 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRule-Assisted Attribute Embedding
Jun 10, 2025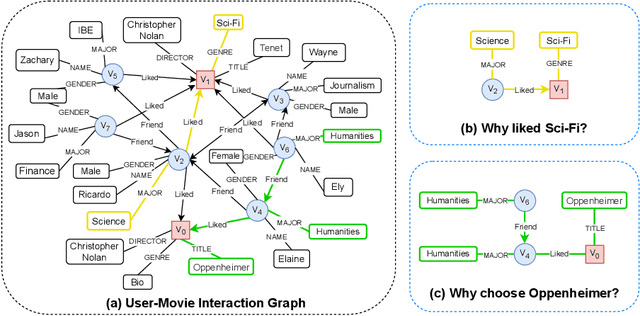
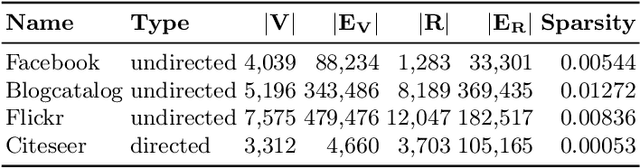
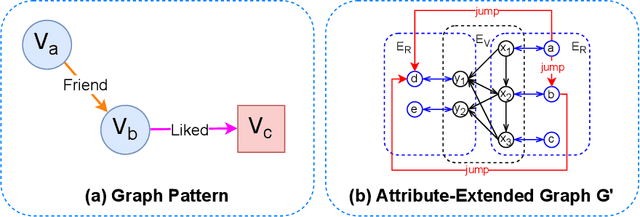
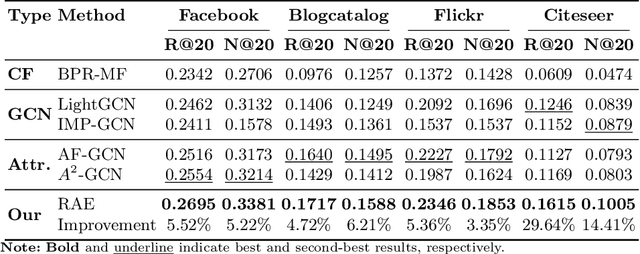
Recommendation systems often overlook the rich attribute information embedded in property graphs, limiting their effectiveness. Existing graph convolutional network (GCN) models either ignore attributes or rely on simplistic <user, item, attribute> triples, failing to capture deeper semantic structures. We propose RAE (Rule- Assisted Approach for Attribute Embedding), a novel method that improves recommendations by mining semantic rules from property graphs to guide attribute embedding. RAE performs rule-based random walks to generate enriched attribute representations, which are integrated into GCNs. Experiments on real-world datasets (BlogCatalog, Flickr) show that RAE outperforms state-of-the-art baselines by 10.6% on average in Recall@20 and NDCG@20. RAE also demonstrates greater robustness to sparse data and missing attributes, highlighting the value of leveraging structured attribute information in recommendation tasks.
RLSA-PFL: Robust Lightweight Secure Aggregation with Model Inconsistency Detection in Privacy-Preserving Federated Learning
Feb 13, 2025Federated Learning (FL) allows users to collaboratively train a global machine learning model by sharing local model only, without exposing their private data to a central server. This distributed learning is particularly appealing in scenarios where data privacy is crucial, and it has garnered substantial attention from both industry and academia. However, studies have revealed privacy vulnerabilities in FL, where adversaries can potentially infer sensitive information from the shared model parameters. In this paper, we present an efficient masking-based secure aggregation scheme utilizing lightweight cryptographic primitives to mitigate privacy risks. Our scheme offers several advantages over existing methods. First, it requires only a single setup phase for the entire FL training session, significantly reducing communication overhead. Second, it minimizes user-side overhead by eliminating the need for user-to-user interactions, utilizing an intermediate server layer and a lightweight key negotiation method. Third, the scheme is highly resilient to user dropouts, and the users can join at any FL round. Fourth, it can detect and defend against malicious server activities, including recently discovered model inconsistency attacks. Finally, our scheme ensures security in both semi-honest and malicious settings. We provide security analysis to formally prove the robustness of our approach. Furthermore, we implemented an end-to-end prototype of our scheme. We conducted comprehensive experiments and comparisons, which show that it outperforms existing solutions in terms of communication and computation overhead, functionality, and security.
GIG: Graph Data Imputation With Graph Differential Dependencies
Oct 21, 2024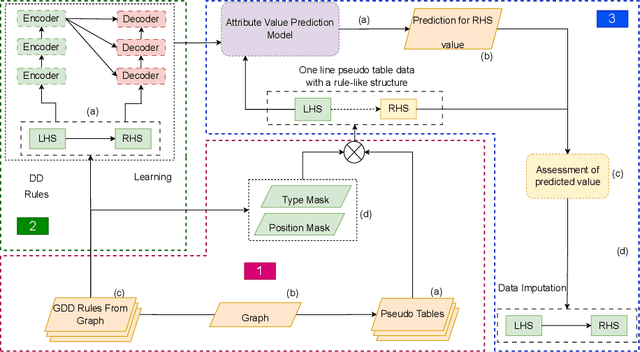

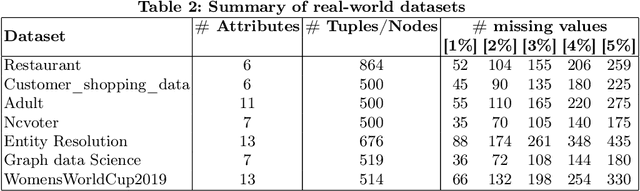
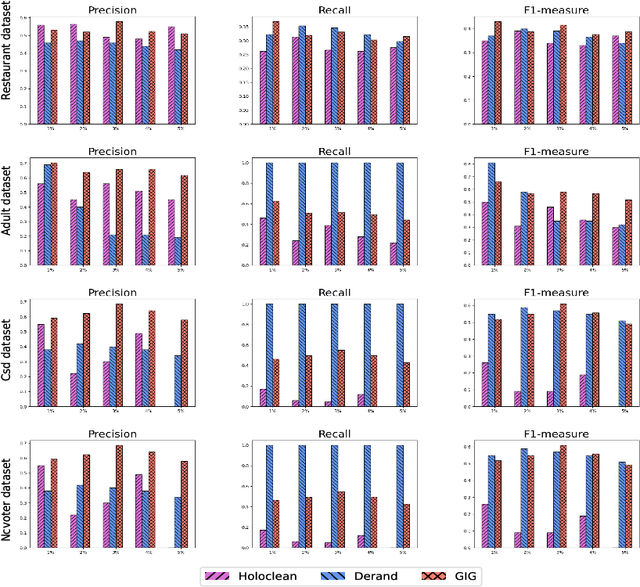
Data imputation addresses the challenge of imputing missing values in database instances, ensuring consistency with the overall semantics of the dataset. Although several heuristics which rely on statistical methods, and ad-hoc rules have been proposed. These do not generalise well and often lack data context. Consequently, they also lack explainability. The existing techniques also mostly focus on the relational data context making them unsuitable for wider application contexts such as in graph data. In this paper, we propose a graph data imputation approach called GIG which relies on graph differential dependencies (GDDs). GIG, learns the GDDs from a given knowledge graph, and uses these rules to train a transformer model which then predicts the value of missing data within the graph. By leveraging GDDs, GIG incoporates semantic knowledge into the data imputation process making it more reliable and explainable. Experimental results on seven real-world datasets highlight GIG's effectiveness compared to existing state-of-the-art approaches.
MAPX: An explainable model-agnostic framework for the detection of false information on social media networks
Sep 13, 2024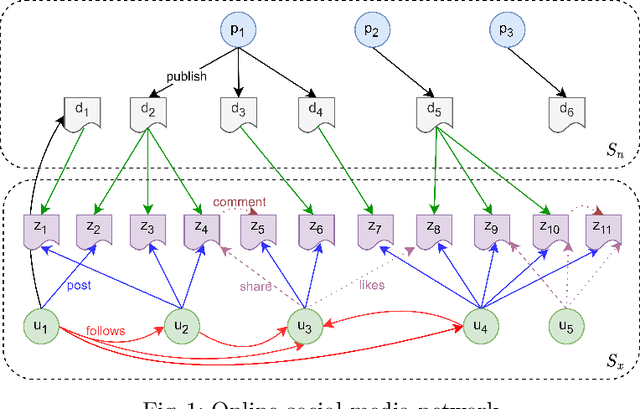



The automated detection of false information has become a fundamental task in combating the spread of "fake news" on online social media networks (OSMN) as it reduces the need for manual discernment by individuals. In the literature, leveraging various content or context features of OSMN documents have been found useful. However, most of the existing detection models often utilise these features in isolation without regard to the temporal and dynamic changes oft-seen in reality, thus, limiting the robustness of the models. Furthermore, there has been little to no consideration of the impact of the quality of documents' features on the trustworthiness of the final prediction. In this paper, we introduce a novel model-agnostic framework, called MAPX, which allows evidence based aggregation of predictions from existing models in an explainable manner. Indeed, the developed aggregation method is adaptive, dynamic and considers the quality of OSMN document features. Further, we perform extensive experiments on benchmarked fake news datasets to demonstrate the effectiveness of MAPX using various real-world data quality scenarios. Our empirical results show that the proposed framework consistently outperforms all state-of-the-art models evaluated. For reproducibility, a demo of MAPX is available at \href{https://github.com/SCondran/MAPX_framework}{this link}
OutCenTR: A novel semi-supervised framework for predicting exploits of vulnerabilities in high-dimensional datasets
Apr 03, 2023An ever-growing number of vulnerabilities are reported every day. Yet these vulnerabilities are not all the same; Some are more targeted than others. Correctly estimating the likelihood of a vulnerability being exploited is a critical task for system administrators. This aids the system administrators in prioritizing and patching the right vulnerabilities. Our work makes use of outlier detection techniques to predict vulnerabilities that are likely to be exploited in highly imbalanced and high-dimensional datasets such as the National Vulnerability Database. We propose a dimensionality reduction technique, OutCenTR, that enhances the baseline outlier detection models. We further demonstrate the effectiveness and efficiency of OutCenTR empirically with 4 benchmark and 12 synthetic datasets. The results of our experiments show on average a 5-fold improvement of F1 score in comparison with state-of-the-art dimensionality reduction techniques such as PCA and GRP.