 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIlov3Splat: Instance-Level Open-Vocabulary 3D Scene Understanding in Gaussian Splatting
May 06, 2026We introduce Ilov3Splat, a novel framework for instance-level open-vocabulary 3D scene understanding built on 3D Gaussian Splatting (3D-GS). Most prior work depends on 2D rendering-based matching or point-level semantic association, which undermines cross-view consistency, lacks coherent instance-level reasoning, and limits precision in downstream 3D tasks. To address these limitations, our method jointly optimizes scene geometry and semantic representations by augmenting Gaussian splats with view-consistent feature fields. Specifically, we leverage multi-resolution hash embedding to efficiently encode language-aligned CLIP features, enabling dense and coherent language grounding in 3D space. We further train an instance feature field using contrastive loss over SAM masks, supporting fine-grained object distinction across views. At inference time, CLIP-encoded queries are matched against the learned features, followed by two-stage 3D clustering to retrieve relevant Gaussian groups. This enables our framework to identify arbitrary objects in 3D scenes based on natural language descriptions, without requiring category supervision or manual annotations. Experiments on standard benchmarks demonstrate that Ilov3Splat outperforms prior open-vocabulary 3D-GS methods in both object selection and instance segmentation, offering a flexible and accurate solution for language-driven 3D scene understanding. Project page: https://csiro-robotics.github.io/Ilov3Splat.
InverFill: One-Step Inversion for Enhanced Few-Step Diffusion Inpainting
Mar 24, 2026Recent diffusion-based models achieve photorealism in image inpainting but require many sampling steps, limiting practical use. Few-step text-to-image models offer faster generation, but naively applying them to inpainting yields poor harmonization and artifacts between the background and inpainted region. We trace this cause to random Gaussian noise initialization, which under low function evaluations causes semantic misalignment and reduced fidelity. To overcome this, we propose InverFill, a one-step inversion method tailored for inpainting that injects semantic information from the input masked image into the initial noise, enabling high-fidelity few-step inpainting. Instead of training inpainting models, InverFill leverages few-step text-to-image models in a blended sampling pipeline with semantically aligned noise as input, significantly improving vanilla blended sampling and even matching specialized inpainting models at low NFEs. Moreover, InverFill does not require real-image supervision and only adds minimal inference overhead. Extensive experiments show that InverFill consistently boosts baseline few-step models, improving image quality and text coherence without costly retraining or heavy iterative optimization.
IDSelect: A RL-Based Cost-Aware Selection Agent for Video-based Multi-Modal Person Recognition
Feb 22, 2026Video-based person recognition achieves robust identification by integrating face, body, and gait. However, current systems waste computational resources by processing all modalities with fixed heavyweight ensembles regardless of input complexity. To address these limitations, we propose IDSelect, a reinforcement learning-based cost-aware selector that chooses one pre-trained model per modality per-sequence to optimize the accuracy-efficiency trade-off. Our key insight is that an input-conditioned selector can discover complementary model choices that surpass fixed ensembles while using substantially fewer resources. IDSelect trains a lightweight agent end-to-end using actor-critic reinforcement learning with budget-aware optimization. The reward balances recognition accuracy with computational cost, while entropy regularization prevents premature convergence. At inference, the policy selects the most probable model per modality and fuses modality-specific similarities for the final score. Extensive experiments on challenging video-based datasets demonstrate IDSelect's superior efficiency: on CCVID, it achieves 95.9% Rank-1 accuracy with 92.4% less computation than strong baselines while improving accuracy by 1.8%; on MEVID, it reduces computation by 41.3% while maintaining competitive performance.
DIS2: Disentanglement Meets Distillation with Classwise Attention for Robust Remote Sensing Segmentation under Missing Modalities
Jan 20, 2026The efficacy of multimodal learning in remote sensing (RS) is severely undermined by missing modalities. The challenge is exacerbated by the RS highly heterogeneous data and huge scale variation. Consequently, paradigms proven effective in other domains often fail when confronted with these unique data characteristics. Conventional disentanglement learning, which relies on significant feature overlap between modalities (modality-invariant), is insufficient for this heterogeneity. Similarly, knowledge distillation becomes an ill-posed mimicry task where a student fails to focus on the necessary compensatory knowledge, leaving the semantic gap unaddressed. Our work is therefore built upon three pillars uniquely designed for RS: (1) principled missing information compensation, (2) class-specific modality contribution, and (3) multi-resolution feature importance. We propose a novel method DIS2, a new paradigm shifting from modality-shared feature dependence and untargeted imitation to active, guided missing features compensation. Its core novelty lies in a reformulated synergy between disentanglement learning and knowledge distillation, termed DLKD. Compensatory features are explicitly captured which, when fused with the features of the available modality, approximate the ideal fused representation of the full-modality case. To address the class-specific challenge, our Classwise Feature Learning Module (CFLM) adaptively learn discriminative evidence for each target depending on signal availability. Both DLKD and CFLM are supported by a hierarchical hybrid fusion (HF) structure using features across resolutions to strengthen prediction. Extensive experiments validate that our proposed approach significantly outperforms state-of-the-art methods across benchmarks.
AG-VPReID.VIR: Bridging Aerial and Ground Platforms for Video-based Visible-Infrared Person Re-ID
Jul 24, 2025Person re-identification (Re-ID) across visible and infrared modalities is crucial for 24-hour surveillance systems, but existing datasets primarily focus on ground-level perspectives. While ground-based IR systems offer nighttime capabilities, they suffer from occlusions, limited coverage, and vulnerability to obstructions--problems that aerial perspectives uniquely solve. To address these limitations, we introduce AG-VPReID.VIR, the first aerial-ground cross-modality video-based person Re-ID dataset. This dataset captures 1,837 identities across 4,861 tracklets (124,855 frames) using both UAV-mounted and fixed CCTV cameras in RGB and infrared modalities. AG-VPReID.VIR presents unique challenges including cross-viewpoint variations, modality discrepancies, and temporal dynamics. Additionally, we propose TCC-VPReID, a novel three-stream architecture designed to address the joint challenges of cross-platform and cross-modality person Re-ID. Our approach bridges the domain gaps between aerial-ground perspectives and RGB-IR modalities, through style-robust feature learning, memory-based cross-view adaptation, and intermediary-guided temporal modeling. Experiments show that AG-VPReID.VIR presents distinctive challenges compared to existing datasets, with our TCC-VPReID framework achieving significant performance gains across multiple evaluation protocols. Dataset and code are available at https://github.com/agvpreid25/AG-VPReID.VIR.
Mining-Gym: A Configurable RL Benchmarking Environment for Truck Dispatch Scheduling
Mar 24, 2025
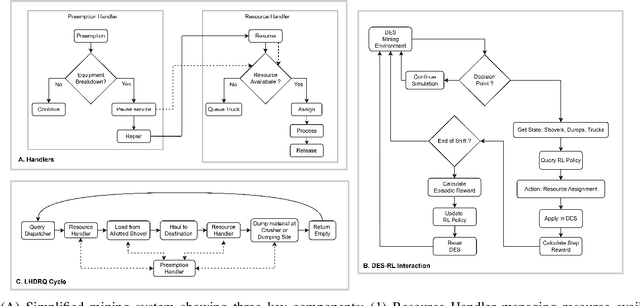


Mining process optimization particularly truck dispatch scheduling is a critical factor in enhancing the efficiency of open pit mining operations However the dynamic and stochastic nature of mining environments characterized by uncertainties such as equipment failures truck maintenance and variable haul cycle times poses significant challenges for traditional optimization methods While Reinforcement Learning RL has shown promise in adaptive decision making for mining logistics its practical deployment requires rigorous evaluation in realistic and customizable simulation environments The lack of standardized benchmarking environments limits fair algorithm comparisons reproducibility and the real world applicability of RL based approaches in open pit mining settings To address this challenge we introduce Mining Gym a configurable open source benchmarking environment designed for training testing and comparing RL algorithms in mining process optimization Built on Discrete Event Simulation DES and seamlessly integrated with the OpenAI Gym interface Mining Gym provides a structured testbed that enables the direct application of advanced RL algorithms from Stable Baselines The framework models key mining specific uncertainties such as equipment failures queue congestion and the stochasticity of mining processes ensuring a realistic and adaptive learning environment Additionally Mining Gym features a graphical user interface GUI for intuitive mine site configuration a comprehensive data logging system a built in KPI dashboard and real time visual representation of the mine site These capabilities facilitate standardized reproducible evaluations across multiple RL strategies and baseline heuristics
AG-VPReID: A Challenging Large-Scale Benchmark for Aerial-Ground Video-based Person Re-Identification
Mar 11, 2025We introduce AG-VPReID, a challenging large-scale benchmark dataset for aerial-ground video-based person re-identification (ReID), comprising 6,632 identities, 32,321 tracklets, and 9.6 million frames captured from drones (15-120m altitude), CCTV, and wearable cameras. This dataset presents a real-world benchmark to investigate the robustness of Person ReID approaches against the unique challenges of cross-platform aerial-ground settings. To address these challenges, we propose AG-VPReID-Net, an end-to-end framework combining three complementary streams: (1) an Adapted Temporal-Spatial Stream addressing motion pattern inconsistencies and temporal feature learning, (2) a Normalized Appearance Stream using physics-informed techniques to tackle resolution and appearance changes, and (3) a Multi-Scale Attention Stream handling scale variations across drone altitudes. Our approach integrates complementary visual-semantic information from all streams to generate robust, viewpoint-invariant person representations. Extensive experiments demonstrate that AG-VPReID-Net outperforms state-of-the-art approaches on both our new dataset and other existing video-based ReID benchmarks, showcasing its effectiveness and generalizability. The relatively lower performance of all state-of-the-art approaches, including our proposed approach, on our new dataset highlights its challenging nature. The AG-VPReID dataset, code and models are available at https://github.com/agvpreid25/AG-VPReID-Net.
PINNs for Medical Image Analysis: A Survey
Aug 02, 2024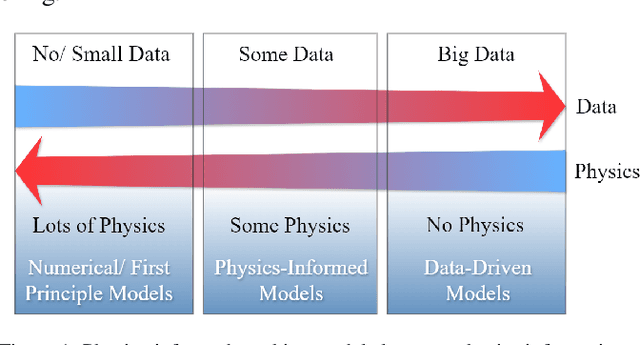

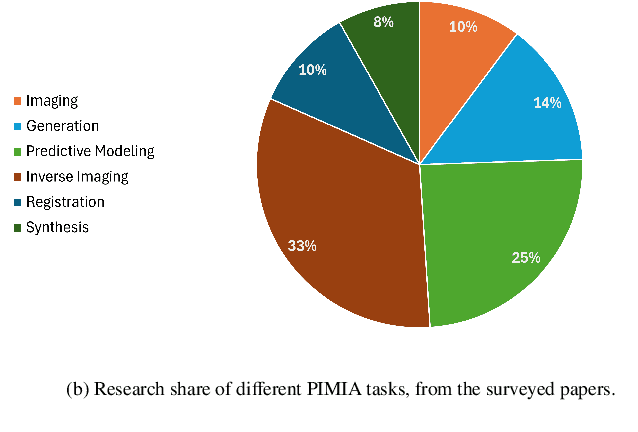

The incorporation of physical information in machine learning frameworks is transforming medical image analysis (MIA). By integrating fundamental knowledge and governing physical laws, these models achieve enhanced robustness and interpretability. In this work, we explore the utility of physics-informed approaches for MIA (PIMIA) tasks such as registration, generation, classification, and reconstruction. We present a systematic literature review of over 80 papers on physics-informed methods dedicated to MIA. We propose a unified taxonomy to investigate what physics knowledge and processes are modelled, how they are represented, and the strategies to incorporate them into MIA models. We delve deep into a wide range of image analysis tasks, from imaging, generation, prediction, inverse imaging (super-resolution and reconstruction), registration, and image analysis (segmentation and classification). For each task, we thoroughly examine and present in a tabular format the central physics-guided operation, the region of interest (with respect to human anatomy), the corresponding imaging modality, the dataset used for model training, the deep network architecture employed, and the primary physical process, equation, or principle utilized. Additionally, we also introduce a novel metric to compare the performance of PIMIA methods across different tasks and datasets. Based on this review, we summarize and distil our perspectives on the challenges, open research questions, and directions for future research. We highlight key open challenges in PIMIA, including selecting suitable physics priors and establishing a standardized benchmarking platform.
Enhancing Semantic Segmentation with Adaptive Focal Loss: A Novel Approach
Jul 13, 2024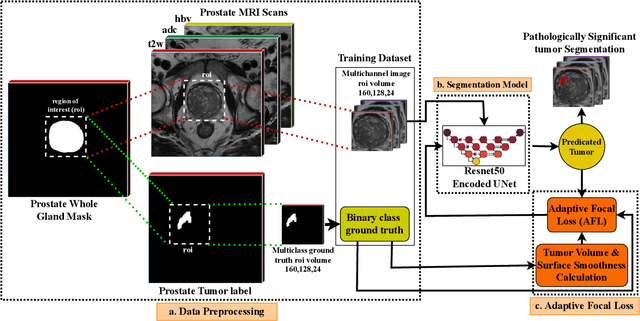



Deep learning has achieved outstanding accuracy in medical image segmentation, particularly for objects like organs or tumors with smooth boundaries or large sizes. Whereas, it encounters significant difficulties with objects that have zigzag boundaries or are small in size, leading to a notable decrease in segmentation effectiveness. In this context, using a loss function that incorporates smoothness and volume information into a model's predictions offers a promising solution to these shortcomings. In this work, we introduce an Adaptive Focal Loss (A-FL) function designed to mitigate class imbalance by down-weighting the loss for easy examples that results in up-weighting the loss for hard examples and giving greater emphasis to challenging examples, such as small and irregularly shaped objects. The proposed A-FL involves dynamically adjusting a focusing parameter based on an object's surface smoothness, size information, and adjusting the class balancing parameter based on the ratio of targeted area to total area in an image. We evaluated the performance of the A-FL using ResNet50-encoded U-Net architecture on the Picai 2022 and BraTS 2018 datasets. On the Picai 2022 dataset, the A-FL achieved an Intersection over Union (IoU) of 0.696 and a Dice Similarity Coefficient (DSC) of 0.769, outperforming the regular Focal Loss (FL) by 5.5% and 5.4% respectively. It also surpassed the best baseline Dice-Focal by 2.0% and 1.2%. On the BraTS 2018 dataset, A-FL achieved an IoU of 0.883 and a DSC of 0.931. The comparative studies show that the proposed A-FL function surpasses conventional methods, including Dice Loss, Focal Loss, and their hybrid variants, in IoU, DSC, Sensitivity, and Specificity metrics. This work highlights A-FL's potential to improve deep learning models for segmenting clinically significant regions in medical images, leading to more precise and reliable diagnostic tools.
AG-ReID.v2: Bridging Aerial and Ground Views for Person Re-identification
Jan 05, 2024



Aerial-ground person re-identification (Re-ID) presents unique challenges in computer vision, stemming from the distinct differences in viewpoints, poses, and resolutions between high-altitude aerial and ground-based cameras. Existing research predominantly focuses on ground-to-ground matching, with aerial matching less explored due to a dearth of comprehensive datasets. To address this, we introduce AG-ReID.v2, a dataset specifically designed for person Re-ID in mixed aerial and ground scenarios. This dataset comprises 100,502 images of 1,615 unique individuals, each annotated with matching IDs and 15 soft attribute labels. Data were collected from diverse perspectives using a UAV, stationary CCTV, and smart glasses-integrated camera, providing a rich variety of intra-identity variations. Additionally, we have developed an explainable attention network tailored for this dataset. This network features a three-stream architecture that efficiently processes pairwise image distances, emphasizes key top-down features, and adapts to variations in appearance due to altitude differences. Comparative evaluations demonstrate the superiority of our approach over existing baselines. We plan to release the dataset and algorithm source code publicly, aiming to advance research in this specialized field of computer vision. For access, please visit https://github.com/huynguyen792/AG-ReID.v2.