 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning and Deploying AI Models for Sustainable Logistics Optimization: A Case Study on Eco-Efficient Supply Chains in the USA
Mar 18, 2025



The rapid evolution of Artificial Intelligence (AI) and Machine Learning (ML) has significantly transformed logistics and supply chain management, particularly in the pursuit of sustainability and eco-efficiency. This study explores AI-based methodologies for optimizing logistics operations in the USA, focusing on reducing environmental impact, improving fuel efficiency, and minimizing costs. Key AI applications include predictive analytics for demand forecasting, route optimization through machine learning, and AI-powered fuel efficiency strategies. Various models, such as Linear Regression, XGBoost, Support Vector Machine, and Neural Networks, are applied to real-world logistics datasets to reduce carbon emissions based on logistics operations, optimize travel routes to minimize distance and travel time, and predict future deliveries to plan optimal routes. Other models such as K-Means and DBSCAN are also used to optimize travel routes to minimize distance and travel time for logistics operations. This study utilizes datasets from logistics companies' databases. The study also assesses model performance using metrics such as mean absolute error (MAE), mean squared error (MSE), and R2 score. This study also explores how these models can be deployed to various platforms for real-time logistics and supply chain use. The models are also examined through a thorough case study, highlighting best practices and regulatory frameworks that promote sustainability. The findings demonstrate AI's potential to enhance logistics efficiency, reduce carbon footprints, and contribute to a more resilient and adaptive supply chain ecosystem.
Enhancing Cluster Quality of Numerical Datasets with Domain Ontology
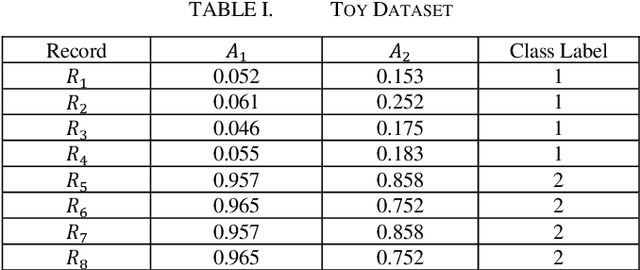
Apr 02, 2023Ontology-based clustering has gained attention in recent years due to the potential benefits of ontology. Current ontology-based clustering approaches have mainly been applied to reduce the dimensionality of attributes in text document clustering. Reduction in dimensionality of attributes using ontology helps to produce high quality clusters for a dataset. However, ontology-based approaches in clustering numerical datasets have not been gained enough attention. Moreover, some literature mentions that ontology-based clustering can produce either high quality or low-quality clusters from a dataset. Therefore, in this paper we present a clustering approach that is based on domain ontology to reduce the dimensionality of attributes in a numerical dataset using domain ontology and to produce high quality clusters. For every dataset, we produce three datasets using domain ontology. We then cluster these datasets using a genetic algorithm-based clustering technique called GenClust++. The clusters of each dataset are evaluated in terms of Sum of Squared-Error (SSE). We use six numerical datasets to evaluate the performance of our ontology-based approach. The experimental results of our approach indicate that cluster quality gradually improves from lower to the higher levels of a domain ontology.
A Novel Incremental Clustering Technique with Concept Drift Detection
Mar 30, 2020


Data are being collected from various aspects of life. These data can often arrive in chunks/batches. Traditional static clustering algorithms are not suitable for dynamic datasets, i.e., when data arrive in streams of chunks/batches. If we apply a conventional clustering technique over the combined dataset, then every time a new batch of data comes, the process can be slow and wasteful. Moreover, it can be challenging to store the combined dataset in memory due to its ever-increasing size. As a result, various incremental clustering techniques have been proposed. These techniques need to efficiently update the current clustering result whenever a new batch arrives, to adapt the current clustering result/solution with the latest data. These techniques also need the ability to detect concept drifts when the clustering pattern of a new batch is significantly different from older batches. Sometimes, clustering patterns may drift temporarily in a single batch while the next batches do not exhibit the drift. Therefore, incremental clustering techniques need the ability to detect a temporary drift and sustained drift. In this paper, we propose an efficient incremental clustering algorithm called UIClust. It is designed to cluster streams of data chunks, even when there are temporary or sustained concept drifts. We evaluate the performance of UIClust by comparing it with a recently published, high-quality incremental clustering algorithm. We use real and synthetic datasets. We compare the results by using well-known clustering evaluation criteria: entropy, sum of squared errors (SSE), and execution time. Our results show that UIClust outperforms the existing technique in all our experiments.