 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePurify Once, Edit Freely: Breaking Image Protections under Model Mismatch
Mar 13, 2026Diffusion models enable high-fidelity image editing but can also be misused for unauthorized style imitation and harmful content generation. To mitigate these risks, proactive image protection methods embed small, often imperceptible adversarial perturbations into images before sharing to disrupt downstream editing or fine-tuning. However, in realistic post-release scenarios, content owners cannot control downstream processing pipelines, and protections optimized for a surrogate model may fail when attackers use mismatched diffusion pipelines. Existing purification methods can weaken protections but often sacrifice image quality and rarely examine architectural mismatch. We introduce a unified post-release purification framework to evaluate protection survivability under model mismatch. We propose two practical purifiers: VAE-Trans, which corrects protected images via latent-space projection, and EditorClean, which performs instruction-guided reconstruction with a Diffusion Transformer to exploit architectural heterogeneity. Both operate without access to protected images or defense internals. Across 2,100 editing tasks and six representative protection methods, EditorClean consistently restores editability. Compared to protected inputs, it improves PSNR by 3-6 dB and reduces FID by 50-70 percent on downstream edits, while outperforming prior purification baselines by about 2 dB PSNR and 30 percent lower FID. Our results reveal a purify-once, edit-freely failure mode: once purification succeeds, the protective signal is largely removed, enabling unrestricted editing. This highlights the need to evaluate protections under model mismatch and design defenses robust to heterogeneous attackers.
Distillation of Discrete Diffusion by Exact Conditional Distribution Matching
Dec 15, 2025Discrete diffusion models (DDMs) are a powerful class of generative models for categorical data, but they typically require many function evaluations for a single sample, making inference expensive. Existing acceleration methods either rely on approximate simulators, such as $τ$-leaping, or on distillation schemes that train new student models and auxiliary networks with proxy objectives. We propose a simple and principled distillation alternative based on \emph{conditional distribution matching}. Our key observation is that the reverse conditional distribution of clean data given a noisy state, $p_{0\mid t}(x_0 \mid x_t)$, admits a Markov decomposition through intermediate times and can be recovered from marginal density ratios and the known forward CTMC kernel. We exploit this structure to define distillation objectives that directly match conditional distributions between a pre-trained teacher and a low-NFE student, both for one-step and few-step samplers.
On the Reliability of Vision-Language Models Under Adversarial Frequency-Domain Perturbations
Jul 30, 2025Vision-Language Models (VLMs) are increasingly used as perceptual modules for visual content reasoning, including through captioning and DeepFake detection. In this work, we expose a critical vulnerability of VLMs when exposed to subtle, structured perturbations in the frequency domain. Specifically, we highlight how these feature transformations undermine authenticity/DeepFake detection and automated image captioning tasks. We design targeted image transformations, operating in the frequency domain to systematically adjust VLM outputs when exposed to frequency-perturbed real and synthetic images. We demonstrate that the perturbation injection method generalizes across five state-of-the-art VLMs which includes different-parameter Qwen2/2.5 and BLIP models. Experimenting across ten real and generated image datasets reveals that VLM judgments are sensitive to frequency-based cues and may not wholly align with semantic content. Crucially, we show that visually-imperceptible spatial frequency transformations expose the fragility of VLMs deployed for automated image captioning and authenticity detection tasks. Our findings under realistic, black-box constraints challenge the reliability of VLMs, underscoring the need for robust multimodal perception systems.
From Pixels to Trajectory: Universal Adversarial Example Detection via Temporal Imprints
Mar 06, 2025For the first time, we unveil discernible temporal (or historical) trajectory imprints resulting from adversarial example (AE) attacks. Standing in contrast to existing studies all focusing on spatial (or static) imprints within the targeted underlying victim models, we present a fresh temporal paradigm for understanding these attacks. Of paramount discovery is that these imprints are encapsulated within a single loss metric, spanning universally across diverse tasks such as classification and regression, and modalities including image, text, and audio. Recognizing the distinct nature of loss between adversarial and clean examples, we exploit this temporal imprint for AE detection by proposing TRAIT (TRaceable Adversarial temporal trajectory ImprinTs). TRAIT operates under minimal assumptions without prior knowledge of attacks, thereby framing the detection challenge as a one-class classification problem. However, detecting AEs is still challenged by significant overlaps between the constructed synthetic losses of adversarial and clean examples due to the absence of ground truth for incoming inputs. TRAIT addresses this challenge by converting the synthetic loss into a spectrum signature, using the technique of Fast Fourier Transform to highlight the discrepancies, drawing inspiration from the temporal nature of the imprints, analogous to time-series signals. Across 12 AE attacks including SMACK (USENIX Sec'2023), TRAIT demonstrates consistent outstanding performance across comprehensively evaluated modalities, tasks, datasets, and model architectures. In all scenarios, TRAIT achieves an AE detection accuracy exceeding 97%, often around 99%, while maintaining a false rejection rate of 1%. TRAIT remains effective under the formulated strong adaptive attacks.
RLSA-PFL: Robust Lightweight Secure Aggregation with Model Inconsistency Detection in Privacy-Preserving Federated Learning
Feb 13, 2025Federated Learning (FL) allows users to collaboratively train a global machine learning model by sharing local model only, without exposing their private data to a central server. This distributed learning is particularly appealing in scenarios where data privacy is crucial, and it has garnered substantial attention from both industry and academia. However, studies have revealed privacy vulnerabilities in FL, where adversaries can potentially infer sensitive information from the shared model parameters. In this paper, we present an efficient masking-based secure aggregation scheme utilizing lightweight cryptographic primitives to mitigate privacy risks. Our scheme offers several advantages over existing methods. First, it requires only a single setup phase for the entire FL training session, significantly reducing communication overhead. Second, it minimizes user-side overhead by eliminating the need for user-to-user interactions, utilizing an intermediate server layer and a lightweight key negotiation method. Third, the scheme is highly resilient to user dropouts, and the users can join at any FL round. Fourth, it can detect and defend against malicious server activities, including recently discovered model inconsistency attacks. Finally, our scheme ensures security in both semi-honest and malicious settings. We provide security analysis to formally prove the robustness of our approach. Furthermore, we implemented an end-to-end prototype of our scheme. We conducted comprehensive experiments and comparisons, which show that it outperforms existing solutions in terms of communication and computation overhead, functionality, and security.
PoAct: Policy and Action Dual-Control Agent for Generalized Applications
Jan 13, 2025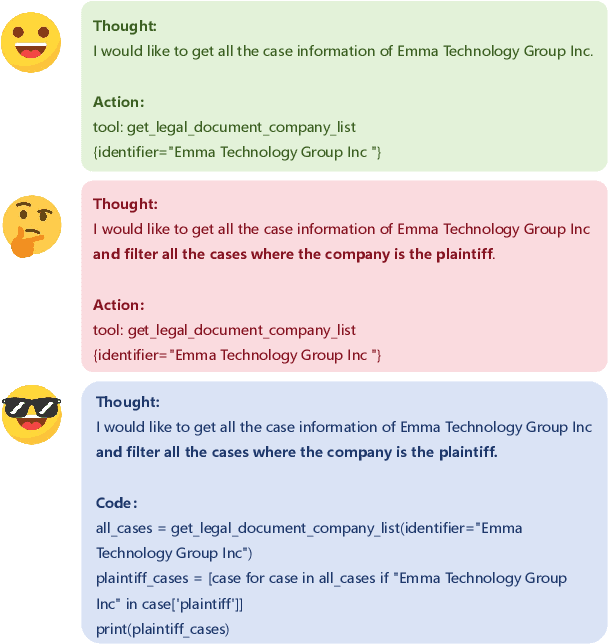



Based on their superior comprehension and reasoning capabilities, Large Language Model (LLM) driven agent frameworks have achieved significant success in numerous complex reasoning tasks. ReAct-like agents can solve various intricate problems step-by-step through progressive planning and tool calls, iteratively optimizing new steps based on environmental feedback. However, as the planning capabilities of LLMs improve, the actions invoked by tool calls in ReAct-like frameworks often misalign with complex planning and challenging data organization. Code Action addresses these issues while also introducing the challenges of a more complex action space and more difficult action organization. To leverage Code Action and tackle the challenges of its complexity, this paper proposes Policy and Action Dual-Control Agent (PoAct) for generalized applications. The aim is to achieve higher-quality code actions and more accurate reasoning paths by dynamically switching reasoning policies and modifying the action space. Experimental results on the Agent Benchmark for both legal and generic scenarios demonstrate the superior reasoning capabilities and reduced token consumption of our approach in complex tasks. On the LegalAgentBench, our method shows a 20 percent improvement over the baseline while requiring fewer tokens. We conducted experiments and analyses on the GPT-4o and GLM-4 series models, demonstrating the significant potential and scalability of our approach to solve complex problems.
Intellectual Property Protection for Deep Learning Model and Dataset Intelligence
Nov 07, 2024
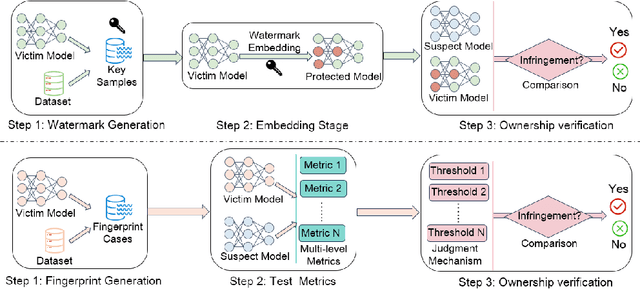


With the growing applications of Deep Learning (DL), especially recent spectacular achievements of Large Language Models (LLMs) such as ChatGPT and LLaMA, the commercial significance of these remarkable models has soared. However, acquiring well-trained models is costly and resource-intensive. It requires a considerable high-quality dataset, substantial investment in dedicated architecture design, expensive computational resources, and efforts to develop technical expertise. Consequently, safeguarding the Intellectual Property (IP) of well-trained models is attracting increasing attention. In contrast to existing surveys overwhelmingly focusing on model IPP mainly, this survey not only encompasses the protection on model level intelligence but also valuable dataset intelligence. Firstly, according to the requirements for effective IPP design, this work systematically summarizes the general and scheme-specific performance evaluation metrics. Secondly, from proactive IP infringement prevention and reactive IP ownership verification perspectives, it comprehensively investigates and analyzes the existing IPP methods for both dataset and model intelligence. Additionally, from the standpoint of training settings, it delves into the unique challenges that distributed settings pose to IPP compared to centralized settings. Furthermore, this work examines various attacks faced by deep IPP techniques. Finally, we outline prospects for promising future directions that may act as a guide for innovative research.
Robustness and Security Enhancement of Radio Frequency Fingerprint Identification in Time-Varying Channels
Oct 10, 2024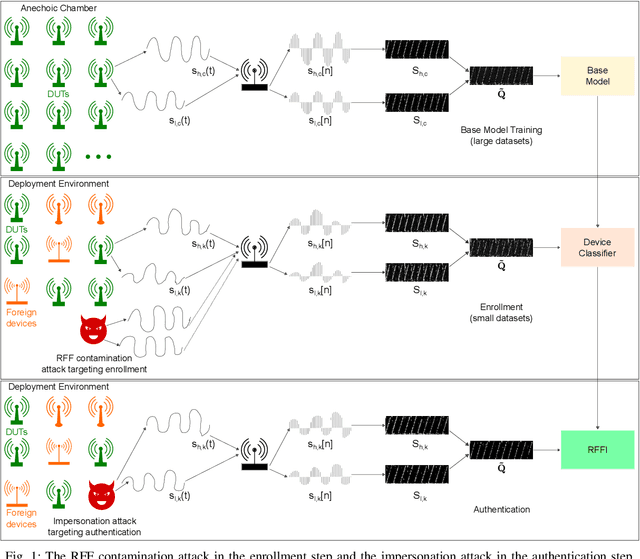



Radio frequency fingerprint identification (RFFI) is becoming increasingly popular, especially in applications with constrained power, such as the Internet of Things (IoT). Due to subtle manufacturing variations, wireless devices have unique radio frequency fingerprints (RFFs). These RFFs can be used with pattern recognition algorithms to classify wireless devices. However, Implementing reliable RFFI in time-varying channels is challenging because RFFs are often distorted by channel effects, reducing the classification accuracy. This paper introduces a new channel-robust RFF, and leverages transfer learning to enhance RFFI in the time-varying channels. Experimental results show that the proposed RFFI system achieved an average classification accuracy improvement of 33.3 % in indoor environments and 34.5 % in outdoor environments. This paper also analyzes the security of the proposed RFFI system to address the security flaw in formalized impersonation attacks. Since RFF collection is being carried out in uncontrolled deployment environments, RFFI systems can be targeted with false RFFs sent by rogue devices. The resulting classifiers may classify the rogue devices as legitimate, effectively replacing their true identities. To defend against impersonation attacks, a novel keyless countermeasure is proposed, which exploits the intrinsic output of the softmax function after classifier training without sacrificing the lightweight nature of RFFI. Experimental results demonstrate an average increase of 0.3 in the area under the receiver operating characteristic curve (AUC), with a 40.0 % improvement in attack detection rate in indoor and outdoor environments.
Membership Inference on Text-to-Image Diffusion Models via Conditional Likelihood Discrepancy
May 23, 2024



Text-to-image diffusion models have achieved tremendous success in the field of controllable image generation, while also coming along with issues of privacy leakage and data copyrights. Membership inference arises in these contexts as a potential auditing method for detecting unauthorized data usage. While some efforts have been made on diffusion models, they are not applicable to text-to-image diffusion models due to the high computation overhead and enhanced generalization capabilities. In this paper, we first identify a conditional overfitting phenomenon in text-to-image diffusion models, indicating that these models tend to overfit the conditional distribution of images given the text rather than the marginal distribution of images. Based on this observation, we derive an analytical indicator, namely Conditional Likelihood Discrepancy (CLiD), to perform membership inference. This indicator reduces the stochasticity in estimating the memorization of individual samples. Experimental results demonstrate that our method significantly outperforms previous methods across various data distributions and scales. Additionally, our method shows superior resistance to overfitting mitigation strategies such as early stopping and data augmentation.
Machine Unlearning: Taxonomy, Metrics, Applications, Challenges, and Prospects
Mar 13, 2024Personal digital data is a critical asset, and governments worldwide have enforced laws and regulations to protect data privacy. Data users have been endowed with the right to be forgotten of their data. In the course of machine learning (ML), the forgotten right requires a model provider to delete user data and its subsequent impact on ML models upon user requests. Machine unlearning emerges to address this, which has garnered ever-increasing attention from both industry and academia. While the area has developed rapidly, there is a lack of comprehensive surveys to capture the latest advancements. Recognizing this shortage, we conduct an extensive exploration to map the landscape of machine unlearning including the (fine-grained) taxonomy of unlearning algorithms under centralized and distributed settings, debate on approximate unlearning, verification and evaluation metrics, challenges and solutions for unlearning under different applications, as well as attacks targeting machine unlearning. The survey concludes by outlining potential directions for future research, hoping to serve as a guide for interested scholars.