 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sparse-Attention Deep Learning Model Integrating Heterogeneous Multimodal Features for Parkinson's Disease Severity Profiling
Jan 02, 2026Characterising the heterogeneous presentation of Parkinson's disease (PD) requires integrating biological and clinical markers within a unified predictive framework. While multimodal data provide complementary information, many existing computational models struggle with interpretability, class imbalance, or effective fusion of high-dimensional imaging and tabular clinical features. To address these limitations, we propose the Class-Weighted Sparse-Attention Fusion Network (SAFN), an interpretable deep learning framework for robust multimodal profiling. SAFN integrates MRI cortical thickness, MRI volumetric measures, clinical assessments, and demographic variables using modality-specific encoders and a symmetric cross-attention mechanism that captures nonlinear interactions between imaging and clinical representations. A sparsity-constrained attention-gating fusion layer dynamically prioritises informative modalities, while a class-balanced focal loss (beta = 0.999, gamma = 1.5) mitigates dataset imbalance without synthetic oversampling. Evaluated on 703 participants (570 PD, 133 healthy controls) from the Parkinson's Progression Markers Initiative using subject-wise five-fold cross-validation, SAFN achieves an accuracy of 0.98 plus or minus 0.02 and a PR-AUC of 1.00 plus or minus 0.00, outperforming established machine learning and deep learning baselines. Interpretability analysis shows a clinically coherent decision process, with approximately 60 percent of predictive weight assigned to clinical assessments, consistent with Movement Disorder Society diagnostic principles. SAFN provides a reproducible and transparent multimodal modelling paradigm for computational profiling of neurodegenerative disease.
A Framework for Supervised Heterogeneous Transfer Learning using Dynamic Distribution Adaptation and Manifold Regularization
Aug 27, 2021



Transfer learning aims to learn classifiers for a target domain by transferring knowledge from a source domain. However, due to two main issues: feature discrepancy and distribution divergence, transfer learning can be a very difficult problem in practice. In this paper, we present a framework called TLF that builds a classifier for the target domain having only few labeled training records by transferring knowledge from the source domain having many labeled records. While existing methods often focus on one issue and leave the other one for the further work, TLF is capable of handling both issues simultaneously. In TLF, we alleviate feature discrepancy by identifying shared label distributions that act as the pivots to bridge the domains. We handle distribution divergence by simultaneously optimizing the structural risk functional, joint distributions between domains, and the manifold consistency underlying marginal distributions. Moreover, for the manifold consistency we exploit its intrinsic properties by identifying k nearest neighbors of a record, where the value of k is determined automatically in TLF. Furthermore, since negative transfer is not desired, we consider only the source records that are belonging to the source pivots during the knowledge transfer. We evaluate TLF on seven publicly available natural datasets and compare the performance of TLF against the performance of eleven state-of-the-art techniques. We also evaluate the effectiveness of TLF in some challenging situations. Our experimental results, including statistical sign test and Nemenyi test analyses, indicate a clear superiority of the proposed framework over the state-of-the-art techniques.
Adaptive Decision Forest: An Incremental Machine Learning Framework
Jan 28, 2021
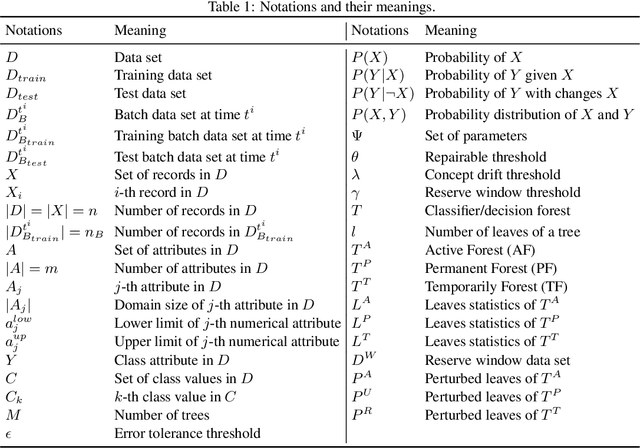


In this study, we present an incremental machine learning framework called Adaptive Decision Forest (ADF), which produces a decision forest to classify new records. Based on our two novel theorems, we introduce a new splitting strategy called iSAT, which allows ADF to classify new records even if they are associated with previously unseen classes. ADF is capable of identifying and handling concept drift; it, however, does not forget previously gained knowledge. Moreover, ADF is capable of handling big data if the data can be divided into batches. We evaluate ADF on five publicly available natural data sets and one synthetic data set, and compare the performance of ADF against the performance of eight state-of-the-art techniques. Our experimental results, including statistical sign test and Nemenyi test analyses, indicate a clear superiority of the proposed framework over the state-of-the-art techniques.