, trace the history through key Milestones, and then dive deep into the core Challenges that define recent research frontier. Our main contribution is a detailed breakdown of the five biggest challenges in: (1) Representation, (2) Execution, (3) Generalization, (4) Safety, and (5) Dataset and Evaluation. This structure mirrors the developmental roadmap of a generalist agent: establishing the fundamental perception-action loop, scaling capabilities across diverse embodiments and environments, and finally ensuring trustworthy deployment-all supported by the essential data infrastructure. For each of them, we review existing approaches and highlight future opportunities. We position this paper as both a foundational guide for newcomers and a strategic roadmap for experienced researchers, with the dual aim of accelerating learning and inspiring new ideas in embodied intelligence. A live version of this survey, with continuous updates, is maintained on our \href{https://suyuz1.github.io/VLA-Survey-Anatomy/}{project page}.
Black-Box Auditing of Quantum Model: Lifted Differential Privacy with Quantum Canaries
Dec 16, 2025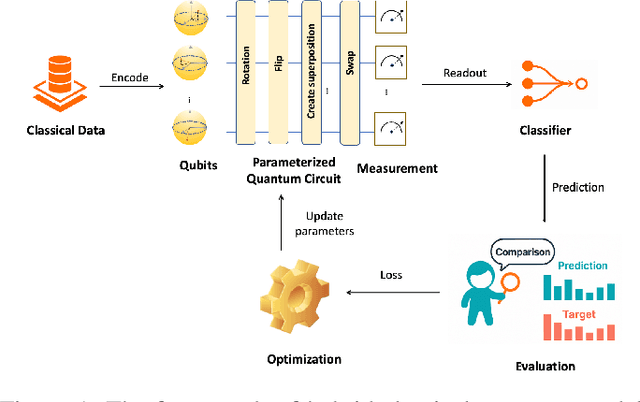



Quantum machine learning (QML) promises significant computational advantages, yet models trained on sensitive data risk memorizing individual records, creating serious privacy vulnerabilities. While Quantum Differential Privacy (QDP) mechanisms provide theoretical worst-case guarantees, they critically lack empirical verification tools for deployed models. We introduce the first black-box privacy auditing framework for QML based on Lifted Quantum Differential Privacy, leveraging quantum canaries (strategically offset-encoded quantum states) to detect memorization and precisely quantify privacy leakage during training. Our framework establishes a rigorous mathematical connection between canary offset and trace distance bounds, deriving empirical lower bounds on privacy budget consumption that bridge the critical gap between theoretical guarantees and practical privacy verification. Comprehensive evaluations across both simulated and physical quantum hardware demonstrate our framework's effectiveness in measuring actual privacy loss in QML models, enabling robust privacy verification in QML systems.
Experimental robustness benchmark of quantum neural network on a superconducting quantum processor
May 22, 2025Quantum machine learning (QML) models, like their classical counterparts, are vulnerable to adversarial attacks, hindering their secure deployment. Here, we report the first systematic experimental robustness benchmark for 20-qubit quantum neural network (QNN) classifiers executed on a superconducting processor. Our benchmarking framework features an efficient adversarial attack algorithm designed for QNNs, enabling quantitative characterization of adversarial robustness and robustness bounds. From our analysis, we verify that adversarial training reduces sensitivity to targeted perturbations by regularizing input gradients, significantly enhancing QNN's robustness. Additionally, our analysis reveals that QNNs exhibit superior adversarial robustness compared to classical neural networks, an advantage attributed to inherent quantum noise. Furthermore, the empirical upper bound extracted from our attack experiments shows a minimal deviation ($3 \times 10^{-3}$) from the theoretical lower bound, providing strong experimental confirmation of the attack's effectiveness and the tightness of fidelity-based robustness bounds. This work establishes a critical experimental framework for assessing and improving quantum adversarial robustness, paving the way for secure and reliable QML applications.
Neural Brain: A Neuroscience-inspired Framework for Embodied Agents
May 14, 2025The rapid evolution of artificial intelligence (AI) has shifted from static, data-driven models to dynamic systems capable of perceiving and interacting with real-world environments. Despite advancements in pattern recognition and symbolic reasoning, current AI systems, such as large language models, remain disembodied, unable to physically engage with the world. This limitation has driven the rise of embodied AI, where autonomous agents, such as humanoid robots, must navigate and manipulate unstructured environments with human-like adaptability. At the core of this challenge lies the concept of Neural Brain, a central intelligence system designed to drive embodied agents with human-like adaptability. A Neural Brain must seamlessly integrate multimodal sensing and perception with cognitive capabilities. Achieving this also requires an adaptive memory system and energy-efficient hardware-software co-design, enabling real-time action in dynamic environments. This paper introduces a unified framework for the Neural Brain of embodied agents, addressing two fundamental challenges: (1) defining the core components of Neural Brain and (2) bridging the gap between static AI models and the dynamic adaptability required for real-world deployment. To this end, we propose a biologically inspired architecture that integrates multimodal active sensing, perception-cognition-action function, neuroplasticity-based memory storage and updating, and neuromorphic hardware/software optimization. Furthermore, we also review the latest research on embodied agents across these four aspects and analyze the gap between current AI systems and human intelligence. By synthesizing insights from neuroscience, we outline a roadmap towards the development of generalizable, autonomous agents capable of human-level intelligence in real-world scenarios.
ShadowCoT: Cognitive Hijacking for Stealthy Reasoning Backdoors in LLMs
Apr 08, 2025



Chain-of-Thought (CoT) enhances an LLM's ability to perform complex reasoning tasks, but it also introduces new security issues. In this work, we present ShadowCoT, a novel backdoor attack framework that targets the internal reasoning mechanism of LLMs. Unlike prior token-level or prompt-based attacks, ShadowCoT directly manipulates the model's cognitive reasoning path, enabling it to hijack multi-step reasoning chains and produce logically coherent but adversarial outcomes. By conditioning on internal reasoning states, ShadowCoT learns to recognize and selectively disrupt key reasoning steps, effectively mounting a self-reflective cognitive attack within the target model. Our approach introduces a lightweight yet effective multi-stage injection pipeline, which selectively rewires attention pathways and perturbs intermediate representations with minimal parameter overhead (only 0.15% updated). ShadowCoT further leverages reinforcement learning and reasoning chain pollution (RCP) to autonomously synthesize stealthy adversarial CoTs that remain undetectable to advanced defenses. Extensive experiments across diverse reasoning benchmarks and LLMs show that ShadowCoT consistently achieves high Attack Success Rate (94.4%) and Hijacking Success Rate (88.4%) while preserving benign performance. These results reveal an emergent class of cognition-level threats and highlight the urgent need for defenses beyond shallow surface-level consistency.
Concept-Driven Deep Learning for Enhanced Protein-Specific Molecular Generation
Mar 11, 2025In recent years, deep learning techniques have made significant strides in molecular generation for specific targets, driving advancements in drug discovery. However, existing molecular generation methods present significant limitations: those operating at the atomic level often lack synthetic feasibility, drug-likeness, and interpretability, while fragment-based approaches frequently overlook comprehensive factors that influence protein-molecule interactions. To address these challenges, we propose a novel fragment-based molecular generation framework tailored for specific proteins. Our method begins by constructing a protein subpocket and molecular arm concept-based neural network, which systematically integrates interaction force information and geometric complementarity to sample molecular arms for specific protein subpockets. Subsequently, we introduce a diffusion model to generate molecular backbones that connect these arms, ensuring structural integrity and chemical diversity. Our approach significantly improves synthetic feasibility and binding affinity, with a 4% increase in drug-likeness and a 6% improvement in synthetic feasibility. Furthermore, by integrating explicit interaction data through a concept-based model, our framework enhances interpretability, offering valuable insights into the molecular design process.
Are handcrafted filters helpful for attributing AI-generated images?
Jul 23, 2024Recently, a vast number of image generation models have been proposed, which raises concerns regarding the misuse of these artificial intelligence (AI) techniques for generating fake images. To attribute the AI-generated images, existing schemes usually design and train deep neural networks (DNNs) to learn the model fingerprints, which usually requires a large amount of data for effective learning. In this paper, we aim to answer the following two questions for AI-generated image attribution, 1) is it possible to design useful handcrafted filters to facilitate the fingerprint learning? and 2) how we could reduce the amount of training data after we incorporate the handcrafted filters? We first propose a set of Multi-Directional High-Pass Filters (MHFs) which are capable to extract the subtle fingerprints from various directions. Then, we propose a Directional Enhanced Feature Learning network (DEFL) to take both the MHFs and randomly-initialized filters into consideration. The output of the DEFL is fused with the semantic features to produce a compact fingerprint. To make the compact fingerprint discriminative among different models, we propose a Dual-Margin Contrastive (DMC) loss to tune our DEFL. Finally, we propose a reference based fingerprint classification scheme for image attribution. Experimental results demonstrate that it is indeed helpful to use our MHFs for attributing the AI-generated images. The performance of our proposed method is significantly better than the state-of-the-art for both the closed-set and open-set image attribution, where only a small amount of images are required for training.
360SFUDA++: Towards Source-free UDA for Panoramic Segmentation by Learning Reliable Category Prototypes
Apr 25, 2024



In this paper, we address the challenging source-free unsupervised domain adaptation (SFUDA) for pinhole-to-panoramic semantic segmentation, given only a pinhole image pre-trained model (i.e., source) and unlabeled panoramic images (i.e., target). Tackling this problem is non-trivial due to three critical challenges: 1) semantic mismatches from the distinct Field-of-View (FoV) between domains, 2) style discrepancies inherent in the UDA problem, and 3) inevitable distortion of the panoramic images. To tackle these problems, we propose 360SFUDA++ that effectively extracts knowledge from the source pinhole model with only unlabeled panoramic images and transfers the reliable knowledge to the target panoramic domain. Specifically, we first utilize Tangent Projection (TP) as it has less distortion and meanwhile slits the equirectangular projection (ERP) to patches with fixed FoV projection (FFP) to mimic the pinhole images. Both projections are shown effective in extracting knowledge from the source model. However, as the distinct projections make it less possible to directly transfer knowledge between domains, we then propose Reliable Panoramic Prototype Adaptation Module (RP2AM) to transfer knowledge at both prediction and prototype levels. RP$^2$AM selects the confident knowledge and integrates panoramic prototypes for reliable knowledge adaptation. Moreover, we introduce Cross-projection Dual Attention Module (CDAM), which better aligns the spatial and channel characteristics across projections at the feature level between domains. Both knowledge extraction and transfer processes are synchronously updated to reach the best performance. Extensive experiments on the synthetic and real-world benchmarks, including outdoor and indoor scenarios, demonstrate that our 360SFUDA++ achieves significantly better performance than prior SFUDA methods.
Unsupervised Visible-Infrared ReID via Pseudo-label Correction and Modality-level Alignment
Apr 10, 2024



Unsupervised visible-infrared person re-identification (UVI-ReID) has recently gained great attention due to its potential for enhancing human detection in diverse environments without labeling. Previous methods utilize intra-modality clustering and cross-modality feature matching to achieve UVI-ReID. However, there exist two challenges: 1) noisy pseudo labels might be generated in the clustering process, and 2) the cross-modality feature alignment via matching the marginal distribution of visible and infrared modalities may misalign the different identities from two modalities. In this paper, we first conduct a theoretic analysis where an interpretable generalization upper bound is introduced. Based on the analysis, we then propose a novel unsupervised cross-modality person re-identification framework (PRAISE). Specifically, to address the first challenge, we propose a pseudo-label correction strategy that utilizes a Beta Mixture Model to predict the probability of mis-clustering based network's memory effect and rectifies the correspondence by adding a perceptual term to contrastive learning. Next, we introduce a modality-level alignment strategy that generates paired visible-infrared latent features and reduces the modality gap by aligning the labeling function of visible and infrared features to learn identity discriminative and modality-invariant features. Experimental results on two benchmark datasets demonstrate that our method achieves state-of-the-art performance than the unsupervised visible-ReID methods.
Semantics, Distortion, and Style Matter: Towards Source-free UDA for Panoramic Segmentation
Mar 22, 2024



This paper addresses an interesting yet challenging problem -- source-free unsupervised domain adaptation (SFUDA) for pinhole-to-panoramic semantic segmentation -- given only a pinhole image-trained model (i.e., source) and unlabeled panoramic images (i.e., target). Tackling this problem is nontrivial due to the semantic mismatches, style discrepancies, and inevitable distortion of panoramic images. To this end, we propose a novel method that utilizes Tangent Projection (TP) as it has less distortion and meanwhile slits the equirectangular projection (ERP) with a fixed FoV to mimic the pinhole images. Both projections are shown effective in extracting knowledge from the source model. However, the distinct projection discrepancies between source and target domains impede the direct knowledge transfer; thus, we propose a panoramic prototype adaptation module (PPAM) to integrate panoramic prototypes from the extracted knowledge for adaptation. We then impose the loss constraints on both predictions and prototypes and propose a cross-dual attention module (CDAM) at the feature level to better align the spatial and channel characteristics across the domains and projections. Both knowledge extraction and transfer processes are synchronously updated to reach the best performance. Extensive experiments on the synthetic and real-world benchmarks, including outdoor and indoor scenarios, demonstrate that our method achieves significantly better performance than prior SFUDA methods for pinhole-to-panoramic adaptation.