 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAct, Sense, Act: Learning Non-Markovian Active Perception Strategies from Large-Scale Egocentric Human Data
Feb 04, 2026Achieving generalizable manipulation in unconstrained environments requires the robot to proactively resolve information uncertainty, i.e., the capability of active perception. However, existing methods are often confined in limited types of sensing behaviors, restricting their applicability to complex environments. In this work, we formalize active perception as a non-Markovian process driven by information gain and decision branching, providing a structured categorization of visual active perception paradigms. Building on this perspective, we introduce CoMe-VLA, a cognitive and memory-aware vision-language-action (VLA) framework that leverages large-scale human egocentric data to learn versatile exploration and manipulation priors. Our framework integrates a cognitive auxiliary head for autonomous sub-task transitions and a dual-track memory system to maintain consistent self and environmental awareness by fusing proprioceptive and visual temporal contexts. By aligning human and robot hand-eye coordination behaviors in a unified egocentric action space, we train the model progressively in three stages. Extensive experiments on a wheel-based humanoid have demonstrated strong robustness and adaptability of our proposed method across diverse long-horizon tasks spanning multiple active perception scenarios.
MovSemCL: Movement-Semantics Contrastive Learning for Trajectory Similarity
Nov 15, 2025Trajectory similarity computation is fundamental functionality that is used for, e.g., clustering, prediction, and anomaly detection. However, existing learning-based methods exhibit three key limitations: (1) insufficient modeling of trajectory semantics and hierarchy, lacking both movement dynamics extraction and multi-scale structural representation; (2) high computational costs due to point-wise encoding; and (3) use of physically implausible augmentations that distort trajectory semantics. To address these issues, we propose MovSemCL, a movement-semantics contrastive learning framework for trajectory similarity computation. MovSemCL first transforms raw GPS trajectories into movement-semantics features and then segments them into patches. Next, MovSemCL employs intra- and inter-patch attentions to encode local as well as global trajectory patterns, enabling efficient hierarchical representation and reducing computational costs. Moreover, MovSemCL includes a curvature-guided augmentation strategy that preserves informative segments (e.g., turns and intersections) and masks redundant ones, generating physically plausible augmented views. Experiments on real-world datasets show that MovSemCL is capable of outperforming state-of-the-art methods, achieving mean ranks close to the ideal value of 1 at similarity search tasks and improvements by up to 20.3% at heuristic approximation, while reducing inference latency by up to 43.4%.
SAGE: Scene Graph-Aware Guidance and Execution for Long-Horizon Manipulation Tasks
Sep 26, 2025Successfully solving long-horizon manipulation tasks remains a fundamental challenge. These tasks involve extended action sequences and complex object interactions, presenting a critical gap between high-level symbolic planning and low-level continuous control. To bridge this gap, two essential capabilities are required: robust long-horizon task planning and effective goal-conditioned manipulation. Existing task planning methods, including traditional and LLM-based approaches, often exhibit limited generalization or sparse semantic reasoning. Meanwhile, image-conditioned control methods struggle to adapt to unseen tasks. To tackle these problems, we propose SAGE, a novel framework for Scene Graph-Aware Guidance and Execution in Long-Horizon Manipulation Tasks. SAGE utilizes semantic scene graphs as a structural representation for scene states. A structural scene graph enables bridging task-level semantic reasoning and pixel-level visuo-motor control. This also facilitates the controllable synthesis of accurate, novel sub-goal images. SAGE consists of two key components: (1) a scene graph-based task planner that uses VLMs and LLMs to parse the environment and reason about physically-grounded scene state transition sequences, and (2) a decoupled structural image editing pipeline that controllably converts each target sub-goal graph into a corresponding image through image inpainting and composition. Extensive experiments have demonstrated that SAGE achieves state-of-the-art performance on distinct long-horizon tasks.
Improving the Temporal Resolution of SOHO/MDI Magnetograms of Solar Active Regions Using a Deep Generative Model
Mar 05, 2025



We present a novel deep generative model, named GenMDI, to improve the temporal resolution of line-of-sight (LOS) magnetograms of solar active regions (ARs) collected by the Michelson Doppler Imager (MDI) on board the Solar and Heliospheric Observatory (SOHO). Unlike previous studies that focus primarily on spatial super-resolution of MDI magnetograms, our approach can perform temporal super-resolution, which generates and inserts synthetic data between observed MDI magnetograms, thus providing finer temporal structure and enhanced details in the LOS data. The GenMDI model employs a conditional diffusion process, which synthesizes images by considering both preceding and subsequent magnetograms, ensuring that the generated images are not only of high-quality, but also temporally coherent with the surrounding data. Experimental results show that the GenMDI model performs better than the traditional linear interpolation method, especially in ARs with dynamic evolution in magnetic fields.
Poly2Vec: Polymorphic Encoding of Geospatial Objects for Spatial Reasoning with Deep Neural Networks
Aug 27, 2024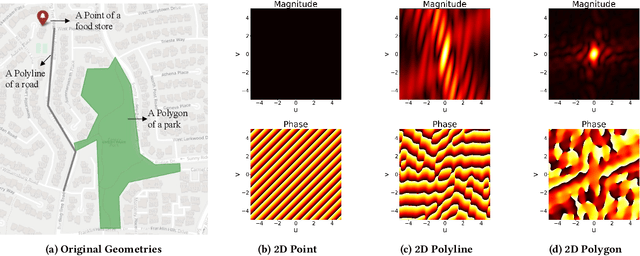
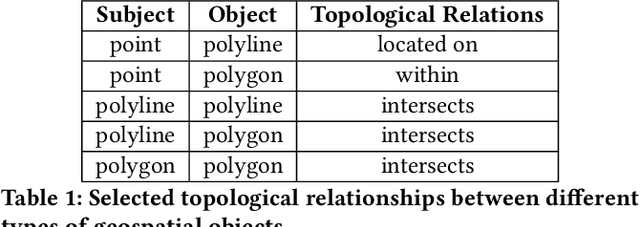
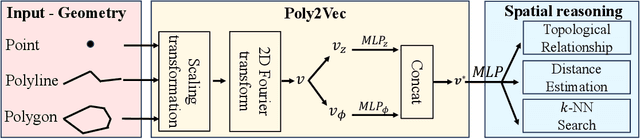
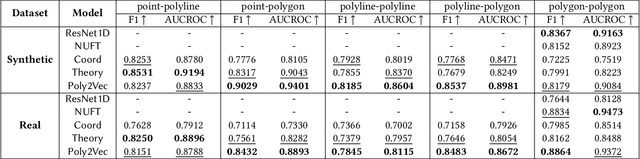
Encoding geospatial data is crucial for enabling machine learning (ML) models to perform tasks that require spatial reasoning, such as identifying the topological relationships between two different geospatial objects. However, existing encoding methods are limited as they are typically customized to handle only specific types of spatial data, which impedes their applicability across different downstream tasks where multiple data types coexist. To address this, we introduce Poly2Vec, an encoding framework that unifies the modeling of different geospatial objects, including 2D points, polylines, and polygons, irrespective of the downstream task. We leverage the power of the 2D Fourier transform to encode useful spatial properties, such as shape and location, from geospatial objects into fixed-length vectors. These vectors are then inputted into neural network models for spatial reasoning tasks.This unified approach eliminates the need to develop and train separate models for each distinct spatial type. We evaluate Poly2Vec on both synthetic and real datasets of mixed geometry types and verify its consistent performance across several downstream spatial reasoning tasks.
Are handcrafted filters helpful for attributing AI-generated images?
Jul 23, 2024Recently, a vast number of image generation models have been proposed, which raises concerns regarding the misuse of these artificial intelligence (AI) techniques for generating fake images. To attribute the AI-generated images, existing schemes usually design and train deep neural networks (DNNs) to learn the model fingerprints, which usually requires a large amount of data for effective learning. In this paper, we aim to answer the following two questions for AI-generated image attribution, 1) is it possible to design useful handcrafted filters to facilitate the fingerprint learning? and 2) how we could reduce the amount of training data after we incorporate the handcrafted filters? We first propose a set of Multi-Directional High-Pass Filters (MHFs) which are capable to extract the subtle fingerprints from various directions. Then, we propose a Directional Enhanced Feature Learning network (DEFL) to take both the MHFs and randomly-initialized filters into consideration. The output of the DEFL is fused with the semantic features to produce a compact fingerprint. To make the compact fingerprint discriminative among different models, we propose a Dual-Margin Contrastive (DMC) loss to tune our DEFL. Finally, we propose a reference based fingerprint classification scheme for image attribution. Experimental results demonstrate that it is indeed helpful to use our MHFs for attributing the AI-generated images. The performance of our proposed method is significantly better than the state-of-the-art for both the closed-set and open-set image attribution, where only a small amount of images are required for training.
Addressing Shortcomings in Fair Graph Learning Datasets: Towards a New Benchmark
Mar 09, 2024



Fair graph learning plays a pivotal role in numerous practical applications. Recently, many fair graph learning methods have been proposed; however, their evaluation often relies on poorly constructed semi-synthetic datasets or substandard real-world datasets. In such cases, even a basic Multilayer Perceptron (MLP) can outperform Graph Neural Networks (GNNs) in both utility and fairness. In this work, we illustrate that many datasets fail to provide meaningful information in the edges, which may challenge the necessity of using graph structures in these problems. To address these issues, we develop and introduce a collection of synthetic, semi-synthetic, and real-world datasets that fulfill a broad spectrum of requirements. These datasets are thoughtfully designed to include relevant graph structures and bias information crucial for the fair evaluation of models. The proposed synthetic and semi-synthetic datasets offer the flexibility to create data with controllable bias parameters, thereby enabling the generation of desired datasets with user-defined bias values with ease. Moreover, we conduct systematic evaluations of these proposed datasets and establish a unified evaluation approach for fair graph learning models. Our extensive experimental results with fair graph learning methods across our datasets demonstrate their effectiveness in benchmarking the performance of these methods. Our datasets and the code for reproducing our experiments are available at https://github.com/XweiQ/Benchmark-GraphFairness.
Estimating Coronal Mass Ejection Mass and Kinetic Energy by Fusion of Multiple Deep-learning Models
Dec 04, 2023Coronal mass ejections (CMEs) are massive solar eruptions, which have a significant impact on Earth. In this paper, we propose a new method, called DeepCME, to estimate two properties of CMEs, namely, CME mass and kinetic energy. Being able to estimate these properties helps better understand CME dynamics. Our study is based on the CME catalog maintained at the Coordinated Data Analysis Workshops (CDAW) Data Center, which contains all CMEs manually identified since 1996 using the Large Angle and Spectrometric Coronagraph (LASCO) on board the Solar and Heliospheric Observatory (SOHO). We use LASCO C2 data in the period between January 1996 and December 2020 to train, validate and test DeepCME through 10-fold cross validation. The DeepCME method is a fusion of three deep learning models, including ResNet, InceptionNet, and InceptionResNet. Our fusion model extracts features from LASCO C2 images, effectively combining the learning capabilities of the three component models to jointly estimate the mass and kinetic energy of CMEs. Experimental results show that the fusion model yields a mean relative error (MRE) of 0.013 (0.009, respectively) compared to the MRE of 0.019 (0.017, respectively) of the best component model InceptionResNet (InceptionNet, respectively) in estimating the CME mass (kinetic energy, respectively). To our knowledge, this is the first time that deep learning has been used for CME mass and kinetic energy estimations.
* 10 pages, 7 figures
Improving Fairness of Graph Neural Networks: A Graph Counterfactual Perspective
Jul 10, 2023



Graph neural networks have shown great ability in representation (GNNs) learning on graphs, facilitating various tasks. Despite their great performance in modeling graphs, recent works show that GNNs tend to inherit and amplify the bias from training data, causing concerns of the adoption of GNNs in high-stake scenarios. Hence, many efforts have been taken for fairness-aware GNNs. However, most existing fair GNNs learn fair node representations by adopting statistical fairness notions, which may fail to alleviate bias in the presence of statistical anomalies. Motivated by causal theory, there are several attempts utilizing graph counterfactual fairness to mitigate root causes of unfairness. However, these methods suffer from non-realistic counterfactuals obtained by perturbation or generation. In this paper, we take a causal view on fair graph learning problem. Guided by the casual analysis, we propose a novel framework CAF, which can select counterfactuals from training data to avoid non-realistic counterfactuals and adopt selected counterfactuals to learn fair node representations for node classification task. Extensive experiments on synthetic and real-world datasets show the effectiveness of CAF.
Limited Query Graph Connectivity Test
Feb 25, 2023We propose a combinatorial optimisation model called Limited Query Graph Connectivity Test. We consider a graph whose edges have two possible states (on/off). The edges' states are hidden initially. We could query an edge to reveal its state. Given a source s and a destination t, we aim to test s-t connectivity by identifying either a path (consisting of only on edges) or a cut (consisting of only off edges). We are limited to B queries, after which we stop regardless of whether graph connectivity is established. We aim to design a query policy that minimizes the expected number of queries. If we remove the query limit B (i.e., by setting B to the total number of edges), then our problem becomes a special case of (monotone) Stochastic Boolean Function Evaluation (SBFE). There are two existing exact algorithms that are prohibitively expensive. They have best known upper bounds of O(3^m) and O(2^{2^k}) respectively, where m is the number of edges and k is the number of paths/cuts. These algorithms do not scale well in practice. We propose a significantly more scalable exact algorithm. Our exact algorithm works by iteratively improving the performance lower bound until the lower bound becomes achievable. Even when our exact algorithm does not scale, it can be used as an anytime algorithm for calculating lower bound. We experiment on a wide range of practical graphs. We observe that even for large graphs (i.e., tens of thousands of edges), it mostly takes only a few queries to reach conclusion, which is the practical motivation behind the query limit B. B is also an algorithm parameter that controls scalability. For small B, our exact algorithm scales well. For large B, our exact algorithm can be converted to a heuristic (i.e., always pretend that there are only 5 queries left). Our heuristic outperforms all existing heuristics ported from SBFE and related literature.