 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution-Free Robust Predict-Then-Optimize in Function Spaces
Feb 11, 2026The need to rapidly solve PDEs in engineering design workflows has spurred the rise of neural surrogate models. In particular, neural operator models provide a discretization-invariant surrogate by retaining the infinite-dimensional, functional form of their arguments. Despite improved throughput, such methods lack guarantees on accuracy, unlike classical numerical PDE solvers. Optimizing engineering designs under these potentially miscalibrated surrogates thus runs the risk of producing designs that perform poorly upon deployment. In a similar vein, there is growing interest in automated decision-making under black-box predictors in the finite-dimensional setting, where a similar risk of suboptimality exists under poorly calibrated models. For this reason, methods have emerged that produce adversarially robust decisions under uncertainty estimates of the upstream model. One such framework leverages conformal prediction, a distribution-free post-hoc uncertainty quantification method, to provide these estimates due to its natural pairing with black-box predictors. We herein extend this line of conformally robust decision-making to infinite-dimensional function spaces. We first extend the typical conformal prediction guarantees over finite-dimensional spaces to infinite-dimensional Sobolev spaces. We then demonstrate how such uncertainty can be leveraged to robustly formulate engineering design tasks and characterize the suboptimality of the resulting robust optimal designs. We then empirically demonstrate the generality of our functional conformal coverage method across a diverse collection of PDEs, including the Poisson and heat equations, and showcase the significant improvement of such robust design in a quantum state discrimination task.
Distribution-Free Robust Functional Predict-Then-Optimize
Feb 09, 2026The solution of PDEs in decision-making tasks is increasingly being undertaken with the help of neural operator surrogate models due to the need for repeated evaluation. Such methods, while significantly more computationally favorable compared to their numerical counterparts, fail to provide any calibrated notions of uncertainty in their predictions. Current methods approach this deficiency typically with ensembling or Bayesian posterior estimation. However, these approaches either require distributional assumptions that fail to hold in practice or lack practical scalability, limiting their applications in practice. We, therefore, propose a novel application of conformal prediction to produce distribution-free uncertainty quantification over the function spaces mapped by neural operators. We then demonstrate how such prediction regions enable a formal regret characterization if leveraged in downstream robust decision-making tasks. We further demonstrate how such posited robust decision-making tasks can be efficiently solved using an infinite-dimensional generalization of Danskin's Theorem and calculus of variations and empirically demonstrate the superior performance of our proposed method over more restrictive modeling paradigms, such as Gaussian Processes, across several engineering tasks.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Silencing Empowerment, Allowing Bigotry: Auditing the Moderation of Hate Speech on Twitch
Jun 09, 2025



To meet the demands of content moderation, online platforms have resorted to automated systems. Newer forms of real-time engagement($\textit{e.g.}$, users commenting on live streams) on platforms like Twitch exert additional pressures on the latency expected of such moderation systems. Despite their prevalence, relatively little is known about the effectiveness of these systems. In this paper, we conduct an audit of Twitch's automated moderation tool ($\texttt{AutoMod}$) to investigate its effectiveness in flagging hateful content. For our audit, we create streaming accounts to act as siloed test beds, and interface with the live chat using Twitch's APIs to send over $107,000$ comments collated from $4$ datasets. We measure $\texttt{AutoMod}$'s accuracy in flagging blatantly hateful content containing misogyny, racism, ableism and homophobia. Our experiments reveal that a large fraction of hateful messages, up to $94\%$ on some datasets, $\textit{bypass moderation}$. Contextual addition of slurs to these messages results in $100\%$ removal, revealing $\texttt{AutoMod}$'s reliance on slurs as a moderation signal. We also find that contrary to Twitch's community guidelines, $\texttt{AutoMod}$ blocks up to $89.5\%$ of benign examples that use sensitive words in pedagogical or empowering contexts. Overall, our audit points to large gaps in $\texttt{AutoMod}$'s capabilities and underscores the importance for such systems to understand context effectively.
Operator Learning for Schrödinger Equation: Unitarity, Error Bounds, and Time Generalization
May 23, 2025We consider the problem of learning the evolution operator for the time-dependent Schr\"{o}dinger equation, where the Hamiltonian may vary with time. Existing neural network-based surrogates often ignore fundamental properties of the Schr\"{o}dinger equation, such as linearity and unitarity, and lack theoretical guarantees on prediction error or time generalization. To address this, we introduce a linear estimator for the evolution operator that preserves a weak form of unitarity. We establish both upper and lower bounds on the prediction error that hold uniformly over all sufficiently smooth initial wave functions. Additionally, we derive time generalization bounds that quantify how the estimator extrapolates beyond the time points seen during training. Experiments across real-world Hamiltonians -- including hydrogen atoms, ion traps for qubit design, and optical lattices -- show that our estimator achieves relative errors $10^{-2}$ to $10^{-3}$ times smaller than state-of-the-art methods such as the Fourier Neural Operator and DeepONet.
Continuum Transformers Perform In-Context Learning by Operator Gradient Descent
May 23, 2025Transformers robustly exhibit the ability to perform in-context learning, whereby their predictive accuracy on a task can increase not by parameter updates but merely with the placement of training samples in their context windows. Recent works have shown that transformers achieve this by implementing gradient descent in their forward passes. Such results, however, are restricted to standard transformer architectures, which handle finite-dimensional inputs. In the space of PDE surrogate modeling, a generalization of transformers to handle infinite-dimensional function inputs, known as "continuum transformers," has been proposed and similarly observed to exhibit in-context learning. Despite impressive empirical performance, such in-context learning has yet to be theoretically characterized. We herein demonstrate that continuum transformers perform in-context operator learning by performing gradient descent in an operator RKHS. We demonstrate this using novel proof strategies that leverage a generalized representer theorem for Hilbert spaces and gradient flows over the space of functionals of a Hilbert space. We additionally show the operator learned in context is the Bayes Optimal Predictor in the infinite depth limit of the transformer. We then provide empirical validations of this optimality result and demonstrate that the parameters under which such gradient descent is performed are recovered through the continuum transformer training.
Three Things to Know about Deep Metric Learning
Dec 17, 2024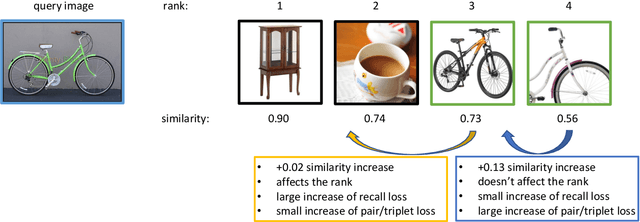
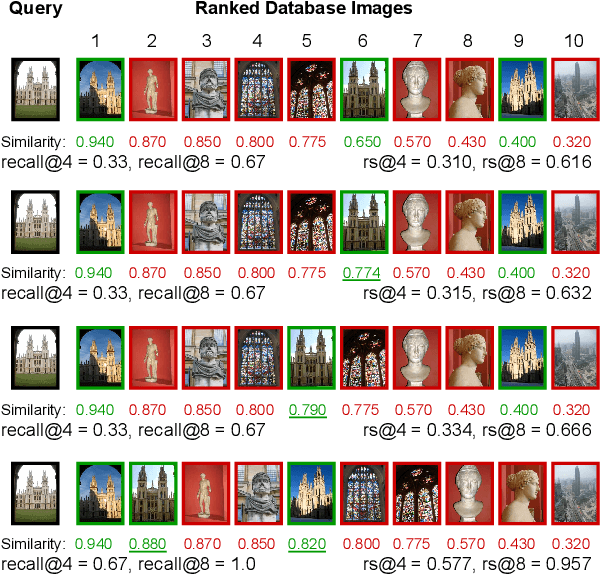

This paper addresses supervised deep metric learning for open-set image retrieval, focusing on three key aspects: the loss function, mixup regularization, and model initialization. In deep metric learning, optimizing the retrieval evaluation metric, recall@k, via gradient descent is desirable but challenging due to its non-differentiable nature. To overcome this, we propose a differentiable surrogate loss that is computed on large batches, nearly equivalent to the entire training set. This computationally intensive process is made feasible through an implementation that bypasses the GPU memory limitations. Additionally, we introduce an efficient mixup regularization technique that operates on pairwise scalar similarities, effectively increasing the batch size even further. The training process is further enhanced by initializing the vision encoder using foundational models, which are pre-trained on large-scale datasets. Through a systematic study of these components, we demonstrate that their synergy enables large models to nearly solve popular benchmarks.
Wound Tissue Segmentation in Diabetic Foot Ulcer Images Using Deep Learning: A Pilot Study
Jun 23, 2024Identifying individual tissues, so-called tissue segmentation, in diabetic foot ulcer (DFU) images is a challenging task and little work has been published, largely due to the limited availability of a clinical image dataset. To address this gap, we have created a DFUTissue dataset for the research community to evaluate wound tissue segmentation algorithms. The dataset contains 110 images with tissues labeled by wound experts and 600 unlabeled images. Additionally, we conducted a pilot study on segmenting wound characteristics including fibrin, granulation, and callus using deep learning. Due to the limited amount of annotated data, our framework consists of both supervised learning (SL) and semi-supervised learning (SSL) phases. In the SL phase, we propose a hybrid model featuring a Mix Transformer (MiT-b3) in the encoder and a CNN in the decoder, enhanced by the integration of a parallel spatial and channel squeeze-and-excitation (P-scSE) module known for its efficacy in improving boundary accuracy. The SSL phase employs a pseudo-labeling-based approach, iteratively identifying and incorporating valuable unlabeled images to enhance overall segmentation performance. Comparative evaluations with state-of-the-art methods are conducted for both SL and SSL phases. The SL achieves a Dice Similarity Coefficient (DSC) of 84.89%, which has been improved to 87.64% in the SSL phase. Furthermore, the results are benchmarked against two widely used SSL approaches: Generative Adversarial Networks and Cross-Consistency Training. Additionally, our hybrid model outperforms the state-of-the-art methods with a 92.99% DSC in performing binary segmentation of DFU wound areas when tested on the Chronic Wound dataset. Codes and data are available at https://github.com/uwm-bigdata/DFUTissueSegNet.
Conformalized Late Fusion Multi-View Learning
May 25, 2024



Uncertainty quantification for multi-view learning is motivated by the increasing use of multi-view data in scientific problems. A common variant of multi-view learning is late fusion: train separate predictors on individual views and combine them after single-view predictions are available. Existing methods for uncertainty quantification for late fusion often rely on undesirable distributional assumptions for validity. Conformal prediction is one approach that avoids such distributional assumptions. However, naively applying conformal prediction to late-stage fusion pipelines often produces overly conservative and uninformative prediction regions, limiting its downstream utility. We propose a novel methodology, Multi-View Conformal Prediction (MVCP), where conformal prediction is instead performed separately on the single-view predictors and only fused subsequently. Our framework extends the standard scalar formulation of a score function to a multivariate score that produces more efficient downstream prediction regions in both classification and regression settings. We then demonstrate that such improvements can be realized in methods built atop conformalized regressors, specifically in robust predict-then-optimize pipelines.
Conformal Contextual Robust Optimization
Oct 16, 2023



Data-driven approaches to predict-then-optimize decision-making problems seek to mitigate the risk of uncertainty region misspecification in safety-critical settings. Current approaches, however, suffer from considering overly conservative uncertainty regions, often resulting in suboptimal decisionmaking. To this end, we propose Conformal-Predict-Then-Optimize (CPO), a framework for leveraging highly informative, nonconvex conformal prediction regions over high-dimensional spaces based on conditional generative models, which have the desired distribution-free coverage guarantees. Despite guaranteeing robustness, such black-box optimization procedures alone inspire little confidence owing to the lack of explanation of why a particular decision was found to be optimal. We, therefore, augment CPO to additionally provide semantically meaningful visual summaries of the uncertainty regions to give qualitative intuition for the optimal decision. We highlight the CPO framework by demonstrating results on a suite of simulation-based inference benchmark tasks and a vehicle routing task based on probabilistic weather prediction.