 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajGPT: Controlled Synthetic Trajectory Generation Using a Multitask Transformer-Based Spatiotemporal Model
Nov 07, 2024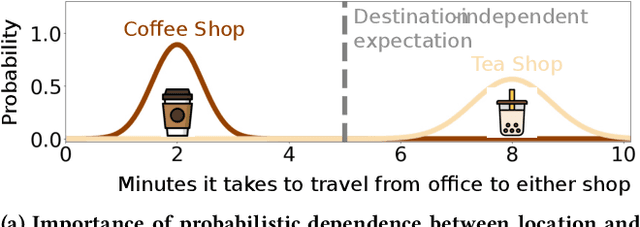

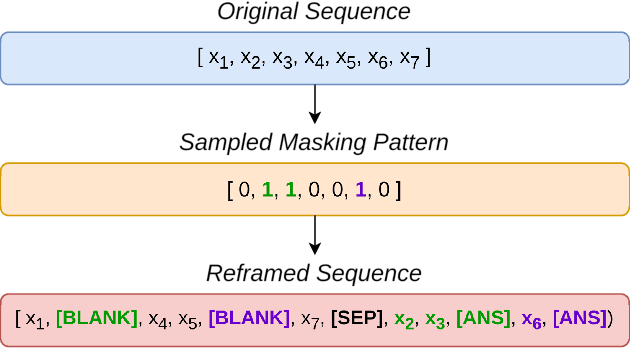

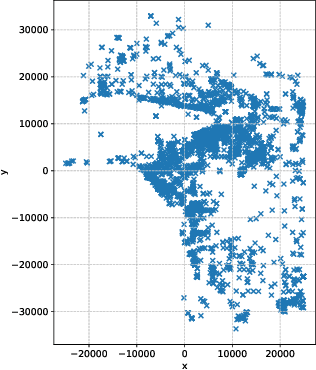
Human mobility modeling from GPS-trajectories and synthetic trajectory generation are crucial for various applications, such as urban planning, disaster management and epidemiology. Both of these tasks often require filling gaps in a partially specified sequence of visits - a new problem that we call "controlled" synthetic trajectory generation. Existing methods for next-location prediction or synthetic trajectory generation cannot solve this problem as they lack the mechanisms needed to constrain the generated sequences of visits. Moreover, existing approaches (1) frequently treat space and time as independent factors, an assumption that fails to hold true in real-world scenarios, and (2) suffer from challenges in accuracy of temporal prediction as they fail to deal with mixed distributions and the inter-relationships of different modes with latent variables (e.g., day-of-the-week). These limitations become even more pronounced when the task involves filling gaps within sequences instead of solely predicting the next visit. We introduce TrajGPT, a transformer-based, multi-task, joint spatiotemporal generative model to address these issues. Taking inspiration from large language models, TrajGPT poses the problem of controlled trajectory generation as that of text infilling in natural language. TrajGPT integrates the spatial and temporal models in a transformer architecture through a Bayesian probability model that ensures that the gaps in a visit sequence are filled in a spatiotemporally consistent manner. Our experiments on public and private datasets demonstrate that TrajGPT not only excels in controlled synthetic visit generation but also outperforms competing models in next-location prediction tasks - Relatively, TrajGPT achieves a 26-fold improvement in temporal accuracy while retaining more than 98% of spatial accuracy on average.
Poly2Vec: Polymorphic Encoding of Geospatial Objects for Spatial Reasoning with Deep Neural Networks
Aug 27, 2024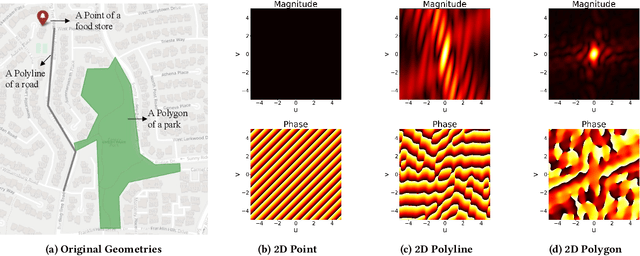
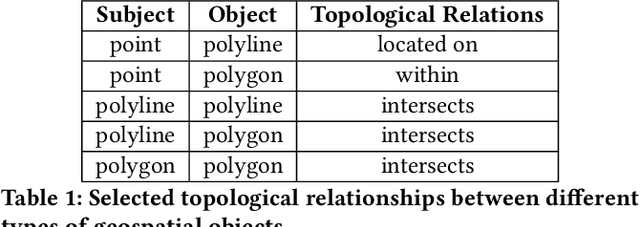
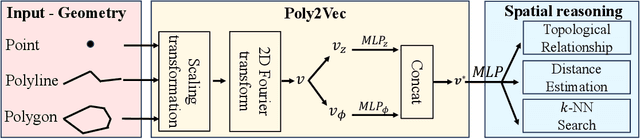
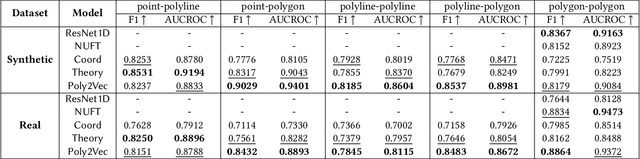
Encoding geospatial data is crucial for enabling machine learning (ML) models to perform tasks that require spatial reasoning, such as identifying the topological relationships between two different geospatial objects. However, existing encoding methods are limited as they are typically customized to handle only specific types of spatial data, which impedes their applicability across different downstream tasks where multiple data types coexist. To address this, we introduce Poly2Vec, an encoding framework that unifies the modeling of different geospatial objects, including 2D points, polylines, and polygons, irrespective of the downstream task. We leverage the power of the 2D Fourier transform to encode useful spatial properties, such as shape and location, from geospatial objects into fixed-length vectors. These vectors are then inputted into neural network models for spatial reasoning tasks.This unified approach eliminates the need to develop and train separate models for each distinct spatial type. We evaluate Poly2Vec on both synthetic and real datasets of mixed geometry types and verify its consistent performance across several downstream spatial reasoning tasks.
Reliable Geofence Activation with Sparse and Sporadic Location Measurements: Extended Version
Apr 01, 2022



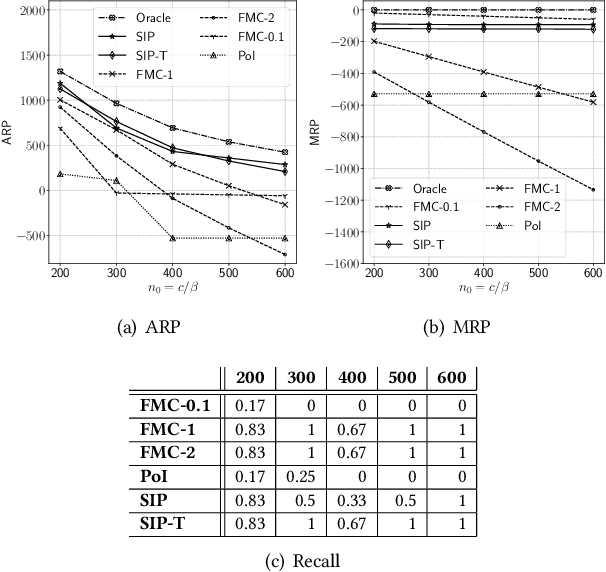
Geofences are a fundamental tool of location-based services. A geofence is usually activated by detecting a location measurement inside the geofence region. However, location measurements such as GPS often appear sporadically on smartphones, partly due to weak signal, or privacy preservation, because users may restrict location sensing, or energy conservation, because sensing locations can consume a significant amount of energy. These unpredictable, and sometimes long, gaps between measurements mean that entry into a geofence can go completely undetected. In this paper we argue that short term location prediction can help alleviate this problem by computing the probability of entering a geofence in the future. Complicating this prediction approach is the fact that another location measurement could appear at any time, making the prediction redundant and wasteful. Therefore, we develop a framework that accounts for uncertain location predictions and the possibility of new measurements to trigger geofence activations. Our framework optimizes over the benefits and costs of correct and incorrect geofence activations, leading to an algorithm that reacts intelligently to the uncertainties of future movements and measurements.
Gaussian Process for Trajectories
Oct 07, 2021

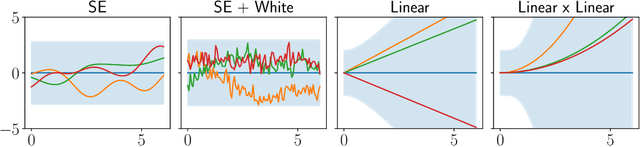

The Gaussian process is a powerful and flexible technique for interpolating spatiotemporal data, especially with its ability to capture complex trends and uncertainty from the input signal. This chapter describes Gaussian processes as an interpolation technique for geospatial trajectories. A Gaussian process models measurements of a trajectory as coming from a multidimensional Gaussian, and it produces for each timestamp a Gaussian distribution as a prediction. We discuss elements that need to be considered when applying Gaussian process to trajectories, common choices for those elements, and provide a concrete example of implementing a Gaussian process.
Spatial Privacy Pricing: The Interplay between Privacy, Utility and Price in Geo-Marketplaces
Sep 04, 2020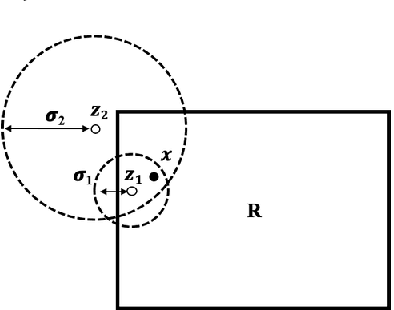
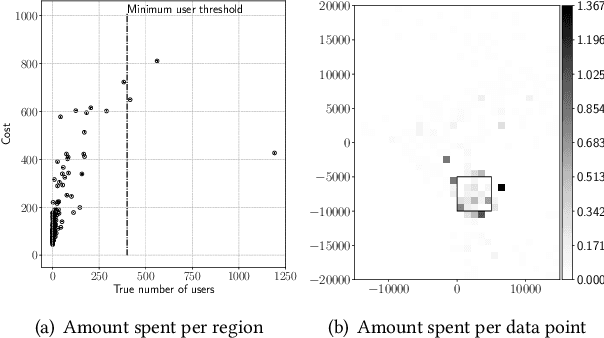
A geo-marketplace allows users to be paid for their location data. Users concerned about privacy may want to charge more for data that pinpoints their location accurately, but may charge less for data that is more vague. A buyer would prefer to minimize data costs, but may have to spend more to get the necessary level of accuracy. We call this interplay between privacy, utility, and price \emph{spatial privacy pricing}. We formalize the issues mathematically with an example problem of a buyer deciding whether or not to open a restaurant by purchasing location data to determine if the potential number of customers is sufficient to open. The problem is expressed as a sequential decision making problem, where the buyer first makes a series of decisions about which data to buy and concludes with a decision about opening the restaurant or not. We present two algorithms to solve this problem, including experiments that show they perform better than baselines.
SemEval-2020 Task 7: Assessing Humor in Edited News Headlines
Aug 01, 2020


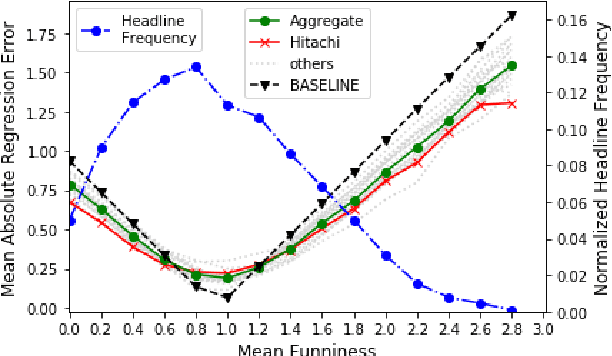
This paper describes the SemEval-2020 shared task "Assessing Humor in Edited News Headlines." The task's dataset contains news headlines in which short edits were applied to make them funny, and the funniness of these edited headlines was rated using crowdsourcing. This task includes two subtasks, the first of which is to estimate the funniness of headlines on a humor scale in the interval 0-3. The second subtask is to predict, for a pair of edited versions of the same original headline, which is the funnier version. To date, this task is the most popular shared computational humor task, attracting 48 teams for the first subtask and 31 teams for the second.
Stimulating Creativity with FunLines: A Case Study of Humor Generation in Headlines
Feb 05, 2020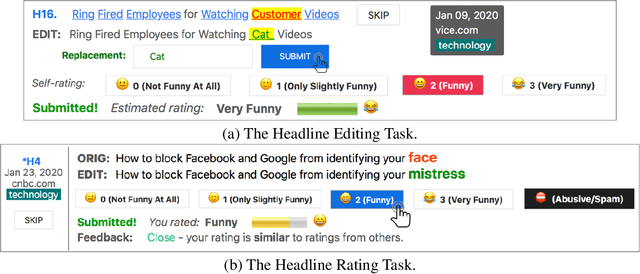


Building datasets of creative text, such as humor, is quite challenging. We introduce FunLines, a competitive game where players edit news headlines to make them funny, and where they rate the funniness of headlines edited by others. FunLines makes the humor generation process fun, interactive, collaborative, rewarding and educational, keeping players engaged and providing humor data at a very low cost compared to traditional crowdsourcing approaches. FunLines offers useful performance feedback, assisting players in getting better over time at generating and assessing humor, as our analysis shows. This helps to further increase the quality of the generated dataset. We show the effectiveness of this data by training humor classification models that outperform a previous benchmark, and we release this dataset to the public.
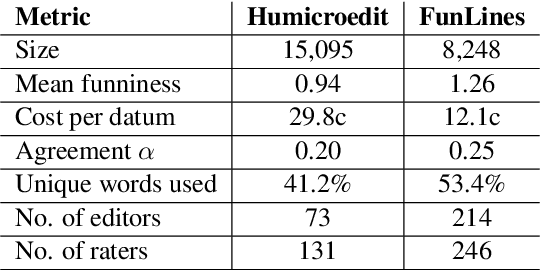
"President Vows to Cut <Taxes> Hair": Dataset and Analysis of Creative Text Editing for Humorous Headlines
Jun 01, 2019
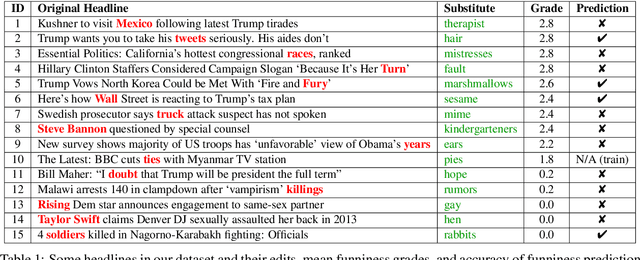
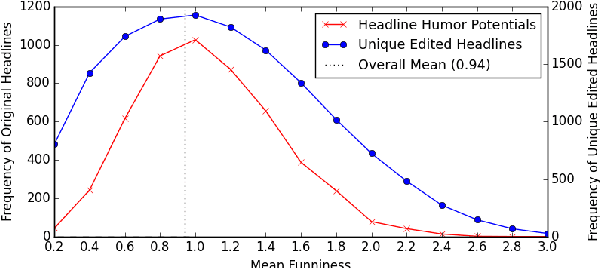
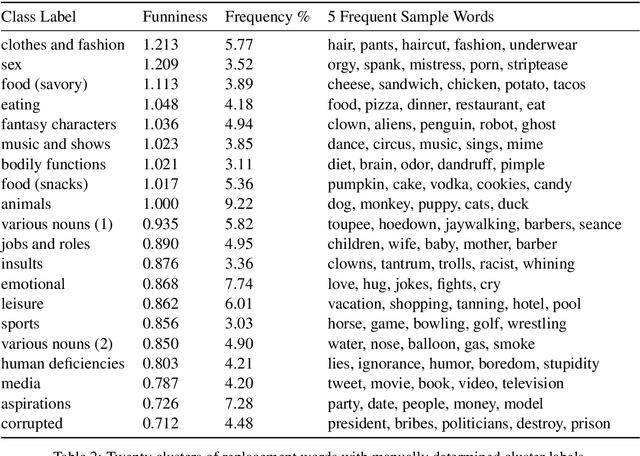
We introduce, release, and analyze a new dataset, called Humicroedit, for research in computational humor. Our publicly available data consists of regular English news headlines paired with versions of the same headlines that contain simple replacement edits designed to make them funny. We carefully curated crowdsourced editors to create funny headlines and judges to score a to a total of 15,095 edited headlines, with five judges per headline. The simple edits, usually just a single word replacement, mean we can apply straightforward analysis techniques to determine what makes our edited headlines humorous. We show how the data support classic theories of humor, such as incongruity, superiority, and setup/punchline. Finally, we develop baseline classifiers that can predict whether or not an edited headline is funny, which is a first step toward automatically generating humorous headlines as an approach to creating topical humor.