 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Illusion of Friendship: Why Generative AI Demands Unprecedented Ethical Vigilance
Jan 12, 2026GenAI systems are increasingly used for drafting, summarisation, and decision support, offering substantial gains in productivity and reduced cognitive load. However, the same natural language fluency that makes these systems useful can also blur the boundary between tool and companion. This boundary confusion may encourage some users to experience GenAI as empathic, benevolent, and relationally persistent. Emerging reports suggest that some users may form emotionally significant attachments to conversational agents, in some cases with harmful consequences, including dependency and impaired judgment. This paper develops a philosophical and ethical argument for why the resulting illusion of friendship is both understandable and can be ethically risky. Drawing on classical accounts of friendship, the paper explains why users may understandably interpret sustained supportive interaction as friend like. It then advances a counterargument that despite relational appearances, GenAI lacks moral agency: consciousness, intention, and accountability and therefore does not qualify as a true friend. To demystify the illusion, the paper presents a mechanism level explanation of how transformer based GenAI generates responses often producing emotionally resonant language without inner states or commitments. Finally, the paper proposes a safeguard framework for safe and responsible GenAI use to reduce possible anthropomorphic cues generated by the GenAI systems. The central contribution is to demystify the illusion of friendship and explain the computational background so that we can shift the emotional attachment with GenAI towards necessary human responsibility and thereby understand how institutions, designers, and users can preserve GenAI's benefits while mitigating over reliance and emotional misattribution.
Mob-based cattle weight gain forecasting using ML models
Sep 16, 2025



Forecasting mob based cattle weight gain (MB CWG) may benefit large livestock farms, allowing farmers to refine their feeding strategies, make educated breeding choices, and reduce risks linked to climate variability and market fluctuations. In this paper, a novel technique termed MB CWG is proposed to forecast the one month advanced weight gain of herd based cattle using historical data collected from the Charles Sturt University Farm. This research employs a Random Forest (RF) model, comparing its performance against Support Vector Regression (SVR) and Long Short Term Memory (LSTM) models for monthly weight gain prediction. Four datasets were used to evaluate the performance of models, using 756 sample data from 108 herd-based cattle, along with weather data (rainfall and temperature) influencing CWG. The RF model performs better than the SVR and LSTM models across all datasets, achieving an R^2 of 0.973, RMSE of 0.040, and MAE of 0.033 when both weather and age factors were included. The results indicate that including both weather and age factors significantly improves the accuracy of weight gain predictions, with the RF model outperforming the SVR and LSTM models in all scenarios. These findings demonstrate the potential of RF as a robust tool for forecasting cattle weight gain in variable conditions, highlighting the influence of age and climatic factors on herd based weight trends. This study has also developed an innovative automated pre processing tool to generate a benchmark dataset for MB CWG predictive models. The tool is publicly available on GitHub and can assist in preparing datasets for current and future analytical research..
Machine Learning-Based Detection and Analysis of Suspicious Activities in Bitcoin Wallet Transactions in the USA
Apr 04, 2025



The dramatic adoption of Bitcoin and other cryptocurrencies in the USA has revolutionized the financial landscape and provided unprecedented investment and transaction efficiency opportunities. The prime objective of this research project is to develop machine learning algorithms capable of effectively identifying and tracking suspicious activity in Bitcoin wallet transactions. With high-tech analysis, the study aims to create a model with a feature for identifying trends and outliers that can expose illicit activity. The current study specifically focuses on Bitcoin transaction information in America, with a strong emphasis placed on the importance of knowing about the immediate environment in and through which such transactions pass through. The dataset is composed of in-depth Bitcoin wallet transactional information, including important factors such as transaction values, timestamps, network flows, and addresses for wallets. All entries in the dataset expose information about financial transactions between wallets, including received and sent transactions, and such information is significant for analysis and trends that can represent suspicious activity. This study deployed three accredited algorithms, most notably, Logistic Regression, Random Forest, and Support Vector Machines. In retrospect, Random Forest emerged as the best model with the highest F1 Score, showcasing its ability to handle non-linear relationships in the data. Insights revealed significant patterns in wallet activity, such as the correlation between unredeemed transactions and final balances. The application of machine algorithms in tracking cryptocurrencies is a tool for creating transparent and secure U.S. markets.
Learning-based estimation of cattle weight gain and its influencing factors
Feb 10, 2025



Many cattle farmers still depend on manual methods to measure the live weight gain of cattle at set intervals, which is time consuming, labour intensive, and stressful for both the animals and handlers. A remote and autonomous monitoring system using machine learning (ML) or deep learning (DL) can provide a more efficient and less invasive method and also predictive capabilities for future cattle weight gain (CWG). This system allows continuous monitoring and estimation of individual cattle live weight gain, growth rates and weight fluctuations considering various factors like environmental conditions, genetic predispositions, feed availability, movement patterns and behaviour. Several researchers have explored the efficiency of estimating CWG using ML and DL algorithms. However, estimating CWG suffers from a lack of consistency in its application. Moreover, ML or DL can provide weight gain estimations based on several features that vary in existing research. Additionally, previous studies have encountered various data related challenges when estimating CWG. This paper presents a comprehensive investigation in estimating CWG using advanced ML techniques based on research articles (between 2004 and 2024). This study investigates the current tools, methods, and features used in CWG estimation, as well as their strengths and weaknesses. The findings highlight the significance of using advanced ML approaches in CWG estimation and its critical influence on factors. Furthermore, this study identifies potential research gaps and provides research direction on CWG prediction, which serves as a reference for future research in this area.
CL3: A Collaborative Learning Framework for the Medical Data Ensuring Data Privacy in the Hyperconnected Environment
Oct 10, 2024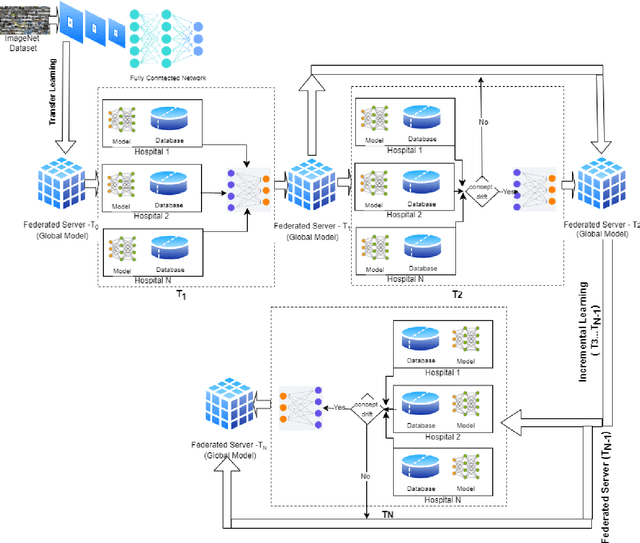
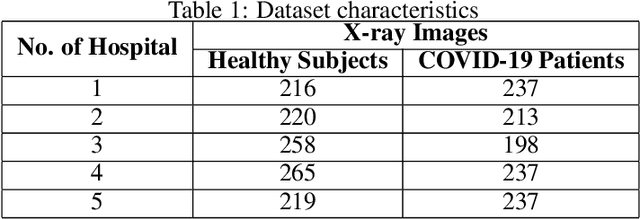

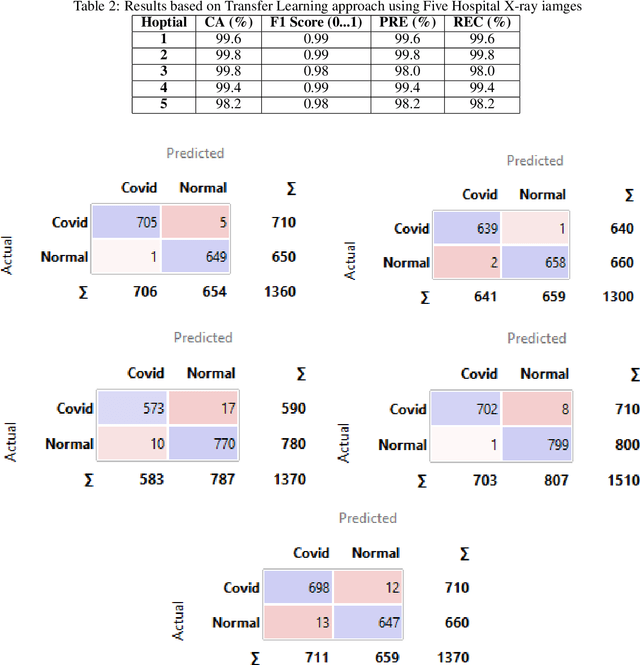
In a hyperconnected environment, medical institutions are particularly concerned with data privacy when sharing and transmitting sensitive patient information due to the risk of data breaches, where malicious actors could intercept sensitive information. A collaborative learning framework, including transfer, federated, and incremental learning, can generate efficient, secure, and scalable models while requiring less computation, maintaining patient data privacy, and ensuring an up-to-date model. This study aims to address the detection of COVID-19 using chest X-ray images through a proposed collaborative learning framework called CL3. Initially, transfer learning is employed, leveraging knowledge from a pre-trained model as the starting global model. Local models from different medical institutes are then integrated, and a new global model is constructed to adapt to any data drift observed in the local models. Additionally, incremental learning is considered, allowing continuous adaptation to new medical data without forgetting previously learned information. Experimental results demonstrate that the CL3 framework achieved a global accuracy of 89.99\% when using Xception with a batch size of 16 after being trained for six federated communication rounds.
MAPX: An explainable model-agnostic framework for the detection of false information on social media networks
Sep 13, 2024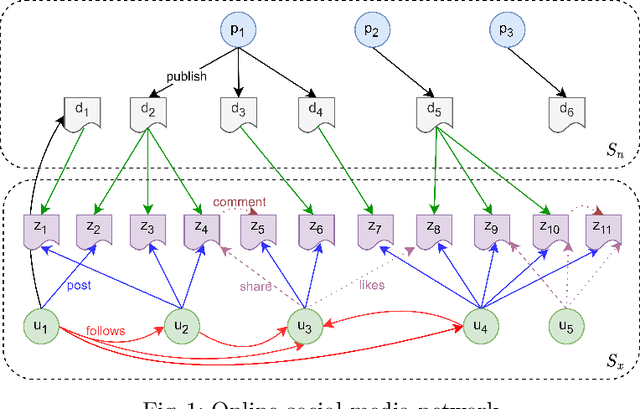



The automated detection of false information has become a fundamental task in combating the spread of "fake news" on online social media networks (OSMN) as it reduces the need for manual discernment by individuals. In the literature, leveraging various content or context features of OSMN documents have been found useful. However, most of the existing detection models often utilise these features in isolation without regard to the temporal and dynamic changes oft-seen in reality, thus, limiting the robustness of the models. Furthermore, there has been little to no consideration of the impact of the quality of documents' features on the trustworthiness of the final prediction. In this paper, we introduce a novel model-agnostic framework, called MAPX, which allows evidence based aggregation of predictions from existing models in an explainable manner. Indeed, the developed aggregation method is adaptive, dynamic and considers the quality of OSMN document features. Further, we perform extensive experiments on benchmarked fake news datasets to demonstrate the effectiveness of MAPX using various real-world data quality scenarios. Our empirical results show that the proposed framework consistently outperforms all state-of-the-art models evaluated. For reproducibility, a demo of MAPX is available at \href{https://github.com/SCondran/MAPX_framework}{this link}
Enhancing Semantic Segmentation with Adaptive Focal Loss: A Novel Approach
Jul 13, 2024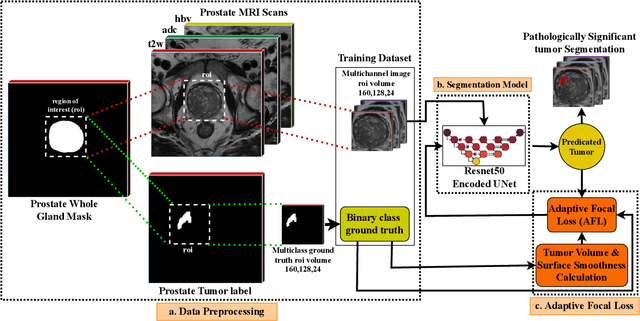



Deep learning has achieved outstanding accuracy in medical image segmentation, particularly for objects like organs or tumors with smooth boundaries or large sizes. Whereas, it encounters significant difficulties with objects that have zigzag boundaries or are small in size, leading to a notable decrease in segmentation effectiveness. In this context, using a loss function that incorporates smoothness and volume information into a model's predictions offers a promising solution to these shortcomings. In this work, we introduce an Adaptive Focal Loss (A-FL) function designed to mitigate class imbalance by down-weighting the loss for easy examples that results in up-weighting the loss for hard examples and giving greater emphasis to challenging examples, such as small and irregularly shaped objects. The proposed A-FL involves dynamically adjusting a focusing parameter based on an object's surface smoothness, size information, and adjusting the class balancing parameter based on the ratio of targeted area to total area in an image. We evaluated the performance of the A-FL using ResNet50-encoded U-Net architecture on the Picai 2022 and BraTS 2018 datasets. On the Picai 2022 dataset, the A-FL achieved an Intersection over Union (IoU) of 0.696 and a Dice Similarity Coefficient (DSC) of 0.769, outperforming the regular Focal Loss (FL) by 5.5% and 5.4% respectively. It also surpassed the best baseline Dice-Focal by 2.0% and 1.2%. On the BraTS 2018 dataset, A-FL achieved an IoU of 0.883 and a DSC of 0.931. The comparative studies show that the proposed A-FL function surpasses conventional methods, including Dice Loss, Focal Loss, and their hybrid variants, in IoU, DSC, Sensitivity, and Specificity metrics. This work highlights A-FL's potential to improve deep learning models for segmenting clinically significant regions in medical images, leading to more precise and reliable diagnostic tools.
Seizure detection from Electroencephalogram signals via Wavelets and Graph Theory metrics
Nov 28, 2023Epilepsy is one of the most prevalent neurological conditions, where an epileptic seizure is a transient occurrence due to abnormal, excessive and synchronous activity in the brain. Electroencephalogram signals emanating from the brain may be captured, analysed and then play a significant role in detection and prediction of epileptic seizures. In this work we enhance upon a previous approach that relied on the differing properties of the wavelet transform. Here we apply the Maximum Overlap Discrete Wavelet Transform to both reduce signal \textit{noise} and use signal variance exhibited at differing inherent frequency levels to develop various metrics of connection between the electrodes placed upon the scalp. %The properties of both the noise reduced signal and the interconnected electrodes differ significantly during the different brain states. Using short duration epochs, to approximate close to real time monitoring, together with simple statistical parameters derived from the reconstructed noise reduced signals we initiate seizure detection. To further improve performance we utilise graph theoretic indicators from derived electrode connectivity. From there we build the attribute space. We utilise open-source software and publicly available data to highlight the superior Recall/Sensitivity performance of our approach, when compared to existing published methods.
Enhancing Cluster Quality of Numerical Datasets with Domain Ontology
Apr 02, 2023



Ontology-based clustering has gained attention in recent years due to the potential benefits of ontology. Current ontology-based clustering approaches have mainly been applied to reduce the dimensionality of attributes in text document clustering. Reduction in dimensionality of attributes using ontology helps to produce high quality clusters for a dataset. However, ontology-based approaches in clustering numerical datasets have not been gained enough attention. Moreover, some literature mentions that ontology-based clustering can produce either high quality or low-quality clusters from a dataset. Therefore, in this paper we present a clustering approach that is based on domain ontology to reduce the dimensionality of attributes in a numerical dataset using domain ontology and to produce high quality clusters. For every dataset, we produce three datasets using domain ontology. We then cluster these datasets using a genetic algorithm-based clustering technique called GenClust++. The clusters of each dataset are evaluated in terms of Sum of Squared-Error (SSE). We use six numerical datasets to evaluate the performance of our ontology-based approach. The experimental results of our approach indicate that cluster quality gradually improves from lower to the higher levels of a domain ontology.
EEG Signal Processing using Wavelets for Accurate Seizure Detection through Cost Sensitive Data Mining
Sep 22, 2021

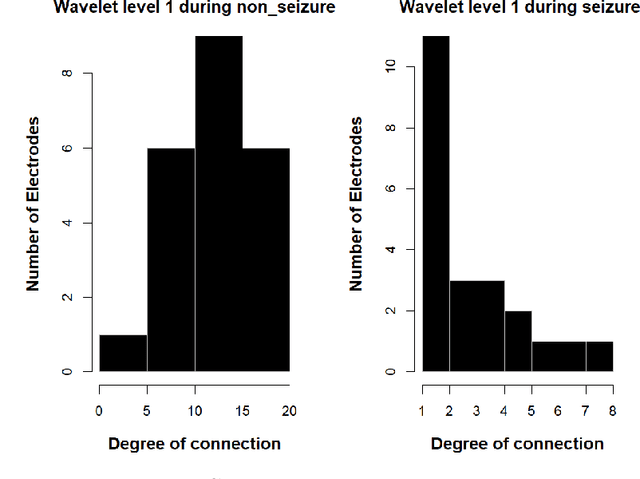
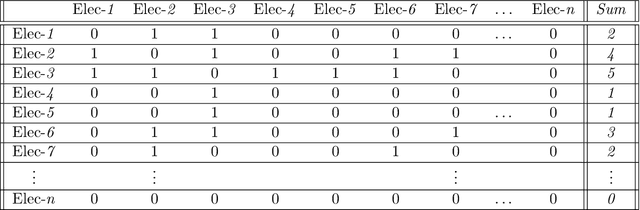
Epilepsy is one of the most common and yet diverse set of chronic neurological disorders. This excessive or synchronous neuronal activity is termed seizure. Electroencephalogram signal processing plays a significant role in detection and prediction of epileptic seizures. In this paper we introduce an approach that relies upon the properties of wavelets for seizure detection. We utilise the Maximum Overlap Discrete Wavelet Transform which enables us to reduce signal noise Then from the variance exhibited in wavelet coefficients we develop connectivity and communication efficiency between the electrodes as these properties differ significantly during a seizure period in comparison to a non-seizure period. We use basic statistical parameters derived from the reconstructed noise reduced signal, electrode connectivity and the efficiency of information transfer to build the attribute space. We have utilised data that are publicly available to test our method that is found to be significantly better than some existing approaches.