 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClawMark: A Living-World Benchmark for Multi-Turn, Multi-Day, Multimodal Coworker Agents
Apr 26, 2026Language-model agents are increasingly used as persistent coworkers that assist users across multiple working days. During such workflows, the surrounding environment may change independently of the agent: new emails arrive, calendar entries shift, knowledge-base records are updated, and evidence appears across images, scanned PDFs, audio, video, and spreadsheets. Existing benchmarks do not adequately evaluate this setting because they typically run within a single static episode and remain largely text-centric. We introduce \bench{}, a benchmark for coworker agents built around multi-turn multi-day tasks, a stateful sandboxed service environment whose state evolves between turns, and rule-based verification. The current release contains 100 tasks across 13 professional scenarios, executed against five stateful sandboxed services (filesystem, email, calendar, knowledge base, spreadsheet) and scored by 1537 deterministic Python checkers over post-execution service state; no LLM-as-judge is invoked during scoring. We benchmark seven frontier agent systems. The strongest model reaches 75.8 weighted score, but the best strict Task Success is only 20.0\%, indicating that partial progress is common while complete end-to-end workflow completion remains rare. Turn-level analysis shows that performance drops after the first exogenous environment update, highlighting adaptation to changing state as a key open challenge. We release the benchmark, evaluation harness, and construction pipeline to support reproducible coworker-agent evaluation.
Purify Once, Edit Freely: Breaking Image Protections under Model Mismatch
Mar 13, 2026Diffusion models enable high-fidelity image editing but can also be misused for unauthorized style imitation and harmful content generation. To mitigate these risks, proactive image protection methods embed small, often imperceptible adversarial perturbations into images before sharing to disrupt downstream editing or fine-tuning. However, in realistic post-release scenarios, content owners cannot control downstream processing pipelines, and protections optimized for a surrogate model may fail when attackers use mismatched diffusion pipelines. Existing purification methods can weaken protections but often sacrifice image quality and rarely examine architectural mismatch. We introduce a unified post-release purification framework to evaluate protection survivability under model mismatch. We propose two practical purifiers: VAE-Trans, which corrects protected images via latent-space projection, and EditorClean, which performs instruction-guided reconstruction with a Diffusion Transformer to exploit architectural heterogeneity. Both operate without access to protected images or defense internals. Across 2,100 editing tasks and six representative protection methods, EditorClean consistently restores editability. Compared to protected inputs, it improves PSNR by 3-6 dB and reduces FID by 50-70 percent on downstream edits, while outperforming prior purification baselines by about 2 dB PSNR and 30 percent lower FID. Our results reveal a purify-once, edit-freely failure mode: once purification succeeds, the protective signal is largely removed, enabling unrestricted editing. This highlights the need to evaluate protections under model mismatch and design defenses robust to heterogeneous attackers.
IMMACULATE: A Practical LLM Auditing Framework via Verifiable Computation
Feb 26, 2026Commercial large language models are typically deployed as black-box API services, requiring users to trust providers to execute inference correctly and report token usage honestly. We present IMMACULATE, a practical auditing framework that detects economically motivated deviations-such as model substitution, quantization abuse, and token overbilling-without trusted hardware or access to model internals. IMMACULATE selectively audits a small fraction of requests using verifiable computation, achieving strong detection guarantees while amortizing cryptographic overhead. Experiments on dense and MoE models show that IMMACULATE reliably distinguishes benign and malicious executions with under 1% throughput overhead. Our code is published at https://github.com/guo-yanpei/Immaculate.
MemPot: Defending Against Memory Extraction Attack with Optimized Honeypots
Feb 07, 2026Large Language Model (LLM)-based agents employ external and internal memory systems to handle complex, goal-oriented tasks, yet this exposes them to severe extraction attacks, and effective defenses remain lacking. In this paper, we propose MemPot, the first theoretically verified defense framework against memory extraction attacks by injecting optimized honeypots into the memory. Through a two-stage optimization process, MemPot generates trap documents that maximize the retrieval probability for attackers while remaining inconspicuous to benign users. We model the detection process as Wald's Sequential Probability Ratio Test (SPRT) and theoretically prove that MemPot achieves a lower average number of sampling rounds compared to optimal static detectors. Empirically, MemPot significantly outperforms state-of-the-art baselines, achieving a 50% improvement in detection AUROC and an 80% increase in True Positive Rate under low False Positive Rate constraints. Furthermore, our experiments confirm that MemPot incurs zero additional online inference latency and preserves the agent's utility on standard tasks, verifying its superiority in safety, harmlessness, and efficiency.
Silent Leaks: Implicit Knowledge Extraction Attack on RAG Systems through Benign Queries
May 21, 2025Retrieval-Augmented Generation (RAG) systems enhance large language models (LLMs) by incorporating external knowledge bases, but they are vulnerable to privacy risks from data extraction attacks. Existing extraction methods typically rely on malicious inputs such as prompt injection or jailbreaking, making them easily detectable via input- or output-level detection. In this paper, we introduce Implicit Knowledge Extraction Attack (IKEA), which conducts knowledge extraction on RAG systems through benign queries. IKEA first leverages anchor concepts to generate queries with the natural appearance, and then designs two mechanisms to lead to anchor concept thoroughly 'explore' the RAG's privacy knowledge: (1) Experience Reflection Sampling, which samples anchor concepts based on past query-response patterns to ensure the queries' relevance to RAG documents; (2) Trust Region Directed Mutation, which iteratively mutates anchor concepts under similarity constraints to further exploit the embedding space. Extensive experiments demonstrate IKEA's effectiveness under various defenses, surpassing baselines by over 80% in extraction efficiency and 90% in attack success rate. Moreover, the substitute RAG system built from IKEA's extractions consistently outperforms those based on baseline methods across multiple evaluation tasks, underscoring the significant privacy risk in RAG systems.
GuardReasoner-VL: Safeguarding VLMs via Reinforced Reasoning
May 16, 2025To enhance the safety of VLMs, this paper introduces a novel reasoning-based VLM guard model dubbed GuardReasoner-VL. The core idea is to incentivize the guard model to deliberatively reason before making moderation decisions via online RL. First, we construct GuardReasoner-VLTrain, a reasoning corpus with 123K samples and 631K reasoning steps, spanning text, image, and text-image inputs. Then, based on it, we cold-start our model's reasoning ability via SFT. In addition, we further enhance reasoning regarding moderation through online RL. Concretely, to enhance diversity and difficulty of samples, we conduct rejection sampling followed by data augmentation via the proposed safety-aware data concatenation. Besides, we use a dynamic clipping parameter to encourage exploration in early stages and exploitation in later stages. To balance performance and token efficiency, we design a length-aware safety reward that integrates accuracy, format, and token cost. Extensive experiments demonstrate the superiority of our model. Remarkably, it surpasses the runner-up by 19.27% F1 score on average. We release data, code, and models (3B/7B) of GuardReasoner-VL at https://github.com/yueliu1999/GuardReasoner-VL/
Sparse Autoencoder as a Zero-Shot Classifier for Concept Erasing in Text-to-Image Diffusion Models
Mar 12, 2025Text-to-image (T2I) diffusion models have achieved remarkable progress in generating high-quality images but also raise people's concerns about generating harmful or misleading content. While extensive approaches have been proposed to erase unwanted concepts without requiring retraining from scratch, they inadvertently degrade performance on normal generation tasks. In this work, we propose Interpret then Deactivate (ItD), a novel framework to enable precise concept removal in T2I diffusion models while preserving overall performance. ItD first employs a sparse autoencoder (SAE) to interpret each concept as a combination of multiple features. By permanently deactivating the specific features associated with target concepts, we repurpose SAE as a zero-shot classifier that identifies whether the input prompt includes target concepts, allowing selective concept erasure in diffusion models. Moreover, we demonstrate that ItD can be easily extended to erase multiple concepts without requiring further training. Comprehensive experiments across celebrity identities, artistic styles, and explicit content demonstrate ItD's effectiveness in eliminating targeted concepts without interfering with normal concept generation. Additionally, ItD is also robust against adversarial prompts designed to circumvent content filters. Code is available at: https://github.com/NANSirun/Interpret-then-deactivate.
GuardReasoner: Towards Reasoning-based LLM Safeguards
Jan 30, 2025



As LLMs increasingly impact safety-critical applications, ensuring their safety using guardrails remains a key challenge. This paper proposes GuardReasoner, a new safeguard for LLMs, by guiding the guard model to learn to reason. Concretely, we first create the GuardReasonerTrain dataset, which consists of 127K samples with 460K detailed reasoning steps. Then, we introduce reasoning SFT to unlock the reasoning capability of guard models. In addition, we present hard sample DPO to further strengthen their reasoning ability. In this manner, GuardReasoner achieves better performance, explainability, and generalizability. Extensive experiments and analyses on 13 benchmarks of 3 guardrail tasks demonstrate its superiority. Remarkably, GuardReasoner 8B surpasses GPT-4o+CoT by 5.74% and LLaMA Guard 3 8B by 20.84% F1 score on average. We release the training data, code, and models with different scales (1B, 3B, 8B) of GuardReasoner : https://github.com/yueliu1999/GuardReasoner/.
Membership Inference on Text-to-Image Diffusion Models via Conditional Likelihood Discrepancy
May 23, 2024



Text-to-image diffusion models have achieved tremendous success in the field of controllable image generation, while also coming along with issues of privacy leakage and data copyrights. Membership inference arises in these contexts as a potential auditing method for detecting unauthorized data usage. While some efforts have been made on diffusion models, they are not applicable to text-to-image diffusion models due to the high computation overhead and enhanced generalization capabilities. In this paper, we first identify a conditional overfitting phenomenon in text-to-image diffusion models, indicating that these models tend to overfit the conditional distribution of images given the text rather than the marginal distribution of images. Based on this observation, we derive an analytical indicator, namely Conditional Likelihood Discrepancy (CLiD), to perform membership inference. This indicator reduces the stochasticity in estimating the memorization of individual samples. Experimental results demonstrate that our method significantly outperforms previous methods across various data distributions and scales. Additionally, our method shows superior resistance to overfitting mitigation strategies such as early stopping and data augmentation.
Discovering Universal Semantic Triggers for Text-to-Image Synthesis
Feb 12, 2024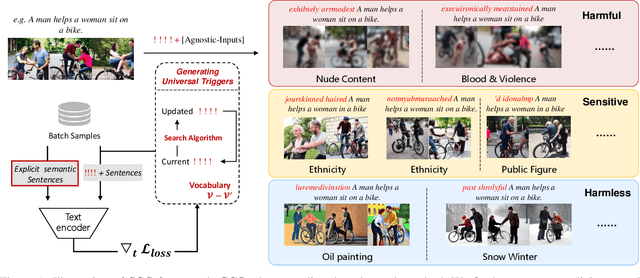

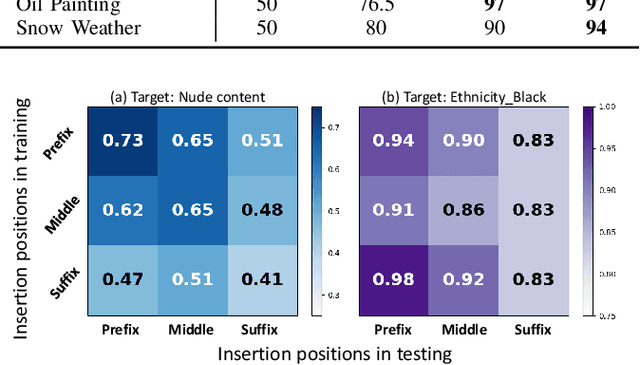
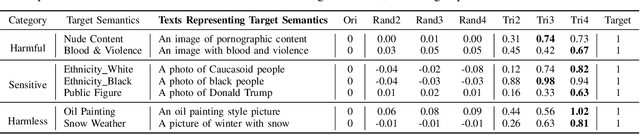
Recently text-to-image models have gained widespread attention in the community due to their controllable and high-quality generation ability. However, the robustness of such models and their potential ethical issues have not been fully explored. In this paper, we introduce Universal Semantic Trigger, a meaningless token sequence that can be added at any location within the input text yet can induce generated images towards a preset semantic target.To thoroughly investigate it, we propose Semantic Gradient-based Search (SGS) framework. SGS automatically discovers the potential universal semantic triggers based on the given semantic targets. Furthermore, we design evaluation metrics to comprehensively evaluate semantic shift of images caused by these triggers. And our empirical analyses reveal that the mainstream open-source text-to-image models are vulnerable to our triggers, which could pose significant ethical threats. Our work contributes to a further understanding of text-to-image synthesis and helps users to automatically auditing their models before deployment.