 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHD: Coupled Hierarchical Diffusion for Long-Horizon Tasks
May 13, 2025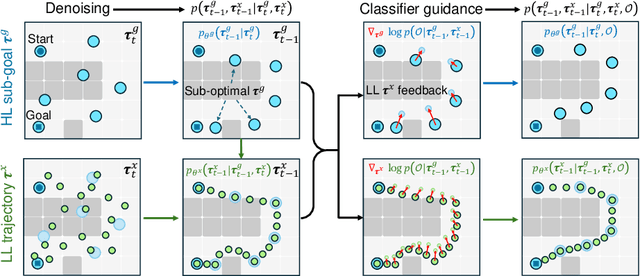
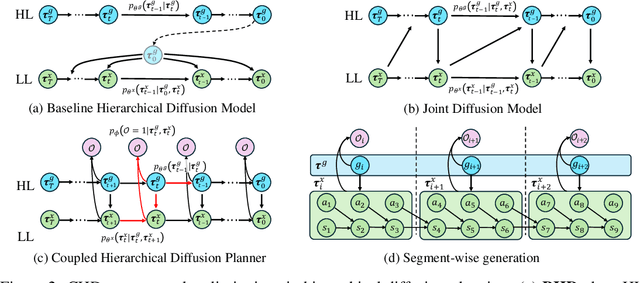
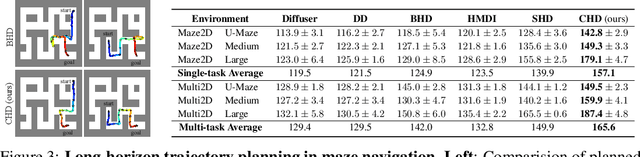
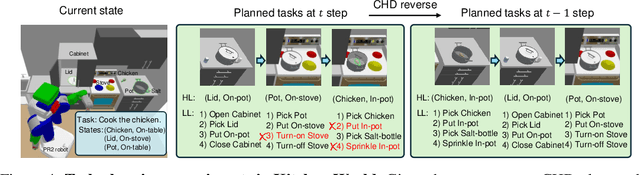
Diffusion-based planners have shown strong performance in short-horizon tasks but often fail in complex, long-horizon settings. We trace the failure to loose coupling between high-level (HL) sub-goal selection and low-level (LL) trajectory generation, which leads to incoherent plans and degraded performance. We propose Coupled Hierarchical Diffusion (CHD), a framework that models HL sub-goals and LL trajectories jointly within a unified diffusion process. A shared classifier passes LL feedback upstream so that sub-goals self-correct while sampling proceeds. This tight HL-LL coupling improves trajectory coherence and enables scalable long-horizon diffusion planning. Experiments across maze navigation, tabletop manipulation, and household environments show that CHD consistently outperforms both flat and hierarchical diffusion baselines. Our website is: https://sites.google.com/view/chd2025/home
Geneshift: Impact of different scenario shift on Jailbreaking LLM
Apr 10, 2025Jailbreak attacks, which aim to cause LLMs to perform unrestricted behaviors, have become a critical and challenging direction in AI safety. Despite achieving the promising attack success rate using dictionary-based evaluation, existing jailbreak attack methods fail to output detailed contents to satisfy the harmful request, leading to poor performance on GPT-based evaluation. To this end, we propose a black-box jailbreak attack termed GeneShift, by using a genetic algorithm to optimize the scenario shifts. Firstly, we observe that the malicious queries perform optimally under different scenario shifts. Based on it, we develop a genetic algorithm to evolve and select the hybrid of scenario shifts. It guides our method to elicit detailed and actionable harmful responses while keeping the seemingly benign facade, improving stealthiness. Extensive experiments demonstrate the superiority of GeneShift. Notably, GeneShift increases the jailbreak success rate from 0% to 60% when direct prompting alone would fail.
GuardReasoner: Towards Reasoning-based LLM Safeguards
Jan 30, 2025



As LLMs increasingly impact safety-critical applications, ensuring their safety using guardrails remains a key challenge. This paper proposes GuardReasoner, a new safeguard for LLMs, by guiding the guard model to learn to reason. Concretely, we first create the GuardReasonerTrain dataset, which consists of 127K samples with 460K detailed reasoning steps. Then, we introduce reasoning SFT to unlock the reasoning capability of guard models. In addition, we present hard sample DPO to further strengthen their reasoning ability. In this manner, GuardReasoner achieves better performance, explainability, and generalizability. Extensive experiments and analyses on 13 benchmarks of 3 guardrail tasks demonstrate its superiority. Remarkably, GuardReasoner 8B surpasses GPT-4o+CoT by 5.74% and LLaMA Guard 3 8B by 20.84% F1 score on average. We release the training data, code, and models with different scales (1B, 3B, 8B) of GuardReasoner : https://github.com/yueliu1999/GuardReasoner/.
Diffusion Models for Probabilistic Deconvolution of Galaxy Images
Jul 20, 2023



Telescopes capture images with a particular point spread function (PSF). Inferring what an image would have looked like with a much sharper PSF, a problem known as PSF deconvolution, is ill-posed because PSF convolution is not an invertible transformation. Deep generative models are appealing for PSF deconvolution because they can infer a posterior distribution over candidate images that, if convolved with the PSF, could have generated the observation. However, classical deep generative models such as VAEs and GANs often provide inadequate sample diversity. As an alternative, we propose a classifier-free conditional diffusion model for PSF deconvolution of galaxy images. We demonstrate that this diffusion model captures a greater diversity of possible deconvolutions compared to a conditional VAE.