 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Incremental Clustering Technique with Concept Drift Detection
Mar 30, 2020


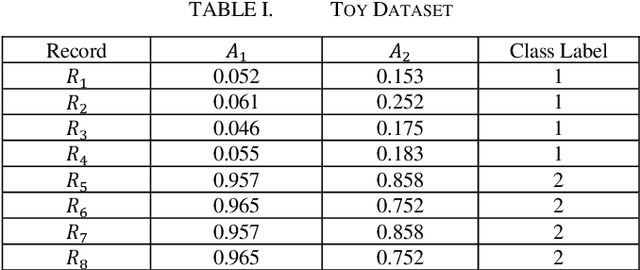
Data are being collected from various aspects of life. These data can often arrive in chunks/batches. Traditional static clustering algorithms are not suitable for dynamic datasets, i.e., when data arrive in streams of chunks/batches. If we apply a conventional clustering technique over the combined dataset, then every time a new batch of data comes, the process can be slow and wasteful. Moreover, it can be challenging to store the combined dataset in memory due to its ever-increasing size. As a result, various incremental clustering techniques have been proposed. These techniques need to efficiently update the current clustering result whenever a new batch arrives, to adapt the current clustering result/solution with the latest data. These techniques also need the ability to detect concept drifts when the clustering pattern of a new batch is significantly different from older batches. Sometimes, clustering patterns may drift temporarily in a single batch while the next batches do not exhibit the drift. Therefore, incremental clustering techniques need the ability to detect a temporary drift and sustained drift. In this paper, we propose an efficient incremental clustering algorithm called UIClust. It is designed to cluster streams of data chunks, even when there are temporary or sustained concept drifts. We evaluate the performance of UIClust by comparing it with a recently published, high-quality incremental clustering algorithm. We use real and synthetic datasets. We compare the results by using well-known clustering evaluation criteria: entropy, sum of squared errors (SSE), and execution time. Our results show that UIClust outperforms the existing technique in all our experiments.